Redis
NoSQL
概述
NoSQL(Not-Only SQL):泛指非关系型的数据库,作为关系型数据库的补充
MySQL 支持 ACID 特性,保证可靠性和持久性,读取性能不高,因此需要缓存的来减缓数据库的访问压力
作用:应对基于海量用户和海量数据前提下的数据处理问题
特征:
- 可扩容,可伸缩,SQL 数据关系过于复杂,Nosql 不存关系,只存数据
- 大数据量下高性能,数据不存取在磁盘 IO,存取在内存
- 灵活的数据模型,设计了一些数据存储格式,能保证效率上的提高
- 高可用,集群
常见的 NoSQL:Redis、memcache、HBase、MongoDB
参考书籍:https://book.douban.com/subject/25900156/
参考视频:https://www.bilibili.com/video/BV1CJ411m7Gc
Redis
Redis (REmote DIctionary Server) :�用 C 语言开发的一个开源的高性能键值对(key-value)数据库
特征:
- 数据间没有必然的关联关系,不存关系,只存数据
- 数据存储在内存,存取速度快,解决了磁盘 IO 速度慢的问题
- 内部采用单线程机制进行工作
- 高性能,官方测试数据,50 个并发执行 100000 个请求,读的速度是 110000 次/s,写的速度是 81000 次/s
- 多数据类型支持
- 字符串类型:string(String)
- 列表类型:list(LinkedList)
- 散列类型:hash(HashMap)
- 集合类型:set(HashSet)
- 有序集合类型:zset/sorted_set(TreeSet)
- 支持持久化,可以进行数据灾难恢复
安装启动
安装:
-
Redis 5.0 被包含在默认的 Ubuntu 20.04 软件源中
sudo apt updatesudo apt install redis-server -
检查 Redis 状态
sudo systemctl status redis-server
启动:
-
启动服务器——参数启动
redis-server [--port port]#redis-server --port 6379 -
启动服务器——配置文件启动
redis-server config_file_name#redis-server /etc/redis/conf/redis-6397.conf -
启动客户端:
redis-cli [-h host] [-p port]#redis-cli -h 192.168.2.185 -p 6397注意:服务器启动指定端口使用的是--port,客户端启动指定端口使用的是-p
基本配置
系统目录
-
创建文件结构
创建配置文件存储目录
mkdir conf创建服务器文件存储目录(包含日志、数据、临时配置文件等)
mkdir data -
创建配置文件副本放入 conf 目录,Ubuntu 系统配置文件 redis.conf 在目录
/etc/redis中cat redis.conf | grep -v "#" | grep -v "^$" -> /conf/redis-6379.conf去除配置文件的注释和空格,输出到新的文件,命令方式采用 redis-port.conf
服务器
-
设置服务器以守护进程的方式运行,关闭后服务器控制台中将打印服务器运行信息(同日志内容相同):
daemonize yes|no -
绑定主机地址,绑定本地IP地址,否则SSH无法访问:
bind ip -
设置服务器端口:
port port -
设置服务器文件保存地址:
dir path -
设置数据库的数量:
databases 16 -
多服务器快捷配置:
导入并加载指定配置文件信息,用于快速创建 redis 公共配置较多的 redis 实例配置文件,便于维护
include /path/conf_name.conf
客户端
-
服务器允许客户端连接最大数量,默认 0,表示无限制,当客户端连接到达上限后,Redis 会拒绝新的连接:
maxclients count -
客户端闲置等待最大时长,达到最大值后关闭对应连接,如需关闭该功能,设置为 0:
timeout seconds
日志配置
设置日志记录
-
设置服务器以指定日志记录级别
loglevel debug|verbose|notice|warning -
日志记录文件名
logfile filename
注意:日志级别开发期设置为 verbose 即可,生产环境中配置为 notice,简化日志输出量,降低写日志 IO 的频度
配置文件:
bind 192.168.2.185
port 6379
#timeout 0
daemonize no
logfile /etc/redis/data/redis-6379.log
dir /etc/redis/data
dbfilename "dump-6379.rdb"
基本指令
帮助信息:
-
获取命令帮助文档
help [command]#help set -
获取组中所有命令信息名称
help [@group-name]#help @string
退出服务
-
退出客户端:
quitexit -
退出客户端服务器快捷键:
Ctrl+C
数据库
服务器
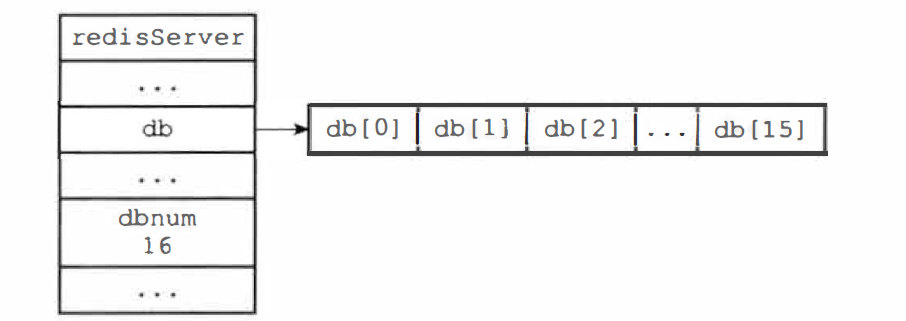
Redis 服务器将所有数据库保存在服务器状态 redisServer 结构的 db 数组中,数组的每一项都是 redisDb 结构,代表一个数据库,每个数据库之间相互独立,**共用 **Redis 内存,不区分大小。在初始化服务器时,根据 dbnum 属性决定创建数据库的数量,该属性由服务器配置的 database 选项决定,默认 16
struct redisServer {
// 保存服务器所有的数据库
redisDB *db;
// 服务器数据库的数量
int dbnum;
};
在服务器内部,客户端状态 redisClient 结构的 db 属性记录了目标数据库,是一个指向 redisDb 结构的指针
struct redisClient {
// 记录客户端正在使用的数据库,指向 redisServer.db 数组中的某一个 db
redisDB *db;
};
每个 Redis 客户端都有目标数据库,执行数据库读写命令时目标数据库就会成为这些命令的操作对象,默认情况下 Redis 客户端的目标数据库为 0 号数据库,客户端可以执行 SELECT 命令切换目标数据库,原理是通过修改 redisClient.db 指针指向服务器中不同数据库
命令操作:
select index #切换数据库,index从0-15取值
move key db #数据移动到指定数据库,db是数据库编号
ping #测试数据库是否连接正常,返回PONG
echo message #控制台输出信息
Redis 没有可以返回客户端目标数据库的命令,但是 redis-cli 客户端旁边会提示当前所使用的目标数据库
redis> SELECT 1
OK
redis[1]>
键空间
key space
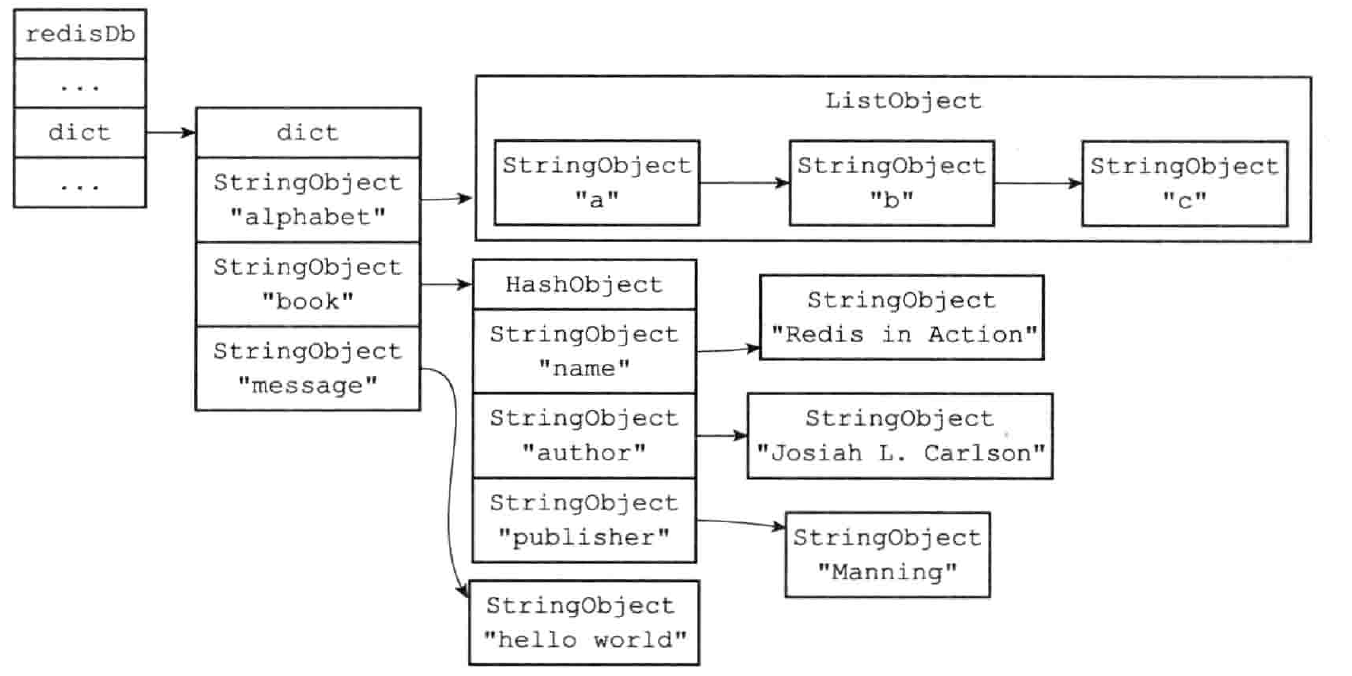
Redis 是一个键值对(key-value pair)数据库服务器,每个数据库都由一个 redisDb 结构表示,redisDb.dict 字典中保存了数据库的所有键值对,将这个字典称为键空间(key space)
typedef struct redisDB {
// 数据库键空间,保存所有键值对
dict *dict
} redisDB;
键空间和用户所见的数据库是直接对应的:
- 键空间的键就是数据库的键,每个键都是一个字符串对象
- 键空间的值就是数据库的值,每个值可以是任意一种 Redis 对象
当使用 Redis 命令对数据库进行读写时,服务器不仅会对键空间执行指定的读写操作,还会进行一些维护操作:
- 在读取一个键后(读操作和写操作都要对键进行读取),服务器会根据键是否存在来更新服务器的键空间命中 hit 次数或键空间不命中 miss 次数,这两个值可以在
INFO stats命令的 keyspace_hits 属性和 keyspace_misses 属性中查看 - 更新键的 LRU(最后使用)时间,该值可以用于计算键的闲置时间,使用
OBJECT idletime key查看键 key 的闲置时间 - 如果在读取一个键时发现该键已经过期,服务器会先删除过期键,再执行其他操作
- 如果客户端使用 WATCH 命令监视了某个键,那么服务器在对被监视的键进行修改之后,会将这个键标记为脏(dirty),从而让事务注意到这个键已经被修改过
- 服务器每次修改一个键之后,都会对 dirty 键计数器的值增1,该计数器会触发服务器的持久化以及复制操作
- 如果服务器开启了数据库通知功能,那么在对键进行修改之后,服务器将按配置发送相应的数据库通知
读写指令
常见键操作指令:
-
增加指令
set key value #添加一个字符串类型的键值对 -
删除指令
del key #删除指定keyunlink key #非阻塞删除key,真正的删除会在后续异步操作 -
更新指令
rename key newkey #改名renamenx key newkey #改名值得更新需要参看具体得 Redis 对象得操作方式,比如字符串对象执行
SET key value就可以完成修改 -
查询指令
exists key #获取key是否存在randomkey #随机返回一个键keys pattern #查询keyKEYS 命令需要遍历存储的键值对,操作延时高,一般不被建议用于生产环境中
查询模式规则:* 匹配任意数量的任意符号、? 配合一个任意符号、[] 匹配一个指定符号
keys * #查询所有keykeys aa* #查询所有以aa开头keys *bb #查询所有以bb结尾keys ??cc #查询所有前面两个字符任意,后面以cc结尾keys user:? #查询所有以user:开头,最后一个字符任意keys u[st]er:1 #查询所有以u开头,以er:1结尾,中间包含一个字母,s或t -
其他指令
type key #获取key的类型dbsize #获取当前数据库的数据总量,即key的个数flushdb #清除当前数据库的所有数据(慎用)flushall #清除所有数据(慎用)在执行 FLUSHDB 这样的危险命令之前,最好先执行一个 SELECT 命令,保证当前所操作的数据库是目标数据库
时效设置
客户端可以以秒或毫秒的精度为数据库中的某个键设置生存时间(TimeTo Live, TTL),在经过指定时间之后,服务器就会自动删除生存时间为 0 的键;也可以以 UNIX 时间戳的方式设置过期时间(expire time),当键的过期时间到达,服务器会自动删除这个键
expire key seconds #为指定key设置生存时间,单位为秒
pexpire key milliseconds #为指定key设置生存时间,单位为毫秒
expireat key timestamp #为指定key设置过期时间,单位为时间戳
pexpireat key mil-timestamp #为指定key设置过期时间,单位为毫秒时间戳
- 实际上 EXPIRE、EXPIRE、EXPIREAT 三个命令底层都是转换为 PEXPIREAT 命令来实现的
- SETEX 命令可以在设置一个字符串键的同时为键设置过期时间,但是该命令是一个类型限定命令
redisDb 结构的 expires 字典保存了数据库中所有键的过期时间,字典称为过期字典:
- 键是一个指针,指向键空间中的某个键对象(复用键空间的对象,不会产生内存浪费)
- 值是一个 long long 类型的整数,保存了键的过期时间,是一个毫秒精度的 UNIX 时间戳
typedef struct redisDB {
// 过期字典,保存所有键的过期时间
dict *expires
} redisDB;
客户端执行 PEXPIREAT 命令,服务器会在数据库的过期字典中关联给定的数据库键和过期时间:
def PEXPIREAT(key, expire_time_in_ms):
# 如果给定的键不存在于键空间,那么不能设置过期时间
if key not in redisDb.dict:
return 0
# 在过期字典中关联键和过期时间
redisDB.expires[key] = expire_time_in_ms
# 过期时间设置成功
return 1
时效状态
TTL 和 PTTL 命令通过计算键的过期时间和当前时间之间的差,返回这个键的剩余生存时间
- 返回正数代表该数据在内��存中还能存活的时间
- 返回 -1 代表永久性,返回 -2 代表键不存在
ttl key #获取key的剩余时间,每次获取会自动变化(减小),类似于倒计时
pttl key #获取key的剩余时间,单位是毫秒,每次获取会自动变化(减小)
PERSIST 是 PEXPIREAT 命令的反操作,在过期字典中查找给定的键,并解除键和值(过期时间)在过期字典中的关联
persist key #切换key从时效性转换为永久性
Redis 通过过期字典可以检查一个给定键是否过期:
- 检查给定键是否存在于过期字典:如果存在,那么取得键的过期时间
- 检查当前 UNIX 时间戳是否大于键的过期时间:如果是那么键已经过期,否则键未过�期
补充:AOF、RDB 和复制功能对过期键的处理
- RDB :
- 生成 RDB 文件,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的 RDB 文件中
- 载入 RDB 文件,如果服务器以主服务器模式运行,那么在载入时会对键进行检查,过期键会被忽略;如果服务器以从服务器模式运行,会载入所有键,包括过期键,但是主从服务器进行数据同步时就会删除这些键
- AOF:
- 写入 AOF 文件,如果数据库中的某个键已经过期,但还没有被删除,那么 AOF 文件不会因为这个过期键而产生任何影响;当该过期键被删除,程序会向 AOF 文件追加一条 DEL 命令,显式的删除该键
- AOF 重写,会对数据库中的键进行检查,忽略已经过期的键
- 复制:当服务器运行在复制模式下时,从服务器的过期键删除动作由主服务器控制
- 主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个 DEL 命令,告知从服务器删除这个过期键
- 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,会当作未过期键处理,只有在接到主服务器发来的 DEL 命令之后,才会删除过期键(数据不一致)
过期删除
删除策略
删除策略就是针对已过期数据的处理策略,已过期的数据不一定被立即删除,在不同的场景下使用不同的删除方式会有不同效果,在内存占用与 CPU 占用之间寻找一种平衡,顾此失彼都会造成整体 Redis 性能的下降,甚至引发服务器宕机或内存泄露
针对过期数据有三种删除策略:
- 定时删除
- 惰性删除(被动删除)
- 定期删除
Redis 采用惰性删除和定期删除策略的结合使用
定时删除
在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间到达时,立即执行对键的删除操作
- 优点:节约内存,到时就删除,快速释放掉不必要的内存占用
- 缺点:对 CPU 不友好,无论 CPU 此时负载多高均占用 CPU,会影响 Redis 服务器响应时间和指令吞吐量
- 总结:用处理器性能换取存储空间(拿时间换空间)
创建一个定时器需要用到 Redis 服务器中的时间事件,而时间事件的实现方式是无序链表,查找一个事件的时间复杂度为 O(N),并不能高效地处理大量时间事件,所以采用这种方式并不现实
惰性删除
数据到达过期时间不做处理,等下次访问到该数据时执行 expireIfNeeded() 判断:
- 如果输入键已经过期,那么 expireIfNeeded 函数将输入键从数据库中删除,接着访问就会返回空
- 如果输入键未过期,那么 expireIfNeeded 函数不做动作
所有的 Redis 读写命令在执行前都会调用 expireIfNeeded 函数进行检查,该函数就像一个过滤器,在命令真正执行之前过滤掉过期键
惰性删除的特点:
- 优点:节约 CPU 性能,删除的目标仅限于当前处理的键,不会在删除其他无关的过期键上花费任何 CPU 时间
- 缺点:内存压力很大,出现长期占用内存的数据,如果过期键永远不被访问,这种情况相当于内存泄漏
- 总结:用存储空间换取处理器性能(拿空间换时间)
定期删除
定期删除策略是每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响
- 如果删除操作执行得太频繁,或者执行时间太长,就会退化成定时删除策略,将 CPU 时间过多地消耗在删除过期键上
- 如果删除操作执行得太少,或者执行时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况
定期删除是周期性轮询 Redis 库中的时效性数据,从过期字典中随机抽取一部分键检查,利用过期数据占比的方式控制删除频度
-
Redis 启动服务器初始化时,读取配置 server.hz 的值,默认为 10,执行指令 info server 可以查看,每秒钟执行 server.hz 次
serverCron() → activeExpireCycle() -
activeExpireCycle() 对某个数据库中的每个 expires 进行检测,工作模式:
-
轮询每个数据库,从数据库中取出一定数量的随机键进行检查,并删除其中的过期键,如果过期 key 的比例超过了 25%,则继续重复此过程,直到过期 key 的比例下降到 25% 以下,或者这次任务的执行耗时超过了 25 毫秒
-
全局变量 current_db 用于记录 activeExpireCycle() 的检查进度(哪一个数据库),下一次调用时接着该进度处理
-
随着函数的不断执行,服务器中的所有数据库都会被检查一遍,这时将 current_db 重置为 0,然后再次开始新一轮的检查
-
定期删除特点:
- CPU 性能占用设置有峰值,检测频度可自定义设置
- 内存压力不是很大,长期占用内存的冷数据会被持续清理
- 周期性抽查存储空间(随机抽查,重点抽查)
数据淘汰
逐出算法
数据淘汰策略:当新数据进入 Redis 时,在执行每一个命令前,会调用 freeMemoryIfNeeded() 检测内存是否充足。如果内存不满足新加入数据的最低存储要求,Redis 要临时删除一些数据为当前指令清理存储空间,清理数据的策略称为逐出算法
逐出数据的过程不是 100% 能够清理出足够的可使用的内存空间,如果不成功则反复执行,当对所有数据尝试完毕,如不能达到内存清理的要求,出现 Redis 内存打满异常:
(error) OOM command not allowed when used memory >'maxmemory'
策略配置
Redis 如果不设置最大内存大小或者设置最大内存大小为 0,在 64 位操作系统下不限制内存大小,在 32 位操作系统默认为 3GB 内存,一般推荐设置 Redis 内存为最大物理内存的四分之三
内存配置方式:
-
通过修改文件配置(永久生效):修改配置文件 maxmemory 字段,单位为字节
-
通过命令修改(重启失效):
-
config set maxmemory 104857600:设置 Redis 最大占用内存为 100MB -
config get maxmemory:获取 Redis 最大占用内存 -
info:可以查看 Redis 内存使用情况,used_memory_human字段表示实际已经占用的内存,maxmemory表示最大占用内存
-
影响数据淘汰的相关配置如下,配置 conf 文件:
-
每次选取待删除数据的个数,采用随机获取数据的方式作为待检测删除数据,防止全库扫描,导致严重的性能消耗,降低读写性能
maxmemory-samples count -
达到最大内存后的,对被挑选出来的数据进行删除的策略
maxmemory-policy policy数据删除的策略 policy:3 类 8 种
第一类:检测易失数据(可能会过期的数据集 server.db[i].expires):
volatile-lru # 对设置了过期时间的 key 选择最近最久未使用使用的数据淘汰volatile-lfu # 对设置了过期时间的 key 选择最近使用次数最少的数据淘汰volatile-ttl # 对设置了过期时间的 key 选择将要过期的数据淘汰volatile-random # 对设置了过期时间的 key 选择任意数据淘汰第二类:检测全库数据(所有数据集 server.db[i].dict ):
allkeys-lru # 对所有 key 选择最近最少使用的数据淘汰allkeLyRs-lfu # 对所有 key 选择最近使用次数最少的数据淘汰allkeys-random # 对所有 key 选择任意数据淘汰,相当于随机第三类:放弃数据驱��逐
no-enviction #禁止驱逐数据(redis4.0中默认策略),会引发OOM(Out Of Memory)
数据淘汰策略配置依据:使用 INFO 命令输出监控信息,查询缓存 hit 和 miss 的次数,根据需求调优 Redis 配置
排序机制
基本介绍
Redis 的 SORT 命令可以对列表键、集合键或者有序集合键的值进行排序,并不更改集合中的数据位置,只是查询
SORT key [ASC/DESC] #对key中数据排序,默认对数字排序,并不更改集合中的数据位置,只是查询
SORT key ALPHA #对key中字母排序,按照字典序
SORT
SORT <key> 命令可以对一个包含数字值的键 key 进行排序
假设 RPUSH numbers 3 1 2,执行 SORT numbers 的详细步骤:
-
创建一个和 key 列表长度相同的数组,数组每项都是 redisSortObject 结构
typedef struct redisSortObject {// 被排序键的值robj *obj;// 权重union {// 排序数字值时使用double score;// 排序带有 BY 选项的字符串robj *cmpobj;} u;} -
遍历数组,将各个数组项的 obj 指针分别指向 numbers 列表的各个项
-
遍历数组,将 obj 指针所指向的列表项转换成一个 double 类型的浮点数,并将浮点数保存在对应数组项的 u.score 属性里
-
根据数组项 u.score 属性的值,对数组进行数字值排序,排序后的数组项按 u.score 属性的值从小到大排列
-
遍历数组,将各个数组项的 obj 指针所指向的值作为排序结果返回给客户端,程序首先访问数组的索引 0,依次向后访问
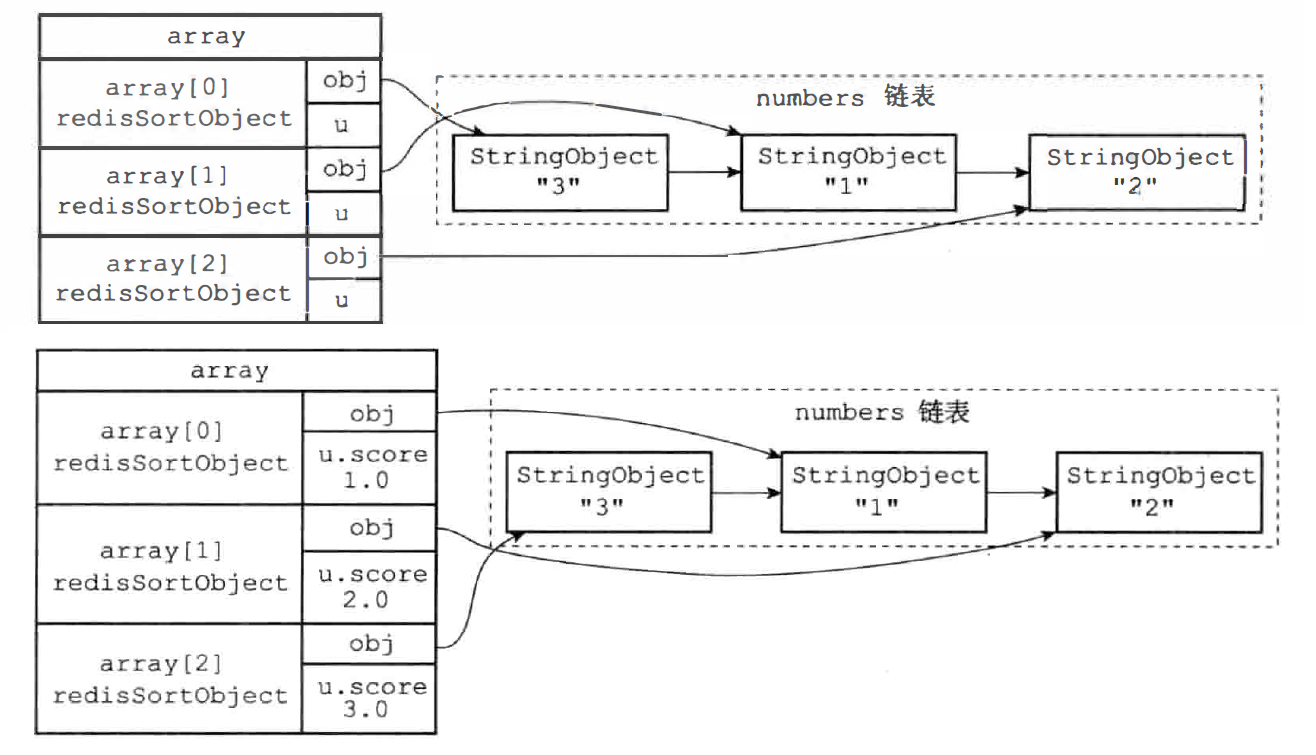
对于 SORT key [ASC/DESC] 函数:
- 在执行升序排序时,排序算法使用的对比函数产生升序对比结果
- 在执行降序排序时,排序算法使用的对比函数产生降序对比结果
BY
SORT 命令默认使用被排序键中包含的元素作为排序的权重,元素本身决定了元素在排序之后所处的位置,通过使用 BY 选项,SORT 命令可以指定某些字符串键,或者某个哈希键所包含的某些域(field)来作为元素的权重,对一个键进行排序
SORT <key> BY <pattern> # 数值
SORT <key> BY <pattern> ALPHA # 字符
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> SORT fruits ALPHA
1) "apple"
2) "banana"
3) "cherry"
redis> MSET apple-price 8 banana-price 5.5 cherry-price 7
OK
# 使用水果的价钱进行排序
redis> SORT fruits BY *-price
1) "banana"
2) "cherry"
3) "apple"
实现原理:排序时的 u.score 属性就会被设置为对应的权重
LIMIT
SORT 命令默认会将排序后的所有元素都返回给客户端,通过 LIMIT 选项可以让 SORT 命令只返回其中一部分已排序的元素
LIMIT <offset> <count>
- offset 参数表示要跳过的已排序元素数量
- count 参数表示跳过给定数量的元素后,要返回的已排序元素数量
# 对应 a b c d e f g
redis> SORT alphabet ALPHA LIMIT 2 3
1) "c"
2) "d"
3) "e"
实现原理:在排序后的 redisSortObject 结构数组中,将指针移动到数组的索引 2 上,依次访问 array[2]、array[3]、array[4] 这 3 个数组项,并将数组项的 obj 指针所指向的元素返回给客户端
GET
SORT 命令默认在对键进行排序后,返回被排序键本身所包含的元素,通过使用 GET 选项, 可以在对键进行排序后,根据被�排序的元素以及 GET 选项所指定的模式,查找并返回某些键的值
SORT <key> GET <pattern>
redis> SADD students "tom" "jack" "sea"
#设置全名
redis> SET tom-name "Tom Li"
OK
redis> SET jack-name "Jack Wang"
OK
redis> SET sea-name "Sea Zhang"
OK
redis> SORT students ALPHA GET *-name
1) "Jack Wang"
2) "Sea Zhang"
3) "Tom Li"
实现原理:对 students 进行排序后,对于 jack 元素和 *-name 模式,查找程序返回键 jack-name,然后获取 jack-name 键对应的值
STORE
SORT 命令默认只向客户端返回排序结果,而不保存排序结果,通过使用 STORE 选项可以将排序结果保存在指定的键里面
SORT <key> STORE <sort_key>
redis> SADD students "tom" "jack" "sea"
(integer) 3
redis> SORT students ALPHA STORE sorted_students
(integer) 3
实现原理:排序后,检查 sorted_students 键是否存在,如果存在就删除该键,设置 sorted_students 为空白的列表键,遍历排序数组将元素依次放入
执行顺序
调用 SORT 命令,除了 GET 选项之外,改变其他选项的摆放顺序并不会影响命令执行选项的顺序
SORT <key> ALPHA [ASC/DESC] BY <by-pattern> LIMIT <offset> <count> GET <get-pattern> STORE <store_key>
执行顺序:
- 排序:命令会使用 ALPHA 、ASC 或 DESC、BY 这几个选项,对输入键进行排序,并得到一个排序结果集
- 限制排序结果集的长度:使用 LIMIT 选项,对排序结果集的长度进行限制
- 获取外部键:根据排序结果集中的元素以及 GET 选项指定的模式,查找并获取指定键的值,并用这些值来作为新的排序结果集
- 保存排序结果集:使用 STORE 选项,将排序结果集保存到指定的键上面去
- 向客户端返回排序结果集:最后一步命令遍历排序结果集,并依次向客户端返回排序结果集中的元素
通知机制
数据库通知是可以让客户端通过订阅给定的频道或者模式,来获知数据库中键的变化,以及数据库中命令的执行情况
- 关注某个键执行了什么命令的通知称为键空间通知(key-space notification)
- 关注某个命令被什么键执行的通知称为键事件通知(key-event notification)
图示订阅 0 号数据库 message 键:

服务器配置的 notify-keyspace-events 选项决定了服务器所发送通知的类型
- AKE 代表服务器发送所有类型的键空间通知和键事件通知
- AK 代表服务器发送所有类型的键空间通知
- AE 代表服务��器发送所有类型的键事件通知
- K$ 代表服务器只发送和字符串键有关的键空间通知
- EL 代表服务器只发送和列表键有关的键事件通知
- .....
发送数据库通知的功能是由 notifyKeyspaceEvent 函数实现的:
- 如果给定的通知类型 type 不是服务器允许发送的通知类型,那么函数会直接返回
- 如果给定的通知是服务器允许发送的通知
- 检测服务器是否允许发送键空间通知,允许就会构建并发送事件通知
- 检测服务器是否允许发送键事件通知,允许就会构建并发送事件通知
体系架构
事件驱动
基本介绍
Redis 服务器是一个事件驱动程序,服务器需要处理两类事件
- 文件事件 (file event):服务器通过套接字与客户端(或其他 Redis 服务器)进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端的通信会产生相应的文件事件,服务器通过监听并处理这些事件完成一系列网络通信操作
- 时间事件 (time event):Redis 服务器中的一些操作(比如 serverCron 函数)需要在指定时间执行,而时间事件就�是服务器对这类定时操作的抽象
文件事件
基本组成
Redis 基于 Reactor 模式开发了网络事件处理器,这个处理器被称为文件事件处理器 (file event handler)
-
使用 I/O 多路复用 (multiplexing) 程序来同时监听多个套接字,并根据套接字执行的任务来为套接字关联不同的事件处理器
-
当被监听的套接字准备好执行连接应答 (accept)、 读取 (read)、 写入 (write)、 关闭 (close) 等操作时,与操作相对应的文件事件就会产生,这时文件事件分派器会调用套接字关联好的事件处理器来处理事件
文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字, 既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,保持了 Redis 内部单线程设计的简单性
文件事件处理器的组成结构:
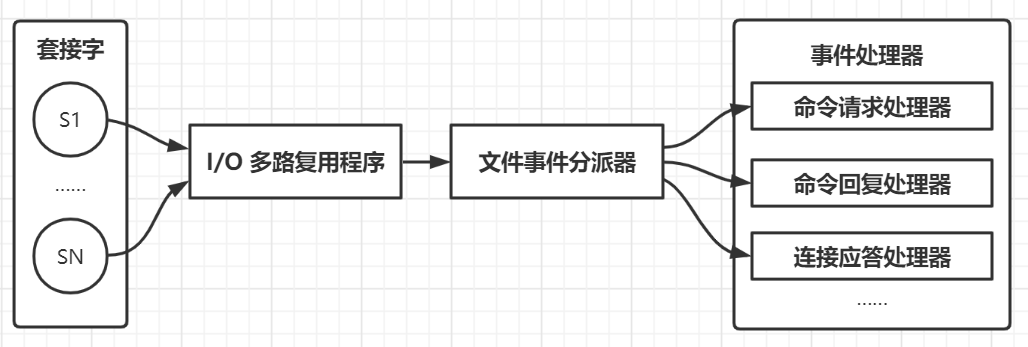
I/O 多路复用程序将所有产生事件的套接字处理请求放入一个单线程的执行队列中,通过队列有序、同步的向文件事件分派器传送套接字,上一个套接字产生的事件处理完后,才会继续向分派器传送下一个

Redis 单线程也能高效的原因:
- 纯内存操作
- 核心是基于非阻塞的 IO 多路复用机制,单线程可以高效处理多个请求
- 底层使用 C 语言实现,C 语言实现的程序距离操作系统更近,执行速度相对会更快
- 单线程同时也避免了多线程的上下文频繁切换问题,预防了多线程可能产生的竞争问题
多路复用
Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select 、epoll、 evport 和 kqueue 这些函数库来实现的,Redis 在 I/O 多路复用程序的实现源码中用 #include 宏定义了相应的规则,编译时自动选择系统中性能最高的多路复用函数来作为底层实现
I/O 多路复用程序监听多个套接字的 AE_READABLE 事件和 AE_WRITABLE 事件,这两类事件和套接字操作之间的对应关系如下:
- 当套接字变得可读时(客户端对套接字执行 write 操作或者 close 操作),或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字执行 connect 连接操作),套接字产生 AE_READABLE 事件
- 当套接字变得可写时(客户端对套接字执行 read 操作,对于服务器来说就是可以写了),套接字产生 AE_WRITABLE 事件
I/O 多路复用程序允许服务器同时监听套接字的 AE_READABLE 和 AE_WRITABLE 事件, 如果一个套接字同时产生了这两种事件,那么文件事件��分派器会优先处理 AE_READABLE 事件, 等 AE_READABLE 事件处理完之后才处理 AE_WRITABLE 事件
处理器
Redis 为文件事件编写了多个处理器,这些事件处理器分别用于实现不同的网络通信需求:
- 连接应答处理器,用于对连接服务器的各个客户端进行应答,Redis 服务器初始化时将该处理器与 AE_READABLE 事件关联
- 命令请求处理器,用于接收客户端传来的命令请求,执行套接字的读入操作,与 AE_READABLE 事件关联
- 命令回复处理器,用于向客户端返回命令的执行结果,执行套接字的写入操作,与 AE_WRITABLE 事件关联
- 复制处理器,当主服务器和从服务器进行复制操作时,主从服务器都需要关联该处理器
Redis 客户端与服务器进行连接并发送命令的整个过程:
- Redis 服务器正在运作监听套接字的 AE_READABLE 事件,关联连接应答处理器
- 当 Redis 客户端向服务器发起连接,监听套接字将产生 AE_READABLE 事件,触发连接应答处理器执行,对客户端的连接请求进行应答,创建客户端套接字以及客户端状态,并将客户端套接字的 AE_READABLE 事件与命令请求处理器进行关联
- 客户端向服务器发送命令请求,客户端套接字产生 AE_READABLE 事件,引发命令请求处理器执行,读取客户端的命令内容传给相关程序去执行
- 执行命令会产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的 AE_WRITABLE 事件与命令回复处理器进行关联
- 当客户端尝试读取命令回复时,客户端套接字产生 AE_WRITABLE 事件,触发命令回复处理器执行,在命令回复全部写入套接字后,服务器就会解除客户端套接字的 AE_WRITABLE 事件与命令回复处理器之间的关联
时间事件
Redis 的时间事件分为以下两类:
- 定时事件:在指定的时间之后执行一次(Redis 中暂时未使用)
- 周期事件:每隔指定时间就执行一次
一个时间事件主要由以下三个属性组成:
- id:服务器为时间事件创建的全局唯一 ID(标识号),从小到大顺序递增,新事件的 ID 比旧事件的 ID 号要大
- when:毫秒精度的 UNIX 时间戳,记录了时间事件的到达(arrive)时间
- timeProc:时间事件处理器,当时间事件到达时,服务器就会调用相应的处理器来处理事件
时间事件是定时事件还是周期性事件取决于时间事件处理器的返回值:
- 定时事件:事件处理器返回 AE_NOMORE,该事件在到达一次后就会被删除
- 周期事件:事件处理器返回非 AE_NOMORE 的整数值,服务器根据该值对事件的 when 属性更新,让该事件在一段时间后再次交付
服务器将所有时间事件都放在一个无序链表中,新的时间事件插入到链表的表头:
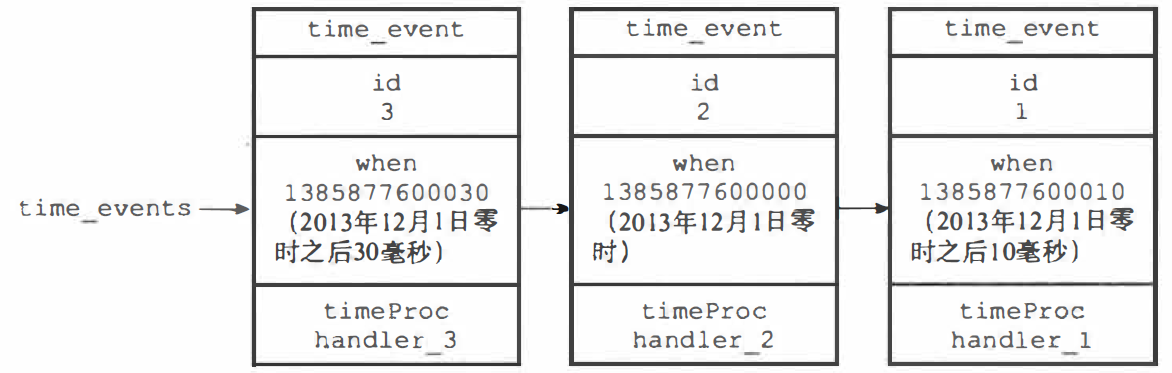
无序链表指是链表不按 when 属性的大小排序,每当时间事件执行器运行时就必须��遍历整个链表,查找所有已到达的时间事件,并调用相应的事件处理器处理
无序链表并不影响时间事件处理器的性能,因为正常模式下的 Redis 服务器只使用 serverCron 一个时间事件,在 benchmark 模式下服务器也只使用两个时间事件,所以无序链表不会影响服务器的性能,几乎可以按照一个指针处理
事件调度
服务器中同时存在文件事件和时间事件两种事件类型,调度伪代码:
# 事件调度伪代码
def aeProcessEvents():
# 获取到达时间离当前时间最接近的时间事件
time_event = aeSearchNearestTime()
# 计算最接近的时间事件距离到达还有多少亳秒
remaind_ms = time_event.when - unix_ts_now()
# 如果事件已到达,那么 remaind_ms 的值可能为负数,设置为 0
if remaind_ms < 0:
remaind_ms = 0
# 根据 remaind_ms 的值,创建 timeval 结构
timeval = create_timeval_with_ms(remaind_ms)
# 【阻塞并等待文件事件】产生,最大阻塞时间由传入的timeval结构决定,remaind_ms的值为0时调用后马上返回,不阻塞
aeApiPoll(timeval)
# 处理所有已产生的文件事件
processFileEvents()
# 处理所有已到达的时间事件
processTimeEvents()
事件的调度和执行规则:
- aeApiPoll 函数的最大阻塞时间由到达时间最接近当前时间的时间事件决定,可以避免服务器对时间事件进行频繁的轮询(忙等待),也可以确保 aeApiPoll 函数不会阻塞过长时间
- 对文件事件和时间事件的处理都是同步、有序、原子地执行,服务器不会中途中断事件处理,也不会对事件进行抢占,所以两种处理器都要尽可地减少程序的阻塞时间,并在有需要时主动让出执行权,从而降低事件饥饿的可能性
- 命令回复处理器在写入字节数超过了某个预设常量,就会主动用 break 跳出写入循环,将余下的数据留到下次再写
- 时间事件也会将非常耗时的持久化操作放到子线程或者子进程执行
- 时间事件在文件事件之后执行,并且事件之间不会出现抢占,所以时间事件的实际处理时间通常会比设定的到达时间稍晚
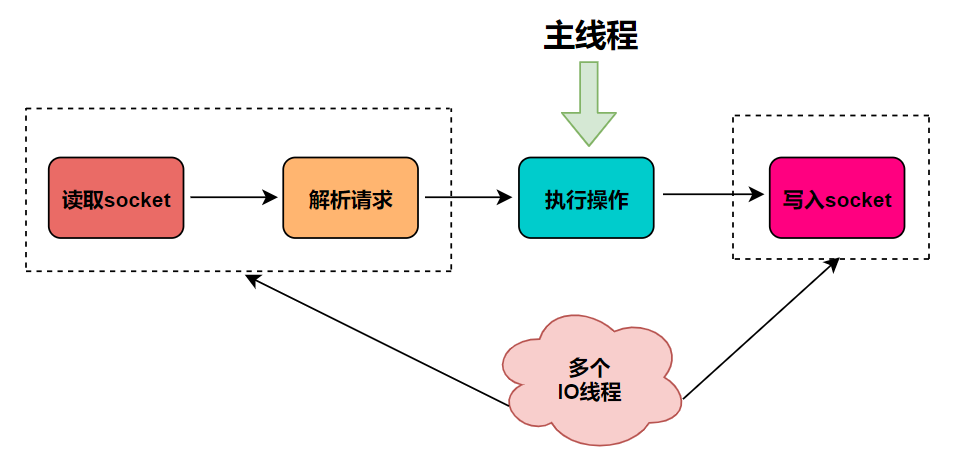
多线程
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这是 Redis 的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络),多线程只是用来处理网络数据的读写和协议解析, 执行命令仍然是单线程顺序执行,因此不需要担心线程安全问题。
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 redis.conf :
io-threads-do-reads yesCopy to clipboardErrorCopied
开启多线程后,还需要设置线程数,否则是不生效的,同样需要修改 redis 配置文件 :
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
参考文章:https://mp.weixin.qq.com/s/dqmiR0ECf4lB6Y2OyK-dyA
客户端
基本介绍
Redis 服务器是典型的一对多程序,一个服务器可以与多个客户端建立网络连接,服务器对每个连接的客户端建立了相应的 redisClient 结构(客户端状态,在服务器端的存储结构),保存了客户端当前的状态信息,以及执行相关功能时需要用到的数据结构
Redis 服务器状态结构的 clients 属性是一个链表,这个链表保存了所有与服务器连接的客户端的状态结构:
struct redisServer {
// 一个链表,保存了所有客户端状态
list *clients;
//...
};

数据结构
redisClient
客户端的数据结构:
typedef struct redisClient {
//...
// 套接字
int fd;
// 名字
robj *name;
// 标志
int flags;
// 输入缓冲区
sds querybuf;
// 输出缓冲区 buf 数组
char buf[REDIS_REPLY_CHUNK_BYTES];
// 记录了 buf 数组目前已使用的字节数量
int bufpos;
// 可变大小的输出缓冲区,链表 + 字符串对象
list *reply;
// 命令数组
rboj **argv;
// 命令数组的长度
int argc;
// 命令的信息
struct redisCommand *cmd;
// 是否通过身份验证
int authenticated;
// 创建客户端的时间
time_t ctime;
// 客户端与服务器最后一次进行交互的时间
time_t lastinteraction;
// 输出缓冲区第一次到达软性限制 (soft limit) 的时间
time_t obuf_soft_limit_reached_time;
}
客户端状态包括两类属性
- 一类是比较通用的属性,这些属性很少与特定功能相关,无论客户端执行的是什么工作,都要用到这些属性
- 另一类是和特定功能相关的属性,比如操作数据库时用到的 db 属性和 dict id 属性,执行事务时用到的 mstate 属性,以及执行 WATCH 命令时用到的 watched_keys 属性等,代码中没有列出
套接字
客户端状态的 fd 属性记录了客户端正在使用的套接字描述符,根据客户端类型的不同,fd 属性的值可以是 -1 或者大于 -1 的整数:
- 伪客户端 (fake client) 的 fd 属性的值为 -1,命令请求来源于 AOF 文件或者 Lua 脚本,而不是网络,所以不需要套接字连接
- 普通客户端的 fd 属性的值为大于 -1 的整数,因为合法的套接字描述符不能是 -1
执行 CLIENT list 命令可以列出目前所有连接到服务器的普通客户端,不包括伪客户端
名字
在默认情况下,一个连接到服务器的客户端是没有名字的,使用 CLIENT setname 命令可以为客户端设置一个名字
标志
客户端的标志属性 flags 记录了客户端的角色以及客户端目前所处的状态,每个标志使用一个常量表示
- flags 的值可以是单个标志:
flags = <flag> - flags 的值可以是多个标志的二进制:
flags = <flagl> | <flag2> | ...
一部分标志记录客户端的角色:
- REDIS_MASTER 表示客户端是一个从服务器,REDIS_SLAVE 表示客户端是一个从服务器,在主从复制时使用
- REDIS_PRE_PSYNC 表示客户端是一个版本低于 Redis2.8 的从服务器,主服务器不能使用 PSYNC 命令与该从服务器进行同步,这个标志只能在 REDIS_ SLAVE 标志处于打开状态时使用
- REDIS_LUA_CLIENT 表示客户端是专门用于处理 Lua 脚本里面包含的 Redis 命令的伪客户端
一部分标志记录目前客户端所处的状态:
- REDIS_UNIX_SOCKET 表示服务器使用 UNIX 套接字来连接客户端
- REDIS_BLOCKED 表示客户端正在被 BRPOP、BLPOP 等命令阻塞
- REDIS_UNBLOCKED 表示客户端已经从 REDIS_BLOCKED 所表示的阻塞状态脱离,在 REDIS_BLOCKED 标志打开的情况下使用
- REDIS_MULTI 标志表示客户端正在执行事务
- REDIS_DIRTY_CAS 表示事务使用 WATCH 命令监视的数据库键已经被修改
- .....
缓冲区
客户端状态的输入缓冲区用于保存客户端发送的命令请求,输入缓冲区的大小会根据输入内容动态地缩小或者扩大,但最大大小不能超过 1GB,否则服务器将关闭这个客户端,比如执行 SET key value ,那么缓冲区 querybuf 的内容:
*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n #
输出缓冲区是服务器用于保存执行客户端命令所得的命令回复,每个客户端都有两个输出缓冲区可用:
- 一个是固定大小的缓冲区,保存长度比较小的回复,比如 OK、简短的字符串值、整数值、错误回复等
- 一个是可变大小的缓冲区,保存那些长度比较大的回复, 比如一个非常长的字符串值或者一个包含了很多元素的集合等
buf 是一个大小为 REDIS_REPLY_CHUNK_BYTES (常量默认 16*1024 = 16KB) 字节的字节数组,bufpos 属性记录了 buf 数组目前已使用的字节数量,当 buf 数组的空间已经用完或者回复数据太大无法放进 buf 数组里,服务器就会开始使用可变大小的缓冲区
通过使用 reply 链表连接多个字符串对象,可以为客户端保存一个非常长的命令回复,而不必受到固定大小缓冲区 16KB 大小的限制

命令
服务器对 querybuf 中的命令请求的内容进行分析,得出的命令参数以及参数的数量分别保存到客户端状态的 argv 和 argc 属性
- argv 属性是一个数组,数组中的每项都是字符串对象,其中 argv[0] 是要执行的命令,而之后的其他项则是命令的参数
- argc 属性负责记录 argv 数组的长度

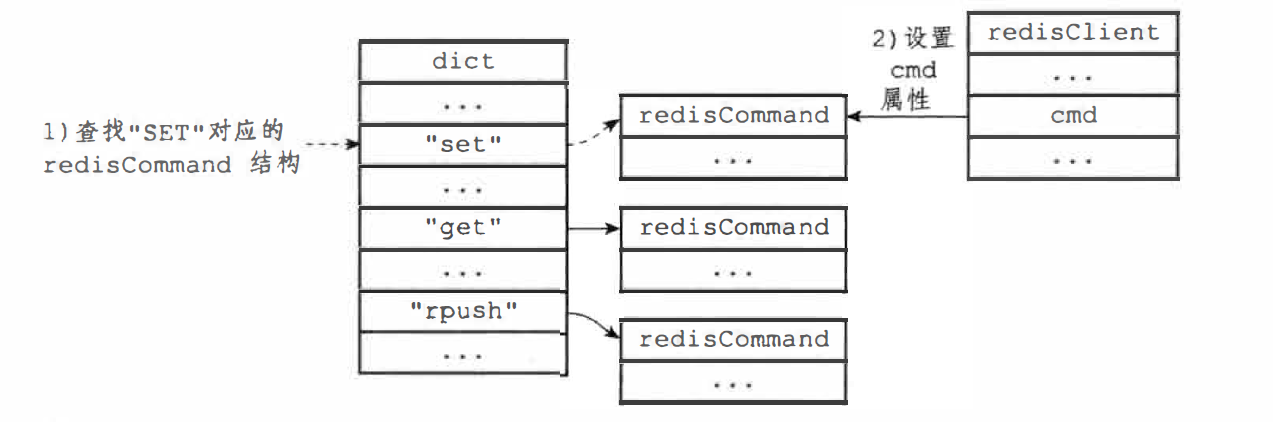
服务器将根据项 argv[0] 的值,在命令表中查找命令所对应的命令的 redisCommand,将客户端状态的 cmd 指向该结构
命令表是一个字典结构,键是 SDS 结构保存命令的名字;值是命令所对应的 redisCommand 结构,保存了命令的实现函数、命令标志、 命令应该给定的参数个数、命令的总执行次数和总消耗时长等统计信息
验证
客户端状态的 authenticated 属性用于记录客户端是否通过了身份验证
- authenticated 值为 0,表示客户端未通过身份验证
- authenticated 值为 1,表示客户端已通过身份验证
当客户端 authenticated = 0 时,除了 AUTH 命令之外, 客户端发送的所有其他命令都会被服务器拒绝执行
redis> PING
(error) NOAUTH Authentication required.
redis> AUTH 123321
OK
redis> PING
PONG
时间
ctime 属性记录了创建客户端的时间,这个时间可以用来计算客户端与服务器已经连接了多少秒,CLIENT list 命令的 age 域记录了这个秒数
lastinteraction 属性记录了客户端与服务器最后一次进行互动 (interaction) 的时间,互动可以是客户端向服务器发送命令请求,也可以是服务器向客户端发送命令回复。该属性可以用来计算客户端的空转 (idle) 时长, 就是距离客户端与服务器最后一次进行互动已经过去了多少秒,CLIENT list 命令的 idle 域记录了这个秒数
obuf_soft_limit_reached_time 属性记录了输出缓冲区第一次到达软性限制 (soft limit) 的时间
生命周期
创建
服务器使用不同的方式来创建和关闭不同类型的客户端
如果客户端是通过网络连接与服务器进行连接的普通客户端,那么在客户端使用 connect 函数连接到服务器时,服务器就会调用连接应答处理器为客户端创建相应的客户端状态,并将这个新的客户端状态添加到服务器状态结构 clients 链表的末尾
服务器会在初始化时创建负责执行 Lua 脚本中包含的 Redis 命令的伪客户端,并将伪客户端关联在服务器状态的 lua_client 属性
struct redisServer {
// 保存伪客户端
redisClient *lua_client;
//...
};
lua_client 伪客户端在服务器运行的整个生命周期会一直存在,只有服务器被关闭时,这个客户端才会被关闭
载入 AOF 文件时, 服务器会创建用于执行 AOF 文件包含的 Redis 命令的伪客户端,并在载入完成之后,关闭这个伪客户端
关闭
一个普通客户端可以因为多种原因而被关闭:
- 客户端进程退出或者被杀死,那么客户端与服务器之间的网络连接将被关闭,从而造成客户端被关闭
- 客户端向服务器发送了带有不符合协议格式的命令请求,那么这个客户端会被服务器关闭
- 客户端是
CLIENT KILL命令的目标 - 如果用户为服务器设置了 timeout 配置选项,那么当客户端的空转时间超过该值时将被关闭,特殊情况不会被关闭:
- 客户端是主服务器(REDIS_MASTER )或者从服务器(打开了 REDIS_SLAVE 标志)
- 正在被 BLPOP 等命令阻塞(REDIS_BLOCKED)
- 正在执�行 SUBSCRIBE、PSUBSCRIBE 等订阅命令
- 客户端发送的命令请求的大小超过了输入缓冲区的限制大小(默认为 1GB)
- 发送给客户端的命令回复的大小超过了输出缓冲区的限制大小
理论上来说,可变缓冲区可以保存任意长的命令回复,但是为了回复过大占用过多的服务器资源,服务器会时刻检查客户端的输出缓冲区的大小,并在缓冲区的大小超出范围时,执行相应的限制操作:
- 硬性限制 (hard limit):输出缓冲区的大小超过了硬性限制所设置的大小,那么服务器会关闭客户端(serverCron 函数中执行),积存在输出缓冲区中的所有内容会被直接释放,不会返回给客户端
- 软性限制 (soft limit):输出缓冲区的大小超过了软性限制所设置的大小,小于硬性限制的大小,服务器的操作:
- 用属性 obuf_soft_limit_reached_time 记录下客户端到达软性限制的起始时间,继续监视客户端
- 如果输出缓冲区的大小一直超出软性限制,并且持续时间超过服务器设定的时长,那么服务器将关闭客户端
- 如果在指定时间内不再超出软性限制,那么客户端就不会被关闭,并且 o_s_l_r_t 属性清零
使用 client-output-buffer-limit 选项可以为普通客户端、从服务器客户端、执行发布与订阅功能的客户端分别设置不同的软性限制和硬性限制,格式:
client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
- 第一行:将普通客户端的硬性限制和软性限制都设置为 0,表示不限制客户端的输出缓冲区大小
- 第二行:将从服务器客户端的硬性限制设置为 256MB,软��性限制设置为 64MB,软性限制的时长为 60 秒
- 第三行:将执行发布与订阅功能的客户端的硬性限制设置为 32MB,软性限制设置为 8MB,软性限制的时长为 60 秒
服务器
执行流程
Redis 服务器与多个客户端建立网络连接,处理客户端发送的命令请求,在数据库中保存客户端执行命令所产生的数据,并通过资源管理来维持服务器自身的运转,所以一个命令请求从发送到获得回复的过程中,客户端和服务器需要完成一系列操作
命令请求
Redis 服务器的命令请求来自 Redis 客户端,当用户在客户端中键入一个命令请求时,客户端会将这个命令请求转换成协议格式,通过连接到服务器的套接字,将协议格式的命令请求发送给服务器
SET KEY VALUE -> # 命令
*3\r\nS3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n # 协议格式
当客户端与服务器之间的连接套接字因为客户端的写入而变得可读,服务器调用命令请求处理器来执行以下操作:
- 读取套接字中协议格式的命令请求,并将其��保存到客户端状态的输入缓冲区里面
- 对输入缓冲区中的命令请求进行分析,提取出命令请求中包含的命令参数以及命令参数的个数,然后分别将参数和参数个数保存到客户端状态的 argv 属性和 argc 属性里
- 调用命令执行器,执行客户端指定的命令
最后客户端接收到协议格式的命令回复之后,会将这些回复转换成用户可读的格式打印给用户观看,至此整体流程结束
命令执行
命令执行器开始对命令操作:
-
查找命令:首先根据客户端状态的 argv[0] 参数,在命令表 (command table) 中查找参数所指定的命令,并将找到的命令保存到客户端状态的 cmd 属性里面,是一个 redisCommand 结构
命令查找算法与字母的大小写无关,所以命令名字的大小写不影响命令表的查找结果
-
执行预备操作:
- 检查客户端状态的 cmd 指针是否指向 NULL,根据 redisCommand 检查请求参数的数量是否正确
- 检查客户端是否通过身份验证
- 如果服务器打开了 maxmemory 功能,执行命令之前要先检查服务器的内存占用,在有需要时进行内存回收(逐出算法)
- 如果服务器上一次执行 BGSAVE 命令出错,并且服务器打开了 stop-writes-on-bgsave-error 功能,那么如果本次执行的是写命令,服务会拒绝执行,并返回错误
- 如果客户端当前正在用 SUBSCRIBE 或 PSUBSCRIBE 命令订阅频道,那么服务器会拒绝除了 SUBSCRIBE、SUBSCRIBE、 UNSUBSCRIBE、PUNSUBSCRIBE 之外的其他命�令
- 如果服务器正在进行载入数据,只有 sflags 带有 1 标识(比如 INFO、SHUTDOWN、PUBLISH等)的命令才会被执行
- 如果服务器执行 Lua 脚本而超时并进入阻塞状态,那么只会执行客户端发来的 SHUTDOWN nosave 和 SCRIPT KILL 命令
- 如果客户端正在执行事务,那么服务器只会执行客户端发来的 EXEC、DISCARD、MULTI、WATCH 四个命令,其他命令都会被放进事务队列中
- 如果服务器打开了监视器功能,那么会将要执行的命令和参数等信息发送给监视器
-
调用命令的实现函数:被调用的函数会执行指定的操作并产生相应的命令回复,回复会被保存在客户端状态的输出缓冲区里面(buf 和 reply 属性),然后实现函数还会为客户端的套接字关联命令回复处理器,这个处理器负责将命令回复返回给客户端
-
执行后续工作:
- 如果服务器开启了慢查询日志功能,那么慢查询日志模块会检查是否需要为刚刚执行完的命令请求添加一条新的慢查询日志
- 根据执行命令所耗费的时长,更新命令的 redisCommand 结构的 milliseconds 属性,并将命令 calls 计数器的值增一
- 如果服务器开启了 AOF 持久化功能,那么 AOF 持久化模块会将执行的命令请求写入到 AOF 缓冲区里面
- 如果有其他从服务器正在复制当前这个服务器,那么服务器会将执行的命令传播给所有从服务器
-
将命令回复发送给客户端:客户端套接字变为可写状态时,服务器就会执行命令回复处理器,将客户端输出缓冲区中的命令回复发送给客户端,发送完毕之后回复处理器会清空客户端状态的输出缓冲区,为处理下一个命令请求做好准备
Command
每个 redisCommand 结构记录了一个Redis 命令的实现信息,主要属性
struct redisCommand {
// 命令的名字,比如"set"
char *name;
// 函数指针,指向命令的实现函数,比如setCommand
// redisCommandProc 类型的定义为 typedef void redisCommandProc(redisClient *c)
redisCommandProc *proc;
// 命令参数的个数,用于检查命令请求的格式是否正确。如果这个值为负数-N, 那么表示参数的数量大于等于N。
// 注意命令的名字本身也是一个参数,比如 SET msg "hello",命令的参数是"SET"、"msg"、"hello" 三个
int arity;
// 字符串形式的标识值,这个值记录了命令的属性,,
// 比如这个命令是写命令还是读命令,这个命令是否允许在载入数据时使用,是否允许在Lua脚本中使用等等
char *sflags;
// 对sflags标识进行分析得出的二进制标识,由程序自动生成。服务器对命令标识进行检查时使用的都是 flags 属性
// 而不是sflags属性,因为对二进制标识的检查可以方便地通过& ^ ~ 等操作来完成
int flags;
// 服务器总共执行了多少次这个命令
long long calls;
// 服务器执行这个命令所耗费的总时长
long long milliseconds;
};
serverCron
基本介绍
Redis 服务器以周期性事件的方式来运行 serverCron 函数,服务器初始化时读取配置 server.hz 的值,默认为 10,代表每秒钟执行 10 次,即每隔 100 毫秒执行一次,执行指令 info server 可以查看
serverCron 函数负责定期对自身的资源和状态进行检查和调整,从而确保服务器可以长期、稳定地运行
- 更新服务器的各类统计信息,比如时间、内存占用、 数据库占用情况等
- 清理数据库中的过期键值对
- 关闭和清理连接失效的客户端
- 进行 AOF 或 RDB 持久化操作
- 如果服务器是主服务器,那么对从服务器进行定期同步
- 如果处于集群模式,对集群进行定期同步和连接测试
时间缓存
Redis 服务器中有很多功能需要获取系统的当前时间,而每次获取系统的当前时间都需要执行一次系统调用,为了减少系统调用的执行次数,服务器状态中的 unixtime 属性和 mstime 属性被用作当前时间的缓存
struct redisServer {
// 保存了秒级精度的系统当前UNIX时间戳
time_t unixtime;
// 保存了毫秒级精度的系统当前UNIX时间戳
long long mstime;
};
serverCron 函数默认以每 100 毫秒一次的频率更新两个属性,所以属性记录的时间的精确度并不高
- 服务器只会在打印日志、更新服务器的 LRU 时钟、决定是否执行持久化任务、计算服务器上线时间(uptime)这类对时间精确度要求不高的功能上
- 对于为键设置过期时间、添加慢查询日志这种需要高精确度时间的功能来说,服务器还是会再次执行系统调用,从而获得最准确的系统当前时间
LRU 时钟
服务器状态中的 lruclock 属性保存了服务器的 LRU 时钟
struct redisServer {
// 默认每10秒更新一次的时钟缓存,用于计算键的空转(idle)时长。
unsigned lruclock:22;
};
每个 Redis 对象都会有一个 lru 属性, 这个 lru 属性保存了对象最后一次被命令访问的时间
typedef struct redisObiect {
unsigned lru:22;
} robj;
当服务器要计算一个数据库键的空转时间(即数据库键对应的值对象的空转时间),程序会用服务器的 lruclock 属性记录的时间减去对象的 lru 属性记录的时间
serverCron 函数默认以每 100 毫秒一次的频率更新这个属性,所以得出的空转时间也是模糊的
命令次数
serverCron 中的 trackOperationsPerSecond 函数以每 100 毫秒一次的频率执行,函数功能是以抽样计算的方式,估算并记录服务器在最近一秒钟处理的命令请求数量,这个值可以通过 INFO status 命令的 instantaneous_ops_per_sec 域查看:
redis> INFO stats
# Stats
instantaneous_ops_per_sec:6
根据上一次抽样时间 ops_sec_last_sample_time 和当前系统时间,以及上一次已执行的命令数 ops_sec_last_sample_ops 和服务器当前已经执行的命令数,计算出两次函数调用期间,服务器平均每毫秒处理了多少个命令请求,该值乘以 1000 得到每秒内的执行命令的估计值,放入 ops_sec_samples 环形数组里
struct redisServer {
// 上一次进行抽样的时间
long long ops_sec_last_sample_time;
// 上一次抽样时,服务器已执行命令的数量
long long ops_sec_last_sample_ops;
// REDIS_OPS_SEC_SAMPLES 大小(默认值为16)的环形数组,数组的每一项记录一次的抽样结果
long long ops_sec_samples[REDIS_OPS_SEC_SAMPLES];
// ops_sec_samples数组的索引值,每次抽样后将值自增一,值为16时重置为0,让数组成为一个环形数组
int ops_sec_idx;
};
内存峰值
服务器状态里的 stat_peak_memory 属性记录了服务器内存峰值大小,循环函数每次执行时都会查看服务器当前使用的内存数量,并与 stat_peak_memory 保存的数值进行比较,设置为较大的值
struct redisServer {
// 已使用内存峰值
size_t stat_peak_memory;
};
INFO memory 命令的 used_memory_peak 和 used_memory_peak_human 两个域分别以两种格式记录了服务器的内存峰值:
redis> INFO memory
# Memory
...
used_memory_peak:501824
used_memory_peak_human:490.06K
SIGTERM
服务器启动时,Redis 会为服务器进程的 SIGTERM 信号关联处理器 sigtermHandler 函数,该信号处理器负责在服务器接到 SIGTERM 信号时,打开服务器状态的 shutdown_asap 标识
struct redisServer {
// 关闭服务器的标识:值为1时关闭服务器,值为0时不做操作
int shutdown_asap;
};
每次 serverCron 函数运行时,程序都会对服务器状态的 shutdown_asap 属性进行检查,并根据属性的值决定是否关闭服务器
服务器在接到 SIGTERM 信号之后,关闭服务器并打印相关日志的过程:
[6794 | signal handler] (1384435690) Received SIGTERM, scheduling shutdown ...
[6794] 14 Nov 21:28:10.108 # User requested shutdown ...
[6794] 14 Nov 21:28:10.108 * Saving the final RDB snapshot before exiting.
[6794) 14 Nov 21:28:10.161 * DB saved on disk
[6794) 14 Nov 21:28:10.161 # Redisis now ready to exit, bye bye ...
管理资源
serverCron 函数每次执行都会调用 clientsCron 和 databasesCron 函数,进行管理客户端资源和数据库资源
clientsCron ��函数对一定数量的客户端进行以下两个检查:
- 如果客户端与服务器之间的连接巳经超时(很长一段时间客户端和服务器都没有互动),那么程序释放这个客户端
- 如果客户端在上一次执行命令请求之后,输入缓冲区的大小超过了一定的长度,那么程序会释放客户端当前的输入缓冲区,并重新创建一个默认大小的输入缓冲区,从而防止客户端的输入缓冲区耗费了过多的内存
databasesCron 函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时对字典进行收缩操作
持久状态
服务器状态中记录执行 BGSAVE 命令和 BGREWRITEAOF 命令的子进程的 ID
struct redisServer {
// 记录执行BGSAVE命令的子进程的ID,如果服务器没有在执行BGSAVE,那么这个属性的值为-1
pid_t rdb_child_pid;
// 记录执行BGREWRITEAOF命令的子进程的ID,如果服务器没有在执行那么这个属性的值为-1
pid_t aof_child_pid
};
serverCron 函数执行时,会检查两个属性的值,只要其中一个属性的值不为 -1,程序就会执行一次 wait3 函数,检查子进程是否有信号发来服务器进程:
- 如果有信号到达,那么表示新的 RDB 文件已经生成或者 AOF 重写完毕,服务器需要进行相应命令的后续操作,比如用新的 RDB 文件替换现有的 RDB 文件,用重写后的 AOF 文件替换现有的 AOF 文件
- 如果没有信号到达,那么表示持久化操作未完成,程序不做动作
如果两个属性的值都为 -1,表示服务器没有进行持久化操作
-
查看是否有 BGREWRITEAOF 被延迟,然后执行 AOF 后台重写
-
查看服务器的自动保存条件是否已经被满足,并且服务器没有在进行持久化,就开始一次新的 BGSAVE 操作
因为条件 1 可能会引发一次 AOF,所以在这个检查中会再次确认服务器是否已经在执行持久化操作
-
检查服务器设置的 AOF 重写条件是否满足,条件满足并且服务器没有进行持久化,就进行一次 AOF 重写
如果服务器开启了 AOF 持久化功能,并且 AOF 缓冲区里还有待写入的数据, 那么 serverCron 函数会调用相应的程序,将 AOF 缓冲区中的内容写入到 AOF 文件里
延迟执行
在服务器执行 BGSAVE 命令的期间,如果客户端发送 BGREWRITEAOF 命令,那么服务器会将 BGREWRITEAOF 命令的执行时间延迟到 BGSAVE 命令执行完毕之后,用服务器状态的 aof_rewrite_scheduled 属性标识延迟与否
struct redisServer {
// 如果值为1,那么表示有 BGREWRITEAOF命令被延迟了
int aof_rewrite_scheduled;
};
serverCron 函数会检查 BGSAVE 或者 BGREWRITEAOF 命令是否正在执行,如果这两个命令都没在执行,并且 aof_rewrite_scheduled 属性的值为 1,那么服务器就会执行之前被推延的 BGREWRITEAOF 命令
执行次数
服务器状态的 cronloops 属性记录了 serverCron 函数执行的次数
struct redisServer {
// serverCron 函数每执行一次,这个属性的值就增 1
int cronloops;
};
缓冲限制
服务器会关闭那些输入或者输出缓冲区大小超出限制的客户端
初始化
初始结构
一个 Redis 服务器从启动到能够接受客户端的命令请求,需要经过一系列的初始化和设置过程
第一步:创建一个 redisServer 类型的实例变量 server 作为服务器的状态,并为结构中的各个属性设置默认值,由 initServerConfig 函数进行初始化一般属性:
- 设置服务器的运行 ID、默认运行频率、默认配置文件路径、默认端口号、默认 RDB 持久化条件和 AOF 持久化条件
- 初始化服务器的 LRU 时钟,创建命令表
第二步:载入配置选项,用户可以通过给定配置参数或者指定配置文件,对 server 变量相关属性的默认值进行修改
第三步:初始化服务器数据结构(除了命令表之外),因为服务器必须先载入用户指定的配置选项才能正确地对数据结构进行初始化,所以载入配置完成后才进性数据结构的初始�化,服务器将调用 initServer 函数:
- server.clients 链表,记录了的客户端的状态结构;server.db 数组,包含了服务器的所有数据库
- 用于保存频道订阅信息的 server.pubsub_channels 字典, 以及保存模式订阅信息的 server.pubsub_patterns 链表
- 用于执行 Lua 脚本的 Lua 环境 server.lua
- 保存慢查询日志的 server.slowlog 属性
initServer 还进行了非常重要的设置操作:
- 为服务器设置进程信号处理器
- 创建共享对象,包含 OK、ERR、整数 1 到 10000 的字符串对象等
- 打开服务器的监听端口
- 为 serverCron 函数创建时间事件, 等待服务器正式运行时执行 serverCron 函数
- 如果 AOF 持久化功能已经打开,那么打开现有的 AOF 文件,如果 AOF 文件不存在,那么创建并打开一个新的 AOF 文件 ,为 AOF 写入做好准备
- 初始化服务器的后台 I/O 模块(BIO), 为将来的 I/O 操作做好准备
当 initServer 函数执行完毕之后, 服务器将用 ASCII 字符在日志中打印出 Redis 的图标, 以及 Redis 的版本号信息
还原状态
在完成了对服务器状态的初始化之后,服务器需要载入RDB文件或者AOF 文件, 并根据文件记录的内容来还原服务器的数据库状态:
- 如果服务器启用了 AOF 持久化功能,那么服务器使用 AOF 文件来还原数据库状态
- 如果服务器没有启用 AOF 持久化功能,那么服务器使用 RDB 文件来还原数据库状态
当服务器完成数据库状态还原工作之后,服务器将在日志中打印出载入文件并还原数据库状态所耗费的时长
[7171] 22 Nov 22:43:49.084 * DB loaded from disk: 0.071 seconds
驱动循环
在初始化的最后一步,服务器将打印出以下日志,并开始执行服务器的事件循环(loop)
[7171] 22 Nov 22:43:49.084 * The server is now ready to accept connections on pert 6379
服务器现在开始可以接受客户端的连接请求,并处理客户端发来的命令请求了
慢日志
基本介绍
Redis 的慢查询日志功能用于记录执行时间超过给定时长的命令请求,通过产生的日志来监视和优化查询速度
服务器配置有两个和慢查询日志相关的选项:
- slowlog-log-slower-than 选项指定执行时间超过多少微秒的命令请求会被记录到日志上
- slowlog-max-len 选项指定服务器最多保存多少条慢查询日志
服务器使用先进先出 FIFO 的方式保存多条慢查询日志,当服务器存储的慢查询日志数量等于 slowlog-max-len 选项的值时,在添加一条新的慢查询日志之前,会先将最旧的一条慢查询日志删除
配置选项可以通过 CONFIG SET option value 命令进行设置
��常用命令:
SLOWLOG GET [n] # 查看 n 条服务器保存的慢日志
SLOWLOG LEN # 查看日志数量
SLOWLOG RESET # 清除所有慢查询日志
日志保存
服务器状态中包含了慢查询日志功能有关的属性:
struct redisServer {
// 下一条慢查询日志的ID
long long slowlog_entry_id;
// 保存了所有慢查询日志的链表
list *slowlog;
// 服务器配置选项的值
long long slowlog-log-slower-than;
// 服务器配置选项的值
unsigned long slowlog_max_len;
}
slowlog_entry_id 属性的初始值为 0,每当创建一条新的慢查询日志时,这个属性就会用作新日志的 id 值,之后该属性增一
slowlog 链表保存了服务器中的所有慢查询日志,链表中的每个节点是一个 slowlogEntry 结构, 代表一条慢查询日志:
typedef struct slowlogEntry {
// 唯一标识符
long long id;
// 命令执行时的时间,格式为UNIX时间戳
time_t time;
// 执行命令消耗的时间,以微秒为单位
long long duration;
// 命令与命令参数
robj **argv;
// 命令与命令参数的数量
int argc;
}
添加日志
在每次执行命令的前后,程序都会记录微秒格式的当前 UNIX 时间戳,两个时间之差就是执行命令所耗费的时长,函数会检查命令的执行时长是否超过 slowlog-log-slower-than 选项所设置:
-
如果是的话,就为命令创建一个新的日志,并将新日志添加到 slowlog 链表的表头
-
检查慢查询日志的长度是否超过 slowlog-max-len 选项所设置的长度,如果是将多出来的日志从 slowlog 链表中删除掉
-
将 redisServer. slowlog_entry_id 的值增 1
数据结构
字符串
SDS
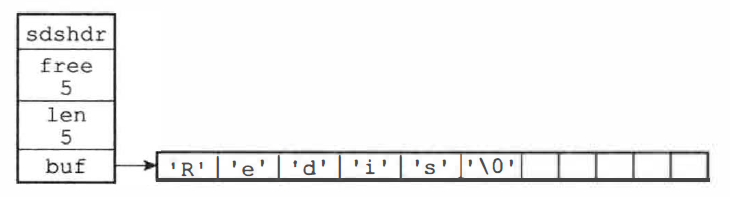
Redis 构建了简单动态字符串(SDS)的数据类型,作为 Redis 的默认字符串表示,包含字符串的键值对在底层都是由 SDS 实现
struct sdshdr {
// 记录buf数组中已使用字节的数量,等于 SDS 所保存字符串的长度
int len;
// 记录buf数组中未使用字节的数量
int free;
// 【字节】数组,用于保存字符串(不是字符数组)
char buf[];
};
SDS 遵循 C 字符串以空字符结尾的惯例,保存空字符的 1 字节不计算在 len 属性,SDS 会自动为空字符分配额外的 1 字节空间和添加空字符到字符串末尾,所以空字符对于 SDS 的使用者来说是完全透明的
对比
常数复杂度获取字符串长度:
- C 字符串不记录自身的长度,获取时需要遍历整个字符串,遇到空字符串为止,时间复杂度为 O(N)
- SDS 获取字符串长度的时间复杂度为 O(1),设置和更新 SDS 长度由函数底层自动完成
杜绝缓冲区溢出:
-
C 字符串调用 strcat 函数拼接字符串时,如果字符串内存不够容纳目标字符串,就会造成缓冲区溢出(Buffer Overflow)
s1 和 s2 是内存中相邻的字符串,执行
strcat(s1, " Cluster")(有空格):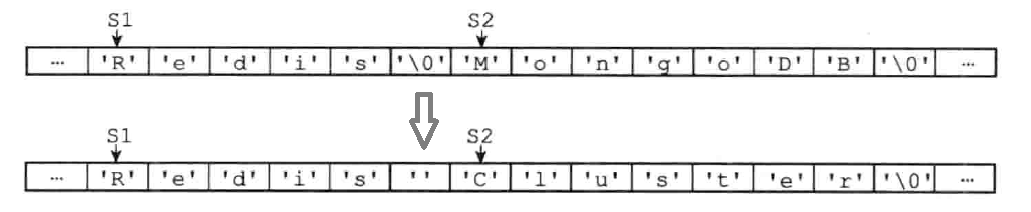
-
SDS 空间分配策略:当对 SDS 进行修改时,首先检查 SDS 的空间是否满足修改所需的要求, 如果不满足会自动将 SDS 的空间扩展至执行修改所需的大小,然后执行实际的修改操作, 避免了缓冲区溢出的问题
二进制安全:
- C 字符串中的字符必须符合某种编码(比如 ASCII)方式,除了字符串末尾以外其他位置不能包含空字符,否则会被误认为是字符串的结尾,所以只能保存文本数据
- SDS 的 API 都是二进制安全的,使用字节数组 buf 保存一系列的二进制数据,使用 len 属性来判断数据的结尾,所以可以保存图片、视频、压缩文件等二进制数据
兼容 C 字符串的函数:SDS 会在为 buf 数组分配空间时多分配一个字节来保存空字符,所以可以重用一部分 C 字符串函数库的函数
内存
C 字符串每次增长或者缩短都会进行一次内存重分配,拼接操作通过重分配扩展底层数组空间,截断操作通过重分配释放不使用的内存空间,防止出现内存泄露
SDS 通过未使用空间解除了字符串长度和底层数组长度之间的关联,在 SDS 中 buf 数组的长度不一定就是字符数量加一, 数组里面可以包含未使用的字节,字节的数量由 free 属性记录
内存重分配涉及复杂的算法,需要执行系统调用,是一个比较耗时的操作,SDS 的两种优化策略:
-
空间预分配:当 SDS 需要进行空间扩展时,程序不仅会为 SDS 分配修改所必需的空间, 还会为 SDS 分配额外的未使用空间
-
对 SDS 修改之后,SDS 的长度(len 属性)小于 1MB,程序分配和 len 属性同样大小的未使用空间,此时 len 和 free 相等
s 为 Redis,执行
sdscat(s, " Cluster")后,len 变为 13 字节,所以也分配了 13 字节的 free 空间,总长度变为 27 字节(额外的一字节保存空字符,13 + 13 + 1 = 27)
-
对 SDS 修改之后,SDS 的长度大于等于 1MB,程序会分配 1MB 的未使用空间
在扩展 SDS 空间前,API 会先检查 free 空间是否足够,如果足够就无需执行内存重分配,所以通过预分配策略,SDS 将连续增长 N 次字符串所需内存的重分配次数从必定 N 次降低为最多 N 次
-
-
惰性空间释放:当 SDS 缩短字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用 free 属性将这些字节的数量记录起来,并等待将来复用
SDS 提供了相应的 API 来真正释放 SDS 的未使用空间,所以不用担心空间惰性释放策略造成的内存浪费问题
链表
链表提供了高效的节点重排能力,C 语言并没有内置这种数据结构,所以 Redis 构建了链表数据类型
链表节点:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value
} listNode;
多个 listNode 通过 prev 和 next 指针组成双端链表:

list 链表结构:提供了表头指针 head 、表尾指针 tail 以及链表长度计数器 len
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数,用于复制链表节点所保存的值
void *(*dup) (void *ptr);
// 节点值释放函数,用于释放链表节点所保存的值
void (*free) (void *ptr);
// 节点值对比函数,用于对比链表节点所保存的值和另一个输入值是否相等
int (*match) (void *ptr, void *key);
} list;
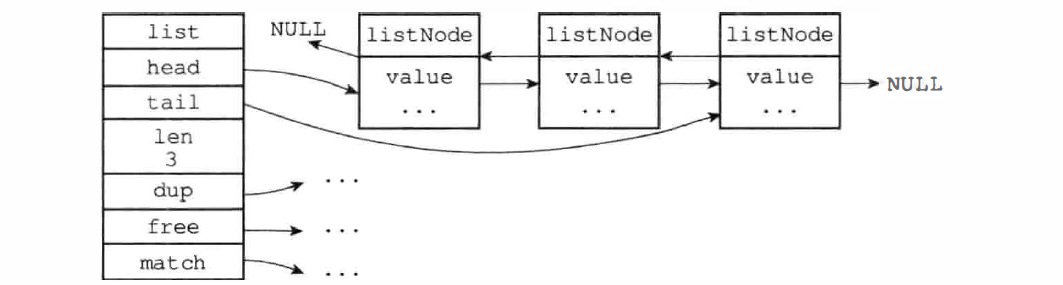
Redis 链表的特性:
- 双端:链表节点带有 prev 和 next 指针,获取某个节点的前置节点和后置节点的时间复杂度都是 O(1)
- 无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以 NULL 为终点
- 带表头指针和表尾指针: 通过 list 结构的 head 指针和 tail 指针,获取链表的表头节点和表尾节点的时间复杂度为 O(1)
- 带链表长度计数器:使用 len 属性来对 list 持有的链表节点进行计数,获取链表中节点数量的时间复杂度为 O(1)
- 多态:链表节点使用 void * 指针来保存节点值, 并且可以通过 dup、free 、match 三个属性为节点值设置类型特定函数,所以链表可以保存各种不同类型的值
字典
哈希表
Redis 字典使用的哈希表结构:
typedef struct dictht {
// 哈希表数组,数组中每个元素指向 dictEntry 结构
dictEntry **table;
// 哈希表大小,数组的长度
unsigned long size;
// 哈希表大小掩码,用于计算索引值,总是等于 【size-1】
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
哈希表节点结构:
typedef struct dictEntry {
// 键
void *key;
// 值,可以是一个指针,或者整数
union {
void *val; // 指针
uint64_t u64;
int64_t s64;
}
// 指向下个哈希表节点,形成链表,用来解决冲突问题
struct dictEntry *next;
} dictEntry;
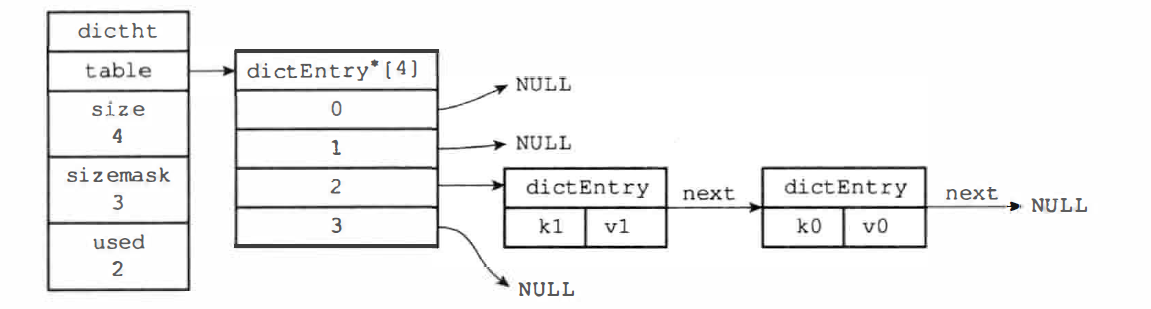
字典结构
字典,又称为符号表、关联数组、映射(Map),用于保存键值对的数据结构,字典中的每个键都是独一无二的。底层采用哈希表实现,一个哈希表包含多个哈希表节点,每个节点保存一个键值对
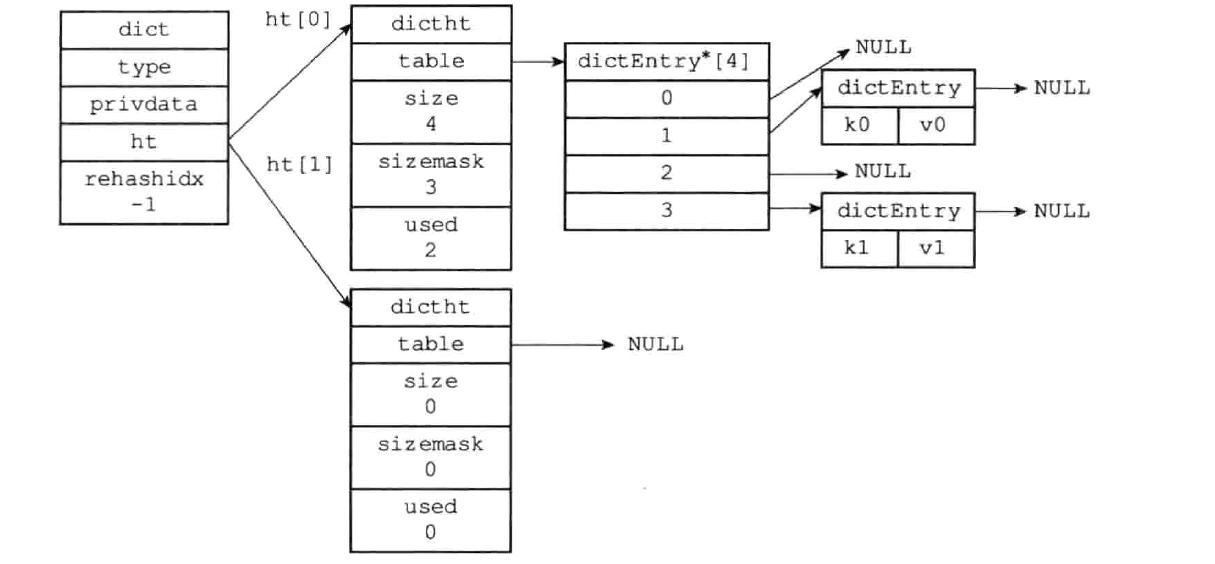
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表,数组中的每个项都是一个dictht哈希表,
// 一般情况下字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用
dictht ht[2];
// rehash 索引,当 rehash 不在进行时,值为 -1
int rehashidx;
} dict;
type 属性和 privdata 属性是针对不同类型的键值对, 为创建多态字典而设置的:
- type 属性是指向 dictType 结构的指针, 每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数
- privdata 属性保存了需要传给那些类型特定函数的可选参数
哈希冲突
Redis 使用 MurmurHash 算法来计算键的哈希值,这种算法的优点在于,即使输入的键是有规律的,算法仍能给出一个很好的随机分布性,并且算法的计算速度也非常快
将一个新的键值对添加到字典里,需要先根据键 key 计算出哈希值,然后进行取模运算(取余):
index = hash & dict->ht[x].sizemask
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上时,就称这些键发生了哈希冲突(collision)
Redis 的哈希表使用链地址法(separate chaining)来解决键哈希冲突, 每个哈希表节点都有一个 next 指针,多个节点通过 next 指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题
dictEntry 节点组成的链表没有指向链表表尾的指针,为了速度考虑,程序总是将新节点添加到链表的表头位置(头插法),时间复杂度为 O(1)
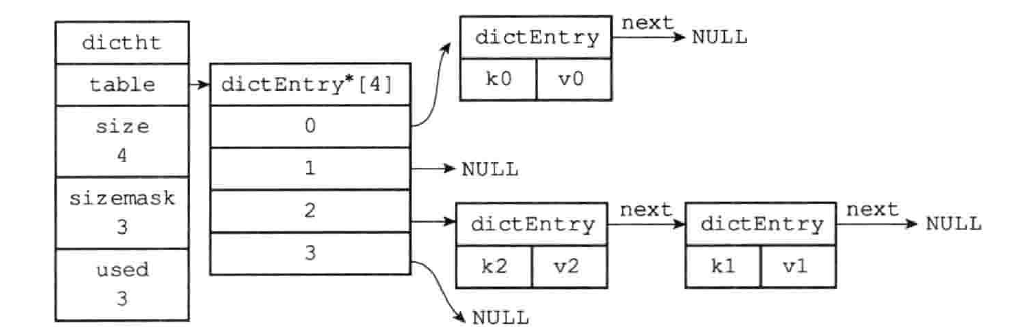
负载因子
负载因子的计算方式:哈希表中的节点数量 / 哈希表�的大小(长度)
load_factor = ht[0].used / ht[0].size
为了让哈希表的负载因子(load factor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时 ,程序会自动对哈希表的大小进行相应的扩展或者收缩
哈希表执行扩容的条件:
-
服务器没有执行 BGSAVE 或者 BGREWRITEAOF 命令,哈希表的负载因子大于等于 1
-
服务器正在执行 BGSAVE 或者 BGREWRITEAOF 命令,哈希表的负载因子大于等于 5
原因:执行该命令的过程中,Redis 需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,通过提高执行扩展操作的负载因子,尽可能地避免在子进程存在�期间进行哈希表扩展操作,可以避免不必要的内存写入操作,最大限度地节约内存
哈希表执行收缩的条件:负载因子小于 0.1(自动执行,servreCron 中检测)
重新散列
扩展和收缩哈希表的操作通过 rehash(重新散列)来完成,步骤如下:
- 为字典的 ht[1] 哈希表分配空间,空间大小的分配情况:
- 如果执行的是扩展操作,ht[1] 的大小为第一个大于等于 $ht[0].used * 2$ 的 $2^n$
- 如果执行的是收缩操作,ht[1] 的大小为第一个大于等于 $ht[0].used$ 的 $2^n$
- 将保存在 ht[0] 中所有的键值对重新计算哈希值和索引值,迁移到 ht[1] 上
- 当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后(ht[0] 变为空表),释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 创建一个新的空白哈希表,为下一次 rehash 做准备
如果哈希表里保存的键值对数量很少,rehash 就可以在瞬间完成,但是如果哈希表里数据很多,那么要一次性将这些键值对全部 rehash 到 ht[1] 需要大量计算,可能会导致服务器在一段时间内停止服务
Redis 对 rehash 做了优化,使 rehash 的动作并不是一次性、集中式的完成,而是分多次,渐进式的完成,又叫渐进式 rehash
- 为 ht[1] 分配空间,此时字典同时持有 ht[0] 和 ht[1] 两个哈希表
- 在字典中维护了一个索引计数器变量 rehashidx,并将变量的值设为 0,表示 rehash 正式开始
- 在 rehash 进行期间,每次对字典执行增删改查操作时,程序除了�执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],rehash 完成之后将 rehashidx 属性的值增一
- 随着字典操作的不断执行,最终在某个时间点 ht[0] 的所有键值对都被 rehash 至 ht[1],将 rehashidx 属性的值设为 -1
渐进式 rehash 采用分而治之的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 带来的庞大计算量
渐进式 rehash 期间的哈希表操作:
- 字典的查找、删除、更新操作会在两个哈希表上进行,比如查找一个键会先在 ht[0] 上查找,查找不到就去 ht[1] 继续查找
- 字典的添加操作会直接在 ht[1] 上添加,不在 ht[0] 上进行任何添加
跳跃表
底层结构
跳跃表(skiplist)是一种有序(默认升序)的数据结构,在链表的基础上增加了多级索引以提升查找的效率,索引是占内存的,所以是一个空间换时间的方案,跳表平均 O(logN)、最坏 O(N) 复杂度的节点查找,效率与平衡树相当但是实现更简单
原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,因此当节点本身比较大或者元素数量比较多的时候,其优势可以被放大,而缺点(占内存)则�可以忽略
Redis 只在两个地方应用了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构
typedef struct zskiplist {
// 表头节点和表尾节点,O(1) 的时间复杂度定位头尾节点
struct skiplistNode *head, *tail;
// 表的长度,也就是表内的节点数量 (表头节点不计算在内)
unsigned long length;
// 表中层数最大的节点的层数 (表头节点的层高不计算在内)
int level
} zskiplist;
typedef struct zskiplistNode {
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
} zskiplistNode;
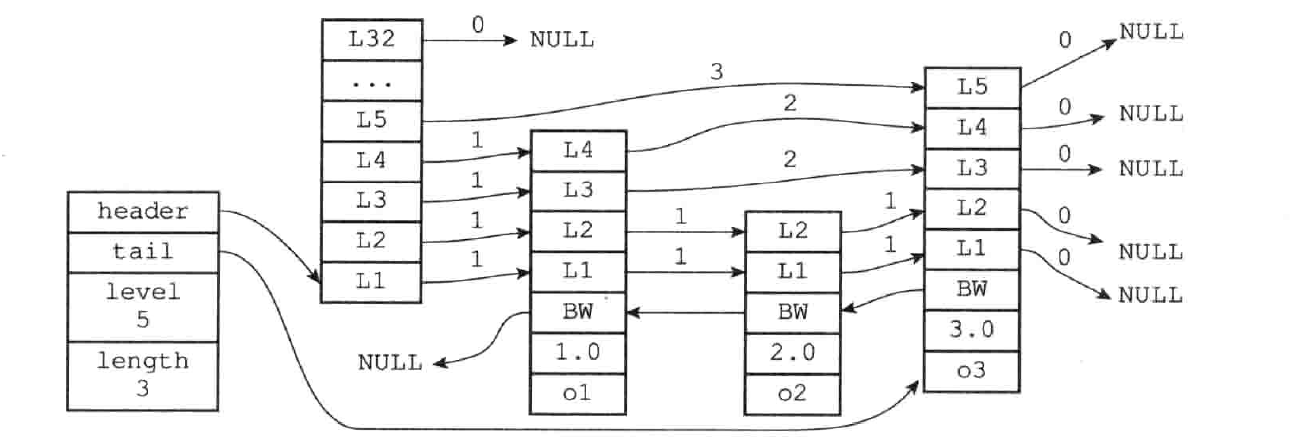
属性分析
层:level 数组包含多个元素,每个元素包含指向其他节点的指针。根据幕次定律(power law,越大的数出现的概率越小)随机生成一个介于 1 和 32 之间的值(Redis5 之后最大为 64)作为 level 数组的大小,这个大小就是层的高度,节点的第一层是 level[0] = L1
前进指针:forward 用于从表头到表尾方向正序(升序)遍历节点,遇到 NULL 停止遍历
跨度:span 用于记录两个节点之间的距离,用来计算排位(rank):
-
两个节点之间的跨度越大相距的就越远,指向 NULL 的所有前进指针的跨度都为 0
-
在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,结果就是目标节点在跳跃表中的排位,按照上图所示:
查找分值为 3.0 的节点,沿途经历的层:查找的过程只经过了一个层,并且层的跨度为 3,所以目标节点在跳跃表中的排位为 3
查找分值为 2.0 的节点,沿途经历的层:经过了两个跨度为 1 的节点,因此可以计算出目标节点在跳跃表中的排位为 2
后退指针:backward 用于从表尾到表头方向逆序(降序)遍历节点
分值:score 属性一个 double 类型的浮点数,跳跃表中的所有节点都按分值从小到大来排序
成员对象:obj 属性是一个指针,指向一个 SDS 字符串对象。同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值可以是相同的,分值相同的节点将按照成员对象在字典序中的大小来进行排序(从小到大)
个人笔记:JUC → 并发包 → ConcurrentSkipListMap 详解跳跃表
整数集合
底层结构
整数集合(intset)是用于保存整数值的集合数据结构,是 Redis 集合键的底层实现之一
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量,也就是 contents 数组的长度
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64
整数集合的每个元素都是 contents 数组的一个数组项(item),在数组中按值的大小从小到大有序排列,并且数组中不包含任何重复项。虽然 contents 属性声明为 int8_t 类型,但实际上数组并不保存任何 int8_t 类型的值, 真正类型取决于 encoding 属性
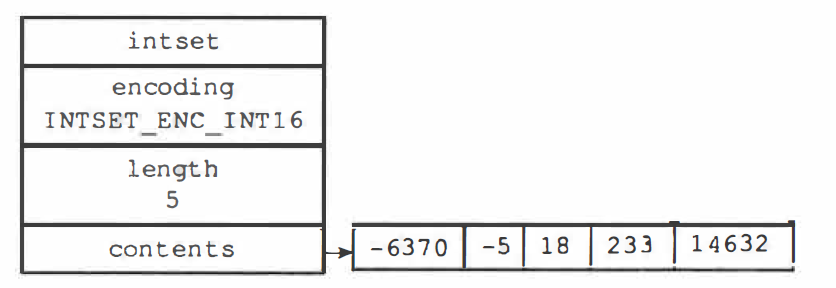
说明:底层存储结构是数组,所以为了保证有序性和不重复性,每次添加一个元素的时间复杂度是 O(N)
类型升级
整数集合添加的新元素的类型比集合现有所有元素的类型都要长时,需要先进行升级(upgrade),升级流程:
-
根据新元素的类型长度以及集合元素的数量(包括新元素在内),扩展整数集合底层数组的空间大小
-
将底层数组现有的所有元素都转换成与新元素相同的类型,并将转换后的元素放入正确的位置,放置过程保证数组的有序性
图示 32 * 4 = 128 位,首先将 3 放入索引 2(64 位 - 95 位),然后将 2 放置索引 1,将 1 放置在索引 0,从后向前依次放置在对应的区间,最后放置 65535 元素到索引 3(96 位- 127 位),修改 length 属性为 4
-
将新元素添加到底层数组里
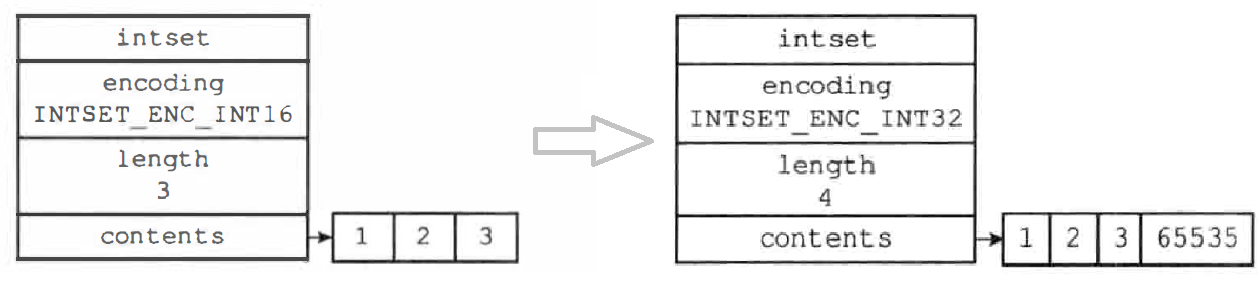
每次向整数集合添加新元素都可能会引起升级,而每次升级都需要对底层数组中的所有元素进行类型转换,所以向整数集合添加新元素的时间复杂度为 O(N)
引发升级的新元素的长度总是比整数集合现有所有元素的长度都大,所以这个新元素的值要么就大于所有现有元素,要么就小于所有现有元素,升级之后新元素的摆放位置:
- 在新元素小于所有现有元素的情况下,新元素会被放置在底层数组的最开头(索引 0)
- 在新元素大于所有现有元素的情况下,新元素会被放置在底层数组的最末尾(索引 length-1)
整数集合升级策略的优点:
-
提升整数集合的灵活性:C 语言是静态类型语言,为了避免类型错误通常不会将两种不同类型的值放在同一个数据结构里面,整数集合可以自动升级底层数组来适应新元素,所以可以随意的添加整数
-
节约内存:要让数组可以同时保存 int16、int32、int64 三种类型的值,可以直接使用 int64_t 类型的数组作为整数集合的底层实现,但是会造成内存浪费,整数集合可以确保升级操作只会在有需要的时候进行,尽量节省内存
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态
压缩列表
底层结构
压缩列表(ziplist)是 Redis 为了节约内存而开发的,是列表键和哈希键的底层实现之一。是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值

- zlbytes:uint32_t 类型 4 字节,记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分配或者计算 zlend 的位置时使用
- zltail:uint32_t 类型 4 字节,记录压缩列表表尾节点距离起始地址有多少字节,通过这个偏移量程序无须遍历整个压缩列表就可以确定表尾节点的地址
- zllen:uint16_t 类型 2 字节,记录了压缩列表包含的节点数量,当该属性的值小于 UINT16_MAX (65535) 时,该值就是压缩列表中节点的数量;当这个值等于 UINT16_MAX 时节点的真实数量需要遍历整个压缩列表才能计算得出
- entryX:列表节点,压缩列表中的各个节点,节点的长度由节点保存的内容决定
- zlend:uint8_t 类型 1 字节,是一个特殊值 0xFF (255),用于标记压缩列表的末端

列表 zlbytes 属性的值为 0x50 (十进制 80),表示压缩列表的总长为 80 字节,列表 zltail 属性的值为 0x3c (十进制 60),假设��表的起始地址为 p,计算得出表尾节点 entry3 的地址 p + 60
列表节点
列表节点 entry 的数据结构:

previous_entry_length:以字节为单位记录了压缩列表中前一个节点的长度,程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址,完成从表尾向表头遍历操作
- 如果前一节点的长度小于 254 字节,该属性的长度为 1 字节,前一节点的长度就保存在这一个字节里
- 如果前一节点的长度大于等于 254 字节,该属性的长度为 5 字节,其中第一字节会被设置为 0xFE(十进制 254),之后的四个字节则用于保存前一节点的长度
encoding:记录了节点的 content 属性所保存的数据类型和长度
-
长度为 1 字节、2 字节或者 5 字节,值的最高位为 00、01 或者 10 的是字节数组编码,数组的长度由编码除去最高两位之后的其他位记录,下划线
_表示留空,而b、x等变量则代表实际的二进制数据
-
长度为 1 字节,值的最高位为 11 的是整数编码,整数值的类型和长度由编码除去最高两位之后的其他位记录

content:每个压缩列表节点可以保存一个字节数组或者一个整数值
-
字节数组可以是以下三种长度的其中一种:
-
长度小于等于 $63 (2^6-1)$ 字节的字节数组
-
长度小于等于 $16383(2^14-1)$ 字节的字节数组
-
长度小于等于 $4294967295(2^32-1)$ 字节的字节数组
-
-
整数值则可以是以下六种长度的其中一种:
-
4 位长,介于 0 至 12 之间的无符号整数
-
1 字节长的有符号整数
-
3 字节长的有符号整数
-
int16_t 类型整数
-
int32_t 类型整数
-
int64_t 类型整数
-
连锁更新
Redis 将在特殊情况下产生的连续多次空间扩展操作称之为连锁更新(cascade update)
假设在一个压缩列表中,有多个连续的、长度介于 250 到 253 字节之间的节点 e1 至 eN。将一个长度大于等于 254 字节的新节点 new 设置为压缩列表的头节点,new 就成为 e1 的前置节点。e1 的 previous_entry_length 属性仅为 1 字节,无法保存新节点 new 的长度,所以要对压缩列表执行空间重分配操作,并将 e1 节点的 previous_entry_length 属性从 1 字节长扩展为 5 字节长。由于 e1 原本的长度介于 250 至 253 字节之间,所以扩展后 e1 的长度就变成了 254 至 257 字节之间,导致 e2 的 previous_entry_length 属性无法保存 e1 的长度,程序需要不断地对压缩列表执行空间重分配操作,直到 eN 为止
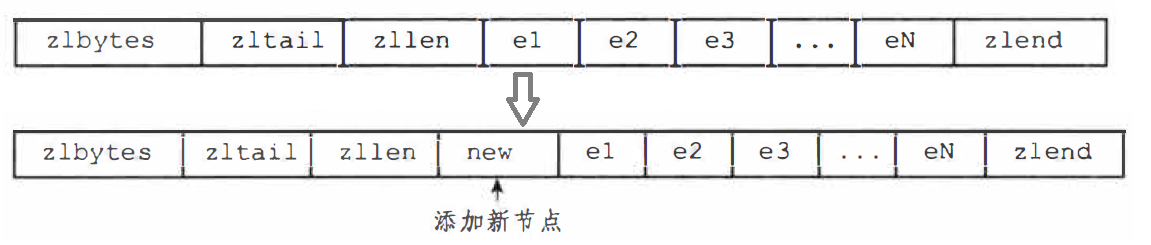
删除节点也可能会引发连锁更新,big.length >= 254,small.length < 254,删除 small 节点

连锁更新在最坏情况下需要对压缩列表执行 N 次空间重分配,每次重分配的最坏复杂度为 O(N),所以连锁更新的最坏复杂度为 O(N^2)
说明:尽管连锁更新的复杂度较高,但出现的记录是非常低的,即使出现只要被更新的节点数量不多,就不会对性能造成影响
数据类型
redisObj
对象系统
Redis 使用对象来表示数据库中的键和值,当在 Redis 数据库中新创建一个键值对时至少会创建两个对象,一个对象用作键值对的键(键对象),另一个对象用作键值对的值(值对象)
Redis 中对象由一个 redisObject 结构表示,该结构中和保存数据��有关的三个属性分别是 type、 encoding、ptr:
typedef struct redisObiect {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层数据结构的指针
void *ptr;
// ....
} robj;
Redis 并没有直接使用数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,而每种对象又通过不同的编码映射到不同的底层数据结构
Redis 是一个 Map 类型,其中所有的数据都是采用 key : value 的形式存储,键对象都是字符串对象,而值对象有五种基本类型和三种高级类型对象
- 对一个数据库键执行 TYPE 命令,返回的结果为数据库键对应的值对象的类型,而不是键对象的类型
- 对一个数据库键执行 OBJECT ENCODING 命令,查看数据库键对应的值对象的编码
命令多态
Redis 中用于操作键的命令分为两种类型:
- 一种命令可以对任何类型的键执行,比如说 DEL 、EXPIRE、RENAME、 TYPE 等(基于类型的多态)
- 只能对特定类型的键执行,比如 SET 只能对字符串键执行、HSET 对哈希键执行、SADD 对集合键执行,如果类型步匹配会报类型错误:
(error) WRONGTYPE Operation against a key holding the wrong kind of value
Redis 为了确保只有指定类型的键可以执行某些特定的命令,在执行类型特定的命令之前,先通过值对象 redisObject 结构 type 属性检查操作类型是否正确,然后再决定是否执行指定的命令
对于多态命令,比如列表对象有 ziplist 和 linkedlist 两种实现方式,通过 redisObject 结构 encoding 属性确定具体的编码类型,底层调用对应的 API 实现具体的操作(基于编码的多态)
内存回收
对象的整个生命周期可以划分为创建对象、 操作对象、 释放对象三个阶段
C 语言没有自动回收内存的功能,所以 Redis 在对象系统中构建了引用计数(reference counting)技术实现的内存回收机制,程序可以跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收
typedef struct redisObiect {
// 引用计数
int refcount;
} robj;
对象的引用计数信息会随着对象的使用状态而不断变化,创建时引用计数 refcount 初始化为 1,每次被一个新程序使用时引用计数加 1,当对象不再被一个程序使用时引用计数值会被减 1,当对象的引用计数值变为 0 时,对象所占用的内存会被释放
对象共享
对象的引用计数�属性带有对象共享的作用,共享对象机制更节约内存,数据库中保存的相同值对象越多,节约的内存就越多
让多个键共享一个对象的步骤:
-
将数据库键的值指针指向一个现有的值对象
-
将被共享的值对象的引用计数增一

Redis 在初始化服务器时创建一万个(配置文件可以修改)字符串对象,包含了从 0 到 9999 的所有整数值,当服务器需要用到值为 0 到 9999 的字符串对象时,服务器就会使用这些共享对象,而不是新创建对象
比如创建一个值为 100 的键 A,并使用 OBJECT REFCOUNT 命令查看键 A 的值对象的引用计数,会发现值对象的引用计数为 2,引用这个值对象的两个程序分别是持有这个值对象的服务器程序,以及共享这个值对象的键 A
共享对象在嵌套了字符串对象的对象(linkedlist 编码的列表、hashtable 编码的哈希、zset 编码的有序集合)中也能使用
Redis 不共享包含字符串对象的原因:验证共享对象和目标对象是否相同的复杂度越高,消耗的 CPU 时间也会越多
- 整数值的字符串对象, 验证操作的复杂度为 O(1)
- 字符串值的字符串对象, 验证操作的复杂度为 O(N)
- 如果共享对象是包含了多个值(或者对象的)对象,比如列表对象或者哈希对象,验证操作的复杂度为 O(N^2)
空转时长
redisObject 结构包含��一个 lru 属性,该属性记录了对象最后一次被命令程序访问的时间
typedef struct redisObiect {
unsigned lru:22;
} robj;
OBJECT IDLETIME 命令可以打印出给定键的空转时长,该值就是通过将当前时间减去键的值对象的 lru 时间计算得出的,这个命令在访问键的值对象时,不会修改值对象的 lru 属性
redis> OBJECT IDLETIME msg
(integer) 10
# 等待一分钟
redis> OBJECT IDLETIME msg
(integer) 70
# 访问 msg
redis> GET msg
"hello world"
# 键处于活跃状态,空转时长为 0
redis> OBJECT IDLETIME msg
(integer) 0
空转时长的作用:如果服务器开启 maxmemory 选项,并且回收内存的算法为 volatile-lru 或者 allkeys-lru,那么当服务器占用的内存数超过了 maxmemory 所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存(LRU 算法)
string
简介
存储的数据:单个数据,最简单的数据存储类型,也是最常用的数据存储类型,实质上是存一个字符串,string 类型是二进制安全的,可以包含任何数据,比如图片或者序列化的对象
存储数据的格式:一个存储空间保存一个数据,每一个空间中只能保存一个字符串信息
存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用
Redis 所有操作都是原子性的,采用单线程机制,命令是单个顺序执行,无需考虑并发带来影响,原子性就是有一个失败则都失败
字符串对象可以是 int、raw、embstr 三种实现方式
操作
指令操作:
-
数据操作:
set key value #添加/修改数据添加/修改数据del key #删除数据setnx key value #判定性添加数据,键值为空则设添加mset k1 v1 k2 v2... #添加/修改多个数据,m:Multipleappend key value #追加信息到原始信息后部(如果原始信息存在就追加,否则新建) -
查询操作
get key #获取数据,如果不存在,返回空(nil)mget key1 key2... #获取多个数据strlen key #获取数据字符个数(字符串长度) -
设置数值数据增加/减少指定范围的值
incr key #key++incrby key increment #key+incrementincrbyfloat key increment #对小数操作decr key #key--decrby key increment #key-increment -
设置数据具有指定的生命周期
setex key seconds value #设置key-value存活时间,seconds单位是秒psetex key milliseconds value #毫秒级
注意事项:
-
数据操作不成功的反馈与数据正常操作之间的差异
-
表示运行结果是否成功
-
(integer) 0 → false ,失败
-
(integer) 1 → true,成功
-
-
表示运行结果值
-
(integer) 3 → 3 个
-
(integer) 1 → 1 个
-
-
-
数据未获取到时,对应的数据为(nil),等同于null
-
数据最大存储量:512MB
-
string 在 Redis 内部存储默认就是一个字符串,当遇到增减类操作 incr,decr 时会转成数值型进行计算
-
按数值进行操作的数据,如果原始数据不能转成数值,或超越了Redis 数值上限范围,将报错 9223372036854775807(java 中 Long 型数据最大值,Long.MAX_VALUE)
-
Redis 可用于控制数据库表主键 ID,为数据库表主键提供生成策略,保障数据库表的主键唯一性
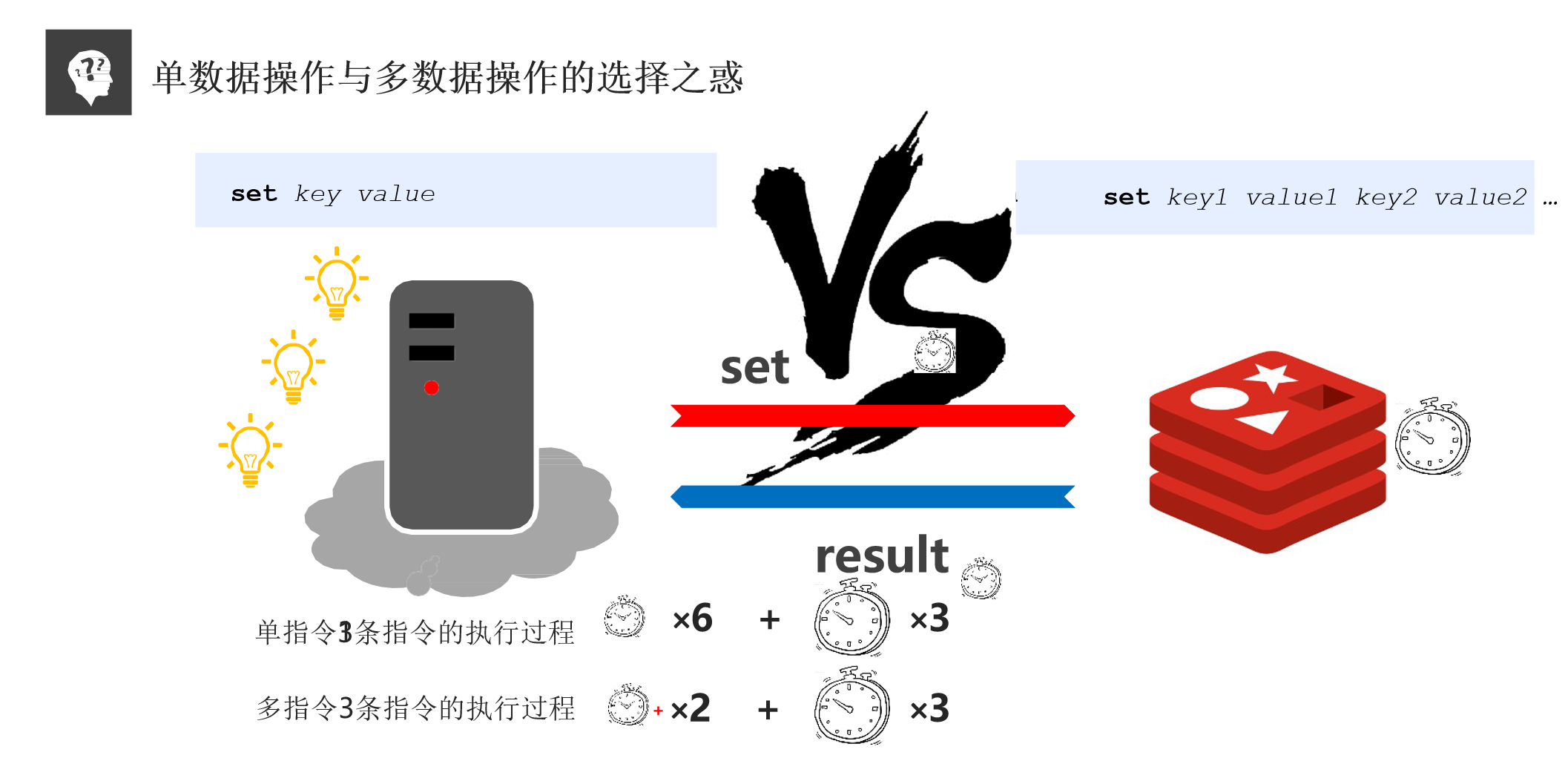
单数据和多数据的选择:
- 单数据执行 3 条指令的过程:3 次发送 + 3 次处理 + 3 次返回
- 多数据执行 1 条指令的过程:1 次发送 + 3 次处理 + 1 次返回(发送和返回的事件略高于单数据)
实现
字符串对象的编码可以是 int、raw、embstr 三种
-
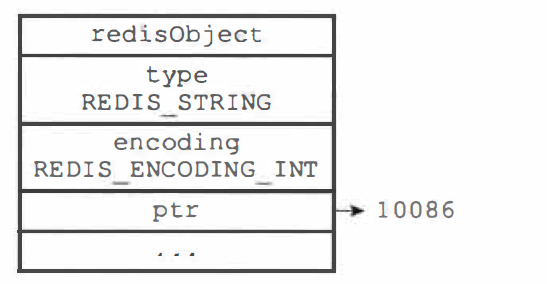
int:字符串对象保存��的是整数值,并且整数值可以用 long 类型来表示,那么对象会将整数值保存在字符串对象结构的 ptr 属性面(将 void * 转换成 long),并将字符串对象的编码设置为 int(浮点数用另外两种方式)
-
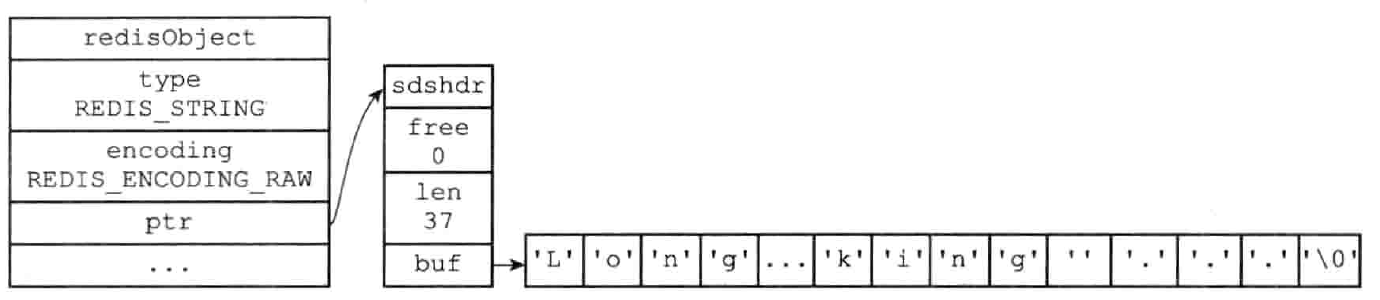
raw:字符串对象保存的是一个字符串值,并且值的长度大于 39 字节,那么对象将使用简单动态字符串(SDS)来保存该值,并将对象的编码设置为 raw
-
embstr:字符串对象保存的是一个字符串值,并且值的长度小于等于 39 字节,那么对象将使用 embstr 编码的方式来保存这个字符串值,并将对象的编码设置为 embstr

上图所示,embstr 与 raw 都使用了 redisObject 和 sdshdr 来表示字符串对象,但是 raw 需要调用两次内存分配函数分别创建两种结构,embstr 只需要一次内存分配来分配一块连续的空间
embstr 是用于保存短字符串的一种编码方式,对比 raw 的优点:
- 内存分配次数从两次降低为一次,同样释放内存的次数也从两次变为一次
- embstr 编码的字符串对象的数据都保存在同一块连续内存,所以比 raw 编码能够更好地利用缓存优势(局部性原理)
int 和 embstr 编码的字符串对象在条件满足的情况下,��会被转换为 raw 编码的字符串对象:
- int 编码的整数值,执行 APPEND 命令追加一个字符串值,先将整数值转为字符串然后追加,最后得到一个 raw 编码的对象
- Redis 没有为 embstr 编码的字符串对象编写任何相应的修改程序,所以 embstr 对象实际上是只读的,执行修改命令会将对象的编码从 embstr 转换成 raw,操作完成后得到一个 raw 编码的对象
某些情况下,程序会将字符串对象里面的字符串值转换回浮点数值,执行某些操作后再将浮点数值转换回字符串值:
redis> SET pi 3.14
OK
redis> OBJECT ENCODING pi
"embstr"
redis> INCRBYFLOAT pi 2.0 # 转为浮点数执行增加的操作
"5. 14"
redis> OBJECT ENCODING pi
"embstr"
应用
主页高频访问信息显示控制,例如新浪微博大 V 主页显示粉丝数与微博数量
-
在 Redis 中为大 V 用户设定用户信息,以用户主键和属性值作为 key,后台设定定时刷新策略
set user:id:3506728370:fans 12210947set user:id:3506728370:blogs 6164set user:id:3506728370:focuses 83 -
使用 JSON 格式保存数据
user:id:3506728370 → {"fans":12210947,"blogs":6164,"focuses":83} -
key的设置约定:表名 : 主键名 : 主键值 : 字段名
表名 主键名 主键值 字段名 order id 29437595 name equip id 390472345 type news id 202004150 title
hash
简介
数据存储需求:对一系列存储的数据进行编组,方便管理,典型应用存储对象信息
数据存储结构:一个存储空间保存多个键值对数据
hash 类型:底层使用哈希表结构实现数据存储
Redis 中的 hash 类似于 Java 中的 Map<String, Map<Object,object>>,左边是 key,右边是值,中间叫 field 字段,本质上 hash 存了一个 key-value 的存储空间
hash 是指的一个数据类型,并不是一个数据
- 如果 field 数量较少,存储结构优化为压缩列表结构(有序)
- 如果 field 数量较多,存储结构使用 HashMap 结构(无序)
操作
指令操作:
-
数据操作
hset key field value #添加/修改数据hdel key field1 [field2] #删除数据,[]代表可选hsetnx key field value #设置field的值,如果该field存在则不做任何操作hmset key f1 v1 f2 v2... #添加/修改多个数据 -
查询操作
hget key field #获取指定field对应数据hgetall key #获取指定key所有数据hmget key field1 field2... #获取多个数据hexists key field #获取哈希表中是否存在指定的字段hlen key #获取哈希表中字段的数量 -
获取哈希表中所有的字段名或字段值
hkeys key #获取所有的fieldhvals key #获取所有的value -
设置指定字段的数值数据增加指定范围的值
hincrby key field increment #指定字段的数值数据增加指定的值,increment为负数则减少hincrbyfloat key field increment#操作小数
注意事项
- hash 类型中 value 只能存储字符串,不允许存储其他数据类型,不存在嵌套现象,如果数据未获取到,对应的值为(nil)
- 每个 hash 可以存储 2^32 - 1 个键值对
- hash 类型和对象的数据存储形式相似,并且可以灵活添加删除对象属性。但 hash 设计初衷不是为了存储大量对象而设计的,不可滥用,不可将 hash 作为对象列表使用
- hgetall 操作可以获取全部属性,如果内部 field 过多,遍历整体数据效率就很会低,有可能成为数据访问瓶颈
实现
哈希对象的内部编码有两种:ziplist(压缩列表)、hashtable(哈希表、字典)
-
压缩列表实现哈希对象:同一键值对的节点总是挨在一起,保存键的节点在前,保存值的节点在后

-
字典实现哈希对象:字典的每一个键都是一个字符串对象,每个值也是
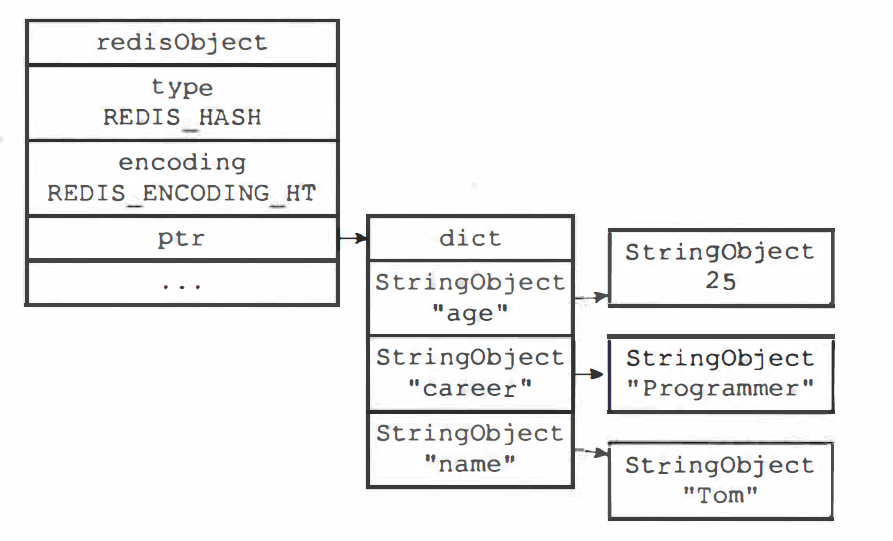
当存储的数据量比较小的情况下,Redis 才使用压缩列表来实现字典类型,具体需要满足两个条件:
- 当键值对数量小于 hash-max-ziplist-entries 配置(默认 512 个)
- 所有键和值的长度都小于 hash-max-ziplist-value 配置(默认 64 字节)
以上两个条件的上限值是可以通过配置文件修改的,当两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行
ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比 hashtable 更加优秀,当 ziplist 无法满足哈希类型时,Redis 会使用 hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度为 O(1)
应用
user:id:3506728370 → {"name":"春晚","fans":12210862,"blogs":83}
对于以上数据,使用单条去存的话,存的条数会很多。但如果用 json 格式,存一条数据就够了。
假如现在粉丝数量发生了变化,要把整个值都改变,但是用单条存就不存在这个问题,只需要改其中一个就可以
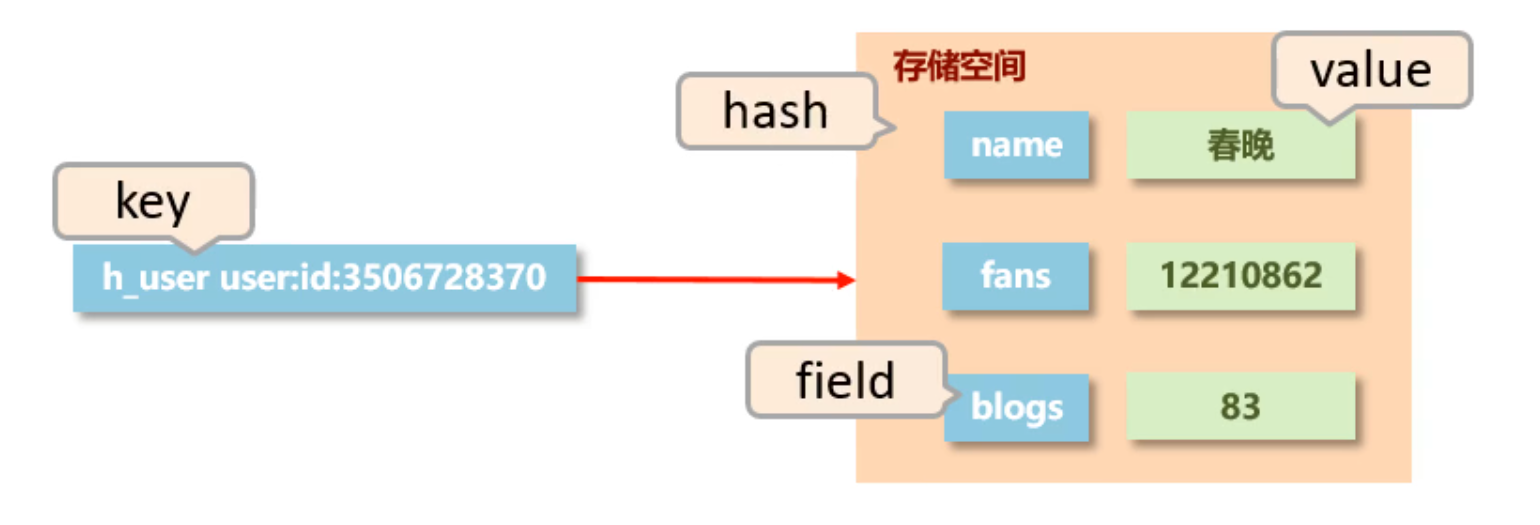
可以实现购物车的功能,key 对应着每个用户,存储空间存储购物车的信息
list
简介
数据存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分
数据存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序,允许重复元素
list 类型:保存多个数据,底层使用双向链表存储结构实现,类似于 LinkedList
如果两端都能存取数据的话,这就是双端队列,如果只能从一端进一端出,这个模型叫栈
操作
指令操作:
-
数据操作
lpush key value1 [value2]...#从左边添加/修改数据(表头)rpush key value1 [value2]...#从右边添加/修改数据(表尾)lpop key #从左边获取并移除第一个数据,类似于出栈/出队rpop key #从右边获取并移除第一个数据lrem key count value #删除指定数据,count=2删除2个,该value可��能有多个(重复数据) -
查询操作
lrange key start stop #从左边遍历数据并指定开始和结束索引,0是第一个索引,-1是终索引lindex key index #获取指定索引数据,没有则为nil,没有索引越界llen key #list中数据长度/个数 -
规定时间内获取并移除数据
b #代表阻塞blpop key1 [key2] timeout #在指定时间内获取指定key(可以多个)的数据,超时则为(nil)#可以从其他客户端写数据,当前客户端阻塞读取数据brpop key1 [key2] timeout #从右边操作 -
复制操作
brpoplpush source destination timeout #从source获取数据放入destination,假如在指定时间内没有任何元素被弹出,则返回一个nil和等待时长。反之,返回一个含有两个元素的列表,第一个元素是被弹出元素的值,第二个元素是等待时长
注意事项
- list 中保存的数据都是 string 类型的,数据总容量是有限的,最多 2^32 - 1 个元素(4294967295)
- list 具有索引的概念,但操作数据时通常以队列的形式进行入队出队,或以栈的形式进行入栈出栈
- 获取全部数据操作结束索引设置为 -1
- list 可以对数据进行分页操作,通常第一页的信息来自于 list,第 2 页及更多的信息通过数据库的形式加载
实现
在 Redis3.2 版本以前列表对象的内部编码有两种:ziplist(压缩列表)和 linkedlist(链表)
-
压缩列表实现的列表对象:PUSH 1、three、5 三个元素

-
链表实现的列表对象:为了简化字符串对象的表示,使用了 StringObject 的结构,底层其实是 sdshdr 结构
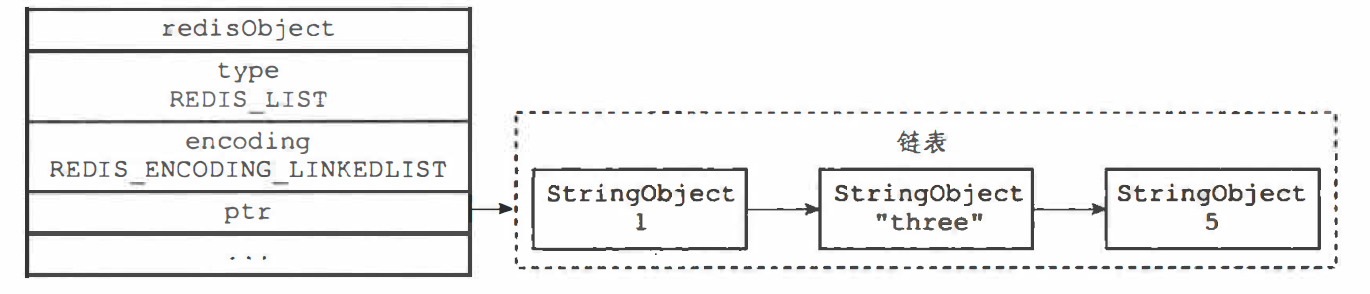
列表中存储的数据量比较小的时候,列表就会使用一块连续的内存存储,采用压缩列表的方式实现的条件:
- 列表对象保存的所有字符串元素的长度都小于 64 字节
- 列表对象保存的元素数量小于 512 个
以上两个条件的上限值是可以通过配置文件修改的,当两个条件的任意一个不能被满足时,对象的编码转换操作就会被执行
在 Redis3.2 版本 以后对列表数据结构进行了改造,使用 **quicklist(快速列表)**代替了 linkedlist,quicklist 实际上是 ziplist 和 linkedlist 的混合体,将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来,既满足了快速的插入删除性能,又不会出现太大的空间冗余
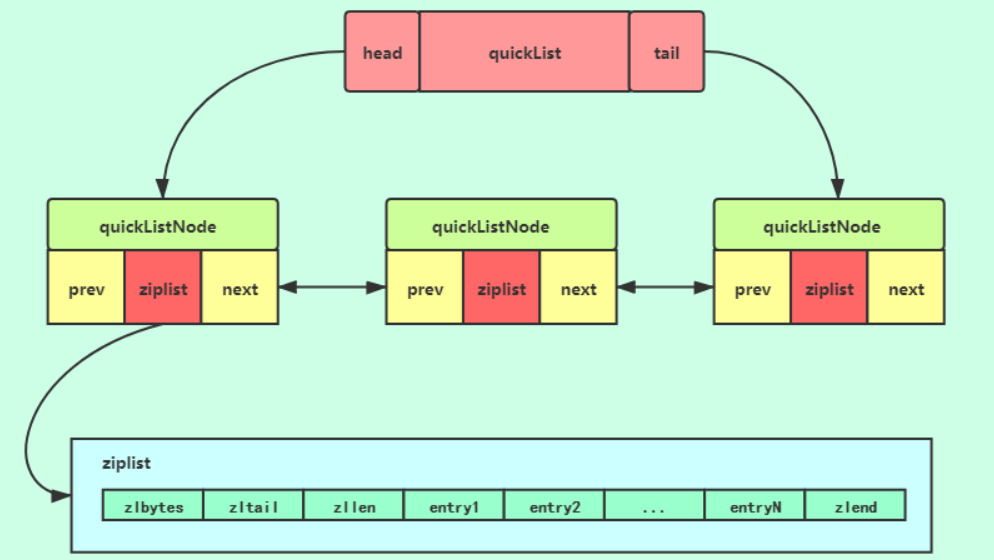
应用
企业运营过程中,系统将产生出大量的运营数据,如何保障多台服务器操作日志的统一顺序输出?
- 依赖 list 的数据具有顺序的特征对信息进行管理,右进左查或者左近左查
- 使用队列模型解决多路信息汇总合并的问题
- 使用栈模型解决最新消息的问题
微信文章订阅公众号:
- 比如订阅了两个公众号,它们发布了两篇文章,文章 ID 分别为 666 和 888,可以通过执行
LPUSH key 666 888命令推送给我
set
简介
数据存储需求:存储大量的数据,在查询�方面提供更高的效率
数据存储结构:能够保存大量的数据,高效的内部存储机制,便于查询
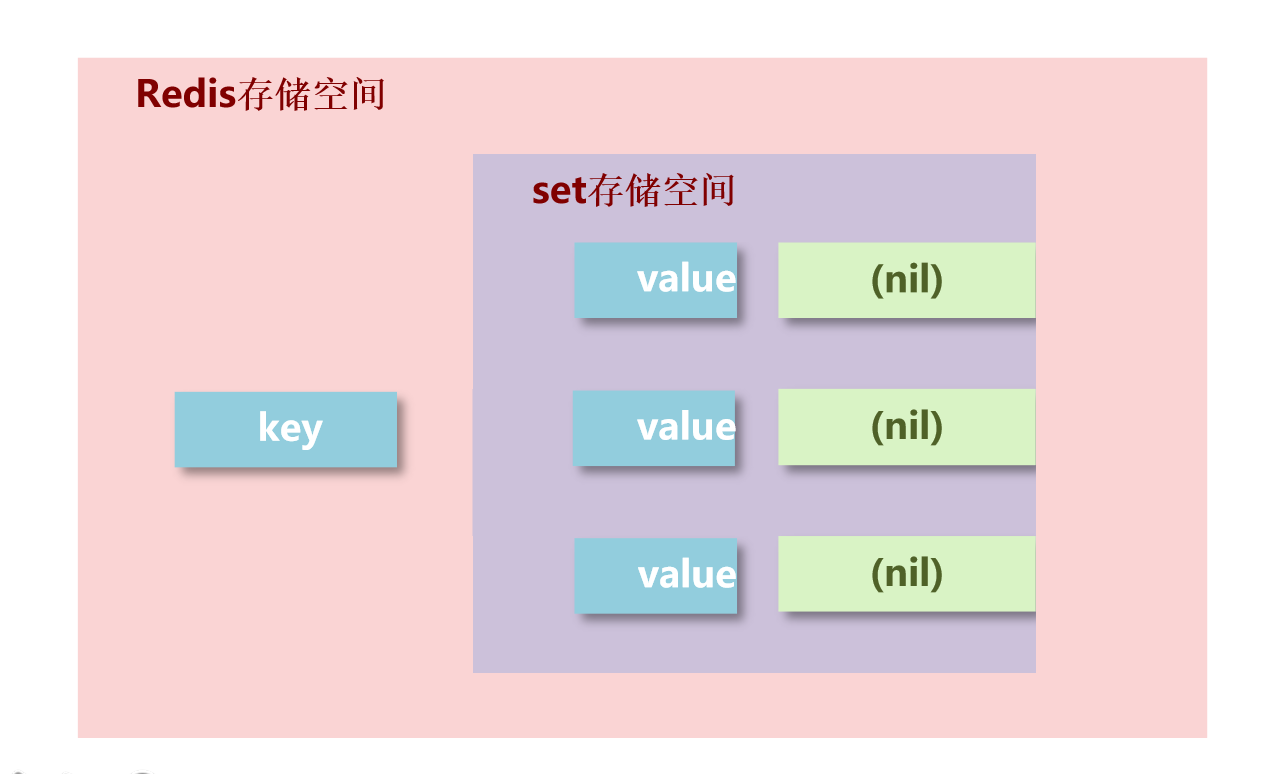
set 类型:与 hash 存储结构哈希表完全相同,只是仅存储键不存储值(nil),所以添加,删除,查找的复杂度都是 O(1),并且值是不允许重复且无序的
操作
指令操作:
-
数据操作
sadd key member1 [member2] #添加数据srem key member1 [member2] #删除数据 -
查询操作
smembers key #获取全部数据scard key #获取集合数据总量sismember key member #判断集合中是否包含指定数据 -
随机操作
spop key [count] #随机获取集中的某个数据并将该数据移除集合srandmember key [count] #随机获取集合中指定(数量)的数据 -
集合的交、并、差
sinter key1 [key2...] #两个集合的交集,不存在为(empty list or set)sunion key1 [key2...] #两个集合的并集sdiff key1 [key2...] #两个集合的差集sinterstore destination key1 [key2...] #两个集合的交集并存储到指定集合中sunionstore destination key1 [key2...] #两个集合的并集并存储到指定集合中sdiffstore destination key1 [key2...] #两个集合的差集并存储到指定集合中 -
复制
smove source destination member #将指定数据从原始集合中移动到目标集合中
注意事项
- set 类型不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份
- set 虽然与 hash 的存储结构相同,但是无法启用 hash 中存储值的空间
实现
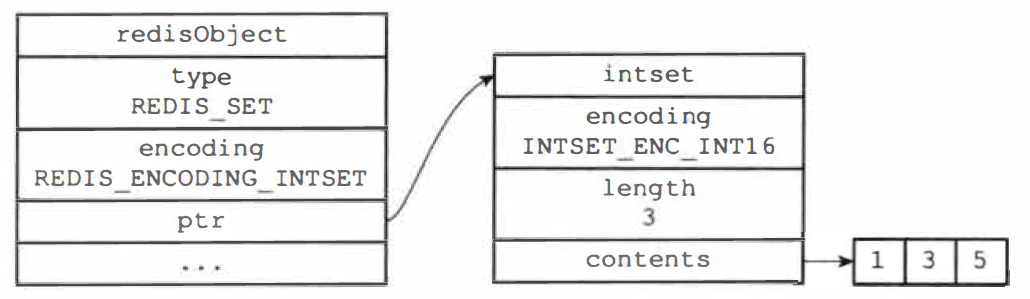
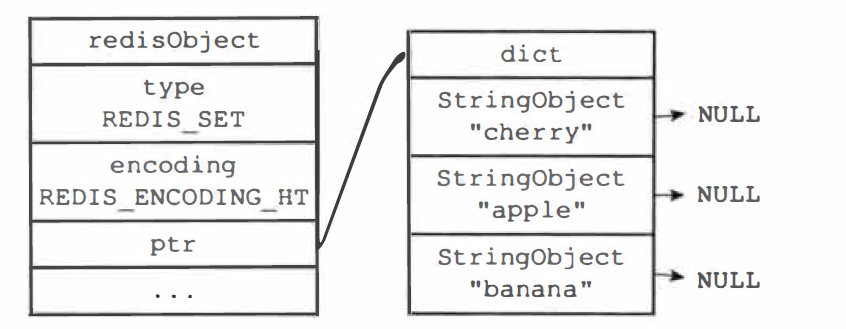
集合对象的内部编码有两种:intset(整数集合)、hashtable(哈希表、字典)
-
整数集合实现的集合对象:
-
字典实现的集合对象:键值对的值为 NULL
当集合对象可以同时满足以下两个条件时,对象使用 intset 编码:
- 集合中的元素都是整数值
- 集合中的元素数量小于 set-maxintset-entries配置(默认 512 个)
以上两个条件的上限值是可以通过配置文件修改的
应用
应用场景:
-
黑名单:资讯类信息类网站追求高访问量,但是由于其信息的价值,往往容易被不法分子利用,通过爬虫技术,快速获取信息,个别特种行业网站信息通过爬虫获取分析后,可以转换成商业机密。
注意:爬虫不一定做摧毁性的工作,有些小型网站需要爬虫为其带来一些流量。
-
白名单:对于安全性更高的应用访问,仅仅靠黑名单是不能解决安全问题的,此时需要设定可访问的用户群体, 依赖白名单做更为苛刻的访问验证
-
随机操作可以实现抽奖功能
-
集合的交并补可以实现微博共同关注的查看,可以根据共同关注或者共同喜欢推荐相关内容
zset
简介
数据存储需求:数据排序有利于数据的有效展示,需要提供一种可以根据自身特征进行排序的方式
数据存储结构:新的存储模型,可以保存可排序的数据
操作
指令操作:
-
数据操作
zadd key score1 member1 [score2 member2] #添加数据zrem key member [member ...] #删除数据zremrangebyrank key start stop #删除指定索引范围的数据zremrangebyscore key min max #删除指定分数区间内的数据zscore key member #获取指定值的分数zincrby key increment member #指定值的分数增加increment -
查询操作
zrange key start stop [WITHSCORES] #获取指定范围的数据,升序,WITHSCORES 代表显示分数zrevrange key start stop [WITHSCORES] #获取指定范围的数据,降序zrangebyscore key min max [WITHSCORES] [LIMIT offset count] #按条件获取数据,从小到大zrevrangebyscore key max min [WITHSCORES] [...] #从大到小zcard key #获取集合数据的总量zcount key min max #获取指定分数区间内的数据总量zrank key member #获取数据对应的索引(排名)升序zrevrank key member #获取数据对应的索引(排名)降序- min 与 max 用于限定搜索查询的条件
- start 与 stop 用于限定查询范围,作用于索引,表示开始和结束索引
- offset 与 count 用于限定查询范围,作用于查询结果,表示开始位置和数据总量
-
集合的交、并操作
zinterstore destination numkeys key [key ...] #两个集合的交集并存储到指定集合中zunionstore destination numkeys key [key ...] #两个集合的并集并存储到指定集合中
注意事项:
- score 保存的数据存储空间是 64 位,如果是整数范围是 -9007199254740992~9007199254740992
- score 保存的数据也可以是一个双精度的 double 值,基于双精度浮点数的特征可能会丢失精度,慎重使用
- sorted_set 底层存储还是基于 set 结构的,因此数据不能重复,如果重复添加相同的数据,score 值将被反复覆盖,保留最后一次修改的结果
实现
有序集合对象的内部编码有两种:ziplist(压缩列表)和 skiplist(跳跃表)
-
压缩列表实现有序集合对象:ziplist 本身是有序、不可重复的,符合有序集合的特性

-
跳跃表实现有序集合对象:底层是 zset 结构,zset 同时包含字典和跳跃表的结构,图示字典和跳跃表中重复展示了各个元素的成员和分值,但实际上两者会通过指针来共享相同元素的成员和分值,不会产生空间浪费
typedef struct zset {zskiplist *zsl;dict *dict;} zset;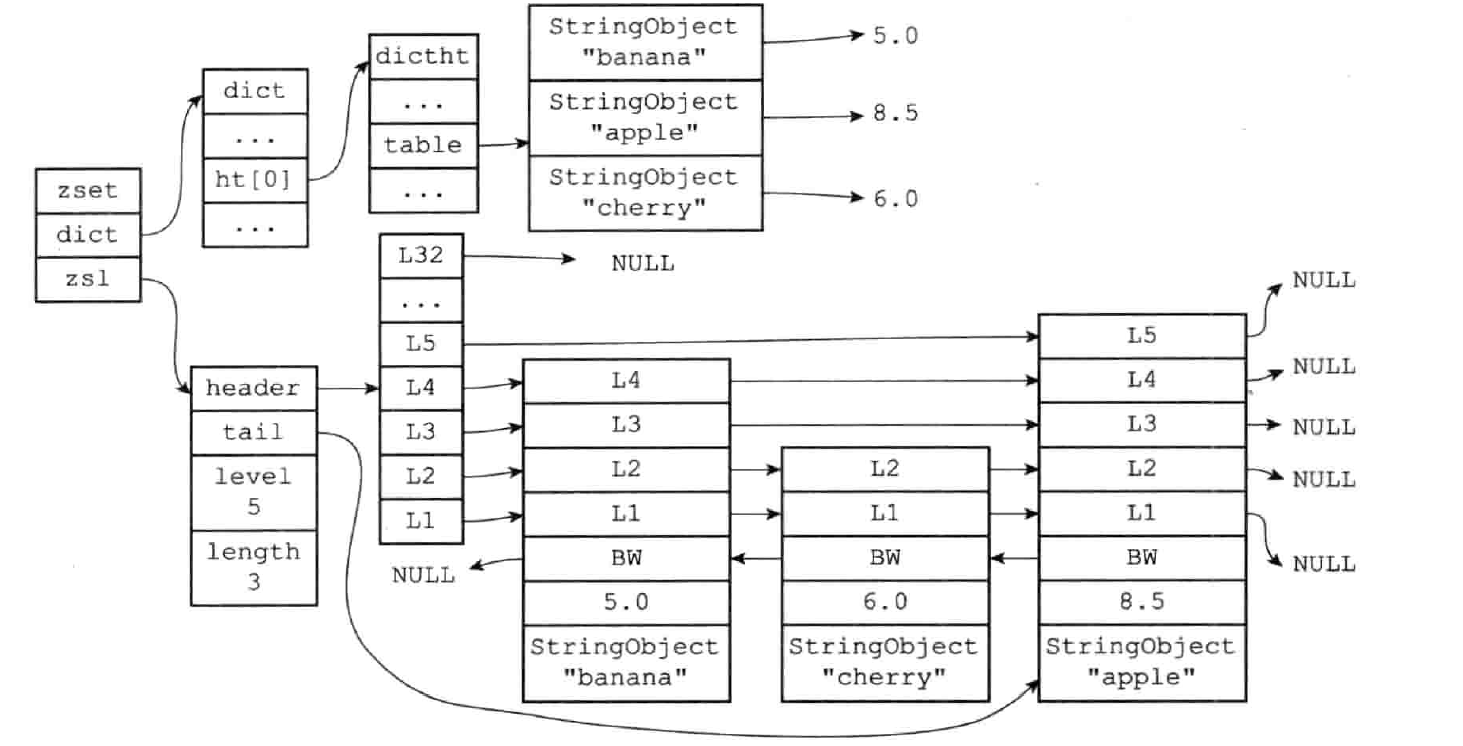
使用字典加跳跃表的优势:
- 字典为有序集合创建了一个从成员到分值的映射,用 O(1) 复杂度查找给定成员的分值
- 排序操作使用跳跃表完成,节省每次重新排序带来的时间成本和空间成本
使用 ziplist 格式存储需要满足以下两个条件:
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素大小都小于 64 字节
当元素比较多时,此时 ziplist 的读写效率会下降,时间复杂度是 O(n),跳表的时间复杂度是 O(logn)
为什么用跳表而不用平衡树?
- 在做范围查找的时候,跳表操作简单(前进指针或后退指针),平衡树需要回旋查找
- 跳表比平衡树实现简单,平衡树的插入和删除操作可能引发子树的旋转调整,而跳表的插入和删除只需要修改相邻节点的指针
应用
- 排行榜
- 对于基于时间线限定的任务处理,将处理时间记录为 score 值,利用排序功能区分处理的先后顺序
- 当任务或者消息待处理,形成了任务队列或消息队列时,对于高优先级的任务要保障对其优先处理,采用 score 记录权重
Bitmaps
基本操作
Bitmaps 是二进制位数组(bit array),底层使用 SDS 字符串表示,因为 SDS 是二进制安全的
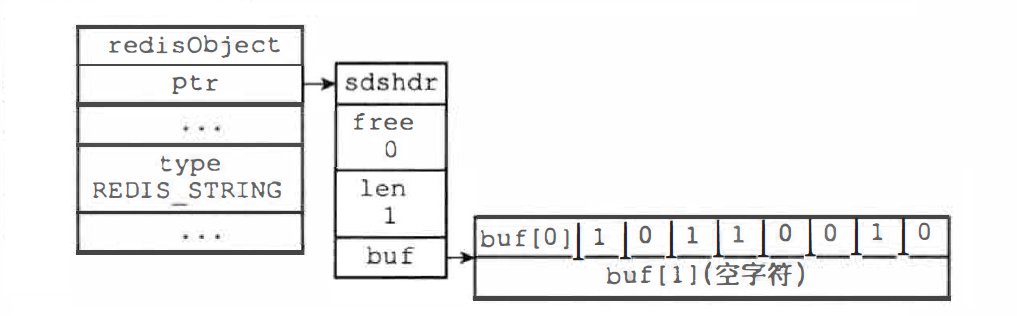
buf 数组的每个字节用一行表示,buf[1] 是 '\0',保存位数组的顺序和书写位数组的顺序是完全相反的,图�示的位数组 0100 1101
数据结构的详解查看 Java → Algorithm → 位图
命令实现
GETBIT
GETBIT 命令获取位数组 bitarray 在 offset 偏移量上的二进制位的值
GETBIT <bitarray> <offset>
执行过程:
- 计算
byte = offset/8(向下取整), byte 值记录数据保存在位数组中的索引 - 计算
bit = (offset mod 8) + 1,bit 值记录数据在位数组中的第几个二进制位 - 根据 byte 和 bit 值,在位数组 bitarray 中定位 offset 偏移量指定的二进制位,并返回这个位的值
GETBIT 命令执行的所有操作都可以在常数时间内完成,所以时间复杂度为 O(1)
SETBIT
SETBIT 将位数组 bitarray 在 offset 偏移量上的二进制位的值设置为 value,并向客户端返回二进制位的旧值
SETBIT <bitarray> <offset> <value>
执行过程:
- 计算
len = offset/8 + 1,len 值记录了保存该数据至少需要多少个字节 - 检查 bitarray 键保存的位数组的长度是否小于 len,成立就会将 SDS 扩展为 len 字节(注意空间预分配机制),所有新扩展空间的二进制位的值置为 0
- 计算
byte = offset/8(向下取整), byte 值记录数据保存在位数组中的索引 - 计算
bit = (offset mod 8) + 1,bit 值记录数据在位数组中的第几个二进制位 - 根据 byte 和 bit 值,在位数组 bitarray 中定位 offset 偏移量指定的二进制位,首先将指定位现存的��值保存在 oldvalue 变量,然后将新值 value 设置为这个二进制位的值
- 向客户端返回 oldvalue 变量的值
BITCOUNT
BITCOUNT 命令用于统计给定位数组中,值为 1 的二进制位的数量
BITCOUNT <bitarray> [start end]
二进制位统计算法:
- 遍历法:遍历位数组中的每个二进制位
- 查表算法:读取每个字节(8 位)的数据,查表获取数值对应的二进制中有几个 1
- variable-precision SWAR算法:计算汉明距离
- Redis 实现:
- 如果二进制位的数量大于等于 128 位, 那么使用 variable-precision SWAR 算法来计算二进制位的汉明重量
- 如果二进制位的数量小于 128 位,那么使用查表算法来计算二进制位的汉明重量
BITOP
BITOP 命令对指定 key 按位进行交、并、非、异或操作,并将结果保存到指定的键中
BITOP OPTION destKey key1 [key2...]
OPTION 有 AND(与)、OR(或)、 XOR(异或)和 NOT(非)四个选项
AND、OR、XOR 三个命令可以接受多个位数组作为输入,需要遍历输入的每个位数组的每个字节来进行计算,所以命令的复杂度为 O(n^2);与此相反,NOT 命令只接受一个位数组输入,所以时间复杂度为 O(n)
应用场景
-
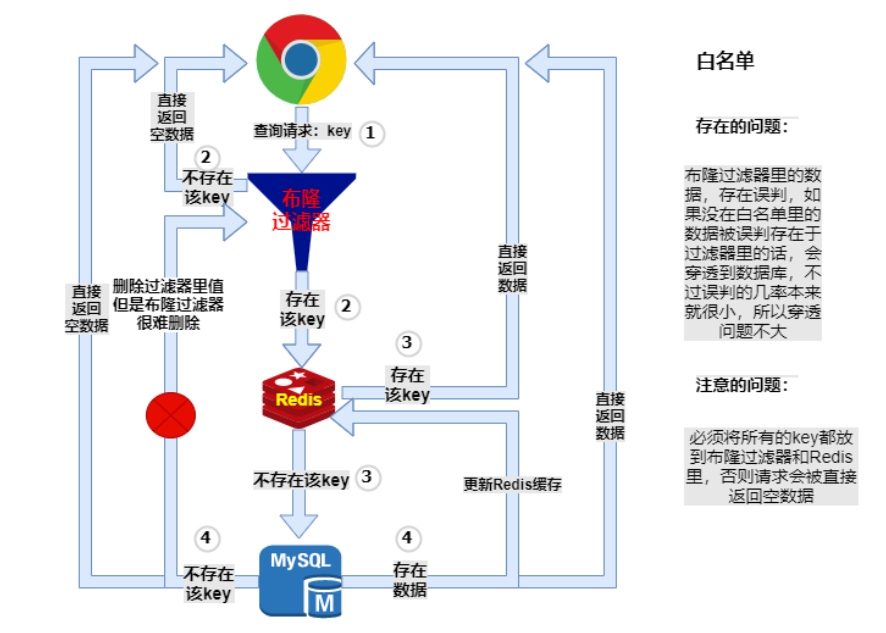
解决 Redis 缓存穿透,判断给定数据是否存在, 防止缓存穿透
-
垃圾邮件过滤,对每一个发送邮件的地址进行判断是否在布隆的黑名单中,如果在就判断为垃圾邮件
-
爬虫去重,爬给定网址��的时候对已经爬取过的 URL 去重
-
信息状态统计
Hyper
基数是数据集去重后元素个数,HyperLogLog 是用来做基数统计的,运用了 LogLog 的算法
{1, 3, 5, 7, 5, 7, 8} 基数集: {1, 3, 5 ,7, 8} 基数:5
{1, 1, 1, 1, 1, 7, 1} 基�数集: {1,7} 基数:2
相关指令:
-
添加数据
pfadd key element [element ...] -
统计数据
pfcount key [key ...] -
合并数据
pfmerge destkey sourcekey [sourcekey...]
应用场景:
- 用于进行基数统计,不是集合不保存数据,只记录数量而不是具体数据,比如网站的访问量
- 核心是基数估算算法,最终数值存在一定误差
- 误差范围:基数估计的结果是一个带有 0.81% 标准错误的近似值
- 耗空间极小,每个 hyperloglog key 占用了12K的内存用于标记基数
- pfadd 命令不是一次性分配12K内存使用,会随着基数的增加内存逐渐增大
- Pfmerge 命令合并后占用的存储空间为12K,无论合并之前数据量多少
GEO
GeoHash 是一种地址编码方法,把二维的空间经纬度数据编码成一个字符串
-
添加坐标点
geoadd key longitude latitude member [longitude latitude member ...]georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count] -
获取坐标点
geopos key member [member ...]georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count] -
计算距离
geodist key member1 member2 [unit] #计算坐标点距离geohash key member [member ...] #计算经纬度
Redis 应用于地理位置计算
持久机制
概述
持久化:利用永久性存储介质将数据进行保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化
作用:持久化用于防止数据的意外丢失,确保数据安全性,因为 Redis 是内存级,所以需要持久化到磁盘
计算机中的数据全部都是二进制,保存一组数据有两种方式

RDB:将当前数据状态进行保存,快照形式,存储数据结果,存储格式简单
AOF:将数据�的操作过程进行保存,日志形式,存储操作过程,存储格式复杂
RDB
文件创建
RDB 持久化功能所生成的 RDB 文件是一个经过压缩的紧凑二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态,有两个 Redis 命令可以生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE
SAVE
SAVE 指令:手动执行一次保存操作,该指令的执行会阻塞当前 Redis 服务器,客户端发送的所有命令请求都会被拒绝,直到当前 RDB 过程完成为止,有可能会造成长时间阻塞,线上环境不建议使用
工作原理:Redis 是个单线程的工作模式,会创建一个任务队列,所有的命令都会进到这个队列排队执行。当某个指令在执行的时候,队列后面的指令都要等待,所以这种执行方式会非常耗时
配置 redis.conf:
dir path #设置存储.rdb文件的路径,通常设置成存储空间较大的目录中,目录名称data
dbfilename "x.rdb" #设置本地数据库文件名,默认值为dump.rdb,通常设置为dump-端口号.rdb
rdbcompression yes|no #设置存储至本地数据库时是否压缩数据,默认yes,设置为no节省CPU运行时间
rdbchecksum yes|no #设置读写文件过程是否进行RDB格式校验,默认yes
BGSAVE
BGSAVE:bg 是 background,代表后台执行,命令的完成需要两个进程,进程之间不相互影响,所以持久化期间 Redis 正常工作
工作原理:
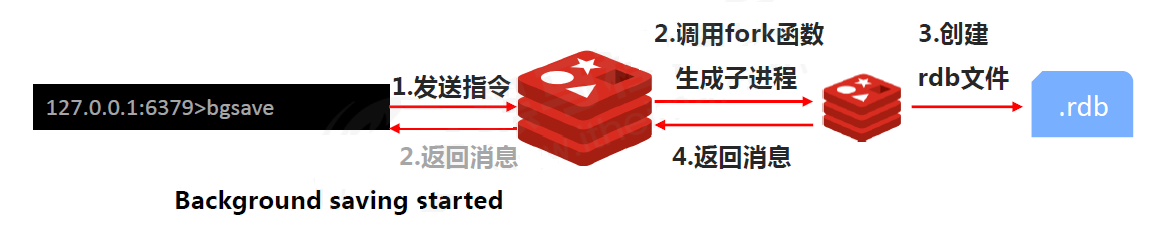
流程:客户端发出 BGSAVE 指令,Redis 服务器使用 fork 函数创建一个子进程,然后响应后台已经开始执行的信息给客户端。子进程会异步执行持久化的操作,持久化过程是先将数据写入到一个临时文件中,持久化操作结束再用这个临时文件替换上次持久化的文件
# 创建子进程
pid = fork()
if pid == 0:
# 子进程负责创建 RDB 文件
rdbSave()
# 完成之后向父进程发送信号
signal_parent()
elif pid > 0:
# 父进程继续处理命令请求,并通过轮询等待子进程的信号
handle_request_and_wait_signal()
else:
# 处理出错恃况
handle_fork_error()
配置 redis.conf
stop-writes-on-bgsave-error yes|no #后台存储过程中如果出现错误,是否停止保存操作,默认yes
dbfilename filename
dir path
rdbcompression yes|no
rdbchecksum yes|no
注意:BGSAVE 命令是针对 SAVE 阻�塞问题做的优化,Redis 内部所有涉及到 RDB 操作都采用 BGSAVE 的方式,SAVE 命令放弃使用
在 BGSAVE 命令执行期间,服务器处理 SAVE、BGSAVE、BGREWRITEAOF 三个命令的方式会和平时有所不同
- SAVE 命令会被服务器拒绝,服务器禁止 SAVE 和 BGSAVE 命令同时执行是为了避免父进程(服务器进程)和子进程同时执行两个 rdbSave 调用,产生竞争条件
- BGSAVE 命令也会被服务器拒绝,也会产生竞争条件
- BGREWRITEAOF 和 BGSAVE 两个命令不能同时执行
- 如果 BGSAVE 命令正在执行,那么 BGREWRITEAOF 命令会被延迟到 BGSAVE 命令执行完毕之后执行
- 如果 BGREWRITEAOF 命令正在执行,那么 BGSAVE 命令会被服务器拒绝
特殊指令
RDB 特殊启动形式的指令(客户端输入)
-
服务器运行过程中重启
debug reload -
关闭服务器时指定保存数据
shutdown save默认情况下执行 shutdown 命令时,自动执行 bgsave(如果没有开启 AOF 持久化功能)
-
全量复制:主从复制部分详解
文件载入
RDB 文件的载入工作是在服务器启动时自动执行,期间 Redis 会一直处于阻塞状态,直到载入完成
Redis 并没有专门用于载入 RDB 文件的命令,只要服务器在启动时检测到 RDB 文件存在,就会自动载入 RDB 文件
[7379] 30 Aug 21:07:01.289 * DB loaded from disk: 0.018 seconds # 服务器在成功载入 RDB 文件之后打印
AOF 文件的更新频率通常比 RDB 文件的更新频率高:
- 如果服务器开启了 AOF 持久化功能,那么会优先使用 AOF 文件来还原数据库状态
- 只有在 AOF 持久化功能处于关闭状态时,服务器才会使用 RDB 文件来还原数据库状态
自动保存
配置文件
Redis 支持通过配置服务器的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命令
配置 redis.conf:
save second changes #设置自动持久化条件,满足限定时间范围内key的变化数量就进行持久化(bgsave)
- second:监控时间范围
- changes:监控 key 的变化量
默认三个条件:
save 900 1 # 900s内1个key发生变化就进行持久化
save 300 10
save 60 10000
判定 key 变化的依据:
- 对数据产生了影响,不包括查询
- 不进行数据比对,比如 name 键存在,重新 set name seazean 也算一次变化
save 配置要根据实际业务情况进行设置,频度过高或过低都会出现性能问题,结果可能是灾难性的
自动原理
服务器状态相关的属性:
struct redisServer {
// 记录了保存条件的数组
struct saveparam *saveparams;
// 修改计数器
long long dirty;
// 上一次执行保存的时间
time_t lastsave;
};
-
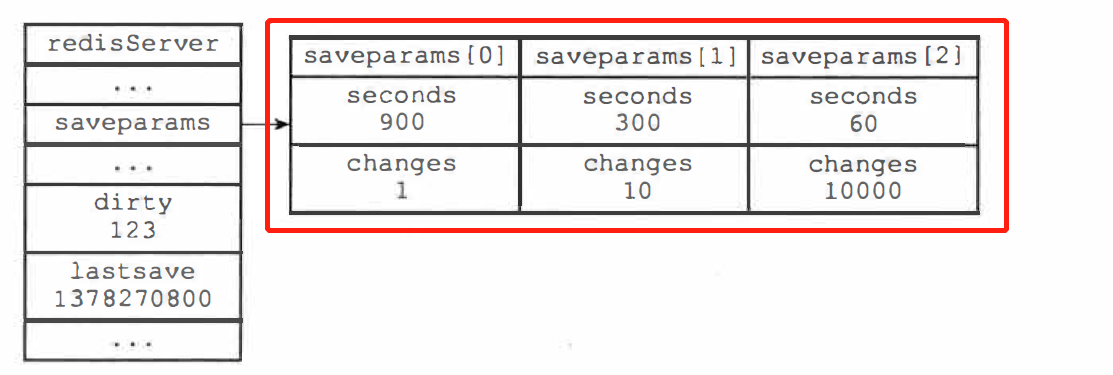
Redis 服务器启动时,可以通过指定配置文件或者传入启动参数的方式设置 save 选项, 如果没有自定义就设置为三个默认值(上节提及),设置服务器状态 redisServe.saveparams 属性,该数组每一项为一个 saveparam 结构,代表 save 的选项设置
struct saveparam {// 秒数time_t seconds// 修改数int changes;}; -
dirty 计数器记录距离上一次成功执行 SAVE 或者 BGSAVE 命令之后,服务器中的所有数据库进行了多少次修改(包括写入、删除、更新等操作),当服务器成功执行一个修改指令,该命令修改了多少次数据库, dirty 的值就增加多少
-
lastsave 属性是一个 UNIX 时间戳,记录了服务器上一次成功执行 SAVE 或者 BGSAVE 命令的时间
Redis 的服务器周期性操作函数 serverCron 默认每隔 100 毫秒就会执行一次,该函数用于对正在运行的服务器进行维护
serverCron 函数的其中一项工作是检查 save 选项所设置的保存条件是否满足,会遍历 saveparams 数组中的所有保存条件,只要有任意一个条件被满足服务器就会执行 BGSAVE 命令
文件结构
RDB 的存储结构:图示全大写单词标示常量,用全小写单词标示变量和数据

- REDIS:长度为 5 字节,保存着
REDIS五个字符,是 RDB 文件的开头,在载入文件时可以快速检查所载入的文件是否 RDB 文件 - db_version:长度为 4 字节,是一个用字符串表示的整数,记录 RDB 的版本号
- database:包含着零个或任意多个数据库,以及各个数据库中的键值对数据
- EOF:长度为 1 字节的常量,标志着 RDB 文件正文内容的结束,当读入遇到这个值时,代表所有数据库的键值对都已经载入完毕
- check_sum:长度为 8 字节的无符号整数,保存着一个校验和,该值是通过 REDIS、db_version、databases、EOF 四个部分的内容进行计算得出。服务器在载入 RDB 文件时,会将载入数据所计算出的校验和与 check_sum 所记录的校验和进行对比,来检查 RDB 文件是否有出错或者损坏
Redis 本身带有 RDB 文件检查工具 redis-check-dump
AOF
基本概述
AOF(append only file)持久化:以独立日志的方式记录每次写命令(不记录读)来记录数据库状态,增量保存只许追加文件但不可以改写文件,与 RDB 相比可以理解为由记录数据改为记录数据的变化
AOF 主要作用是解决了数据持久化的实时性,目前已经是 Redis 持久化的主流方式
AOF 写数据过程:
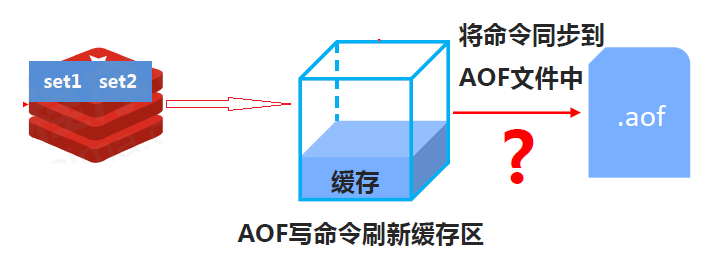
Redis 只会将对数据库进行了修改的命令写入到 AOF 文件,并复制到各个从服务器,但是 PUBSUB 和 SCRIPT LOAD 命令例外:
- PUBSUB 命令虽然没有修改数据库,但 PUBSUB 命令向频道的所有订阅者发送消息这一行为带有副作用,接收到消息的所有客户端的状态都会因为这个命令而改变,所以服务器需要使用 REDIS_FORCE_AOF 标志强制将这个命令写入 AOF 文件。这样在将来载入 AOF 文件时,服务器就可以再次执行相同的 PUBSUB 命令,并产生相同的副作用
- SCRIPT LOAD 命令虽然没有修改数据库,但它修改了服务器状态,所以也是一个带有副作用的命令,需要使用 REDIS_FORCE_AOF
持久实现
AOF 持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤
命令追加
启动 AOF 的基本配置:
appendonly yes|no #开启AOF持久化功能,默认no,即不开启状态
appendfilename filename #AOF持久化文件名,默认appendonly.aof,建议设置appendonly-端口号.aof
dir #AOF持久化文件保存路径,与RDB持久化文件路径保持一致即可
当 AOF 持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾
struct redisServer {
// AOF 缓冲区
sds aof_buf;
};
文件写入
服务器在处理文件事件时会执行写命令,追加一些内容到 aof_buf 缓冲区里,所以服务器每次结束一个事件循环之前,就会执行 flushAppendOnlyFile 函数,判断是否需要将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件里
flushAppendOnlyFile 函数的行为由服务器配置的 appendfsync 选项的值来决定
appendfsync always|everysec|no #AOF写数据策略:默认为everysec
-
always:每次写入操作都将 aof_buf 缓冲区中的所有内容写入并同步到 AOF 文件
特点:安全性最高,数据零误差,但是性能较低,不建议使用
-
everysec:先将 aof_buf 缓冲区中的内容写入到操作系统缓存,判断上次同步 AOF 文件的时间距离现在超过一秒钟,再次进行同步 fsync,这个同步操作是由一个(子)线程专门负责执行的
特点:在系统突然宕机的情况下丢失 1 秒内的数据,准确性较高,性能较高,建议使用,也是默认配置
-
no:将 aof_buf 缓冲区中的内容写入到操作系统缓存,但并不进行同步,何时同步由操作系统来决定
特点:整体不可控,服务器宕机会丢失上次同步 AOF 后的所有写指令
文件同步
在现代操作系统中,当用户调用 write 函数将数据写入文件时,操作系统通常会将写入数据暂时保存在一个内存缓冲区空间,等到缓冲区写满或者到达特定时间周期,才真正地将缓冲区中的数据写入到磁盘里面(刷脏)
- 优点:提高文件的写入效率
- 缺点:为写入数据带来了安全问题,如果计算机发生停机,那么保存在内存缓冲区里面的写入数据将会丢失
系统提供了 fsync 和 fdatasync 两个同步函数做强制硬盘同步,可以让操作系统立即将缓冲区中的数据写入到硬盘里面,函数会阻塞到写入硬盘完成后返回,保证了数据持久化
异常恢复:AOF 文件损坏,通过 redis-check-aof--fix appendonly.aof 进行恢复,重启 Redis,然后重新加载
文件载入
AOF 文件里包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍 AOF 文件里的命令,就还原服务器关闭之前的数据库状态,服务器在启动时,还原数据库状态打印的日志:
[8321] 05 Sep 11:58:50.449 * DB loaded from append only file: 0.000 seconds
AOF 文件里面除了用于指定数据库的 SELECT 命令是服务器自动添加的,其他都是通过客户端发送的命令
* 2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n # 服务器自动添加
* 3\r\n$3\r\nSET\r\n$3\r\nmsg\r\n$5\r\nhello\r\n
* 5\r\n$4\r\nSADD\r\n$6\r\nfruits\r\n$5\r\napple\r\n$6\r\nbanana\r\n$6\r\ncherry\r\n
Redis 读取 AOF 文件并还原数据库状态的步骤:
- 创建一个不带网络连接的伪客户端(fake client)执行命令,因为 Redis 的命令只能在客户端上下文中执行, 而载入 AOF 文件时所使用的命令来源于本地 AOF 文件而不是网络连接
- 从 AOF 文件分析并读取一条写命令
- 使用伪客户端执行被读出的写命令,然后重复上述步骤
重写实现
重写策略
AOF 重写:读取服务器当前的数据库状态,生成新 AOF 文件来替换旧 AOF 文件,不会对现有的 AOF 文件进行任何读取、分析或者写入操作,而是直接原子替换。新 AOF 文件不会包含任何浪费空间的冗余命令,所以体积通常会比旧 AOF 文件小得多
AOF 重写规则:
-
进程内具有时效性的数据,并且数据已超时将不再写入文件
-
对同一数据的多条写命令合并为一条命令,因为会读取当前的状态,所以直接将当前状态转换为一条命令即可。为防止数据量过大造成客户端缓冲区溢出,对 list、set、hash、zset 等集合类型,单条指令最多写入 64 个元素
如 lpushlist1 a、lpush list1 b、lpush list1 c 可以转化为:lpush list1 a b c
-
非写入类的无效指令将被忽略,只保留最终数据的写入命令,但是 select 指令虽然不更改数据,但是更改了数据的存储位置,此类命令同样需要记录
AOF 重写作用:
- 降低磁盘占用量,提高磁盘利用率
- 提高持久化效率,降低持久化写时间,提高 IO 性能
- 降低数据恢复的用时,提高数据恢复效率
重写原理
AOF 重写程序 aof_rewrite 函数可以创建一个新 AOF 文件, 但是该函数会进行大量的写入操作,调用这个函数的线程将被长时间阻塞,所以 Redis 将 AOF 重写程序放到 fork 的子进程里执行,不会阻塞父进程,重写命令:
bgrewriteaof
-
子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理命令请求
-
子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下, 保证数据安全性

子进程在进行 AOF 重写期间,服务器进程还需要继续处理命令请求,而新命令可能会对现有的数据库状态进行修改,从而使得服务器当前的数据库状态和重写后的 AOF 文件所保存的数据库状态不一致,所以 Redis 设置了 AOF 重写缓冲区
工作流程:
- Redis 服务器执行完一个写命令,会同时将该命令追加到 AOF 缓冲区和 AOF 重写缓冲区(从创建子进程后才开始写入)
- 当子进程完成 AOF 重写工作之后,会向父进程发送一个信号,父进程在接到该信号之后, 会调用一个信号处理函数,该函数执行时会对服务器进程(父进程)造成阻塞(影响很小,类似 JVM STW),主要工作:
- 将 AOF 重写缓冲区中的所有内容写入到新 AOF 文件中, 这时新 AOF 文件所保存的状态将和服务器当前的数据库状态一致
- 对新的 AOF 文件进行改名,原子地(atomic)覆盖现有的 AOF 文件,完成新旧两个 AOF 文件的替换
自动重写
触发时机:Redis 会记录上次重写时的 AOF 大小,默认配置是当 AOF 文件大小是上次重写后大小的一倍且文件大于 64M 时触发
auto-aof-rewrite-min-size size #设置重写的基准值,最小文件 64MB,达到这个值开始重写
auto-aof-rewrite-percentage percent #触发AOF文件执行重写的增长率,当前AOF文件大小超过上一次重写的AOF文件大小的百分之多少才会重写,比如文件达到 100% 时开始重写就是两倍时触发
自动重写触发比对参数( 运行指令 info Persistence 获取具体信息 ):
aof_current_size #AOF文件当前尺寸大小(单位:字节)
aof_base_size #AOF文件上次启动和重写时的尺寸大小(单位:字节)
自动重写触发条件公式:
- aof_current_size > auto-aof-rewrite-min-size
- (aof_current_size - aof_base_size) / aof_base_size >= auto-aof-rewrite-percentage
对比
RDB 的特点
-
RDB 优点:
- RDB 是一个紧凑压缩的二进制文件,存储效率较高,但存储数据量较大时,存储效率较低
- RDB 内部存储的是 Redis 在某个时间点的数据快照,非常适合用于数据备份,全量复制、灾难恢复
- RDB 恢复数据的速度要比 AOF 快很多,因为是快照,直接恢复
-
RDB 缺点:
- BGSAVE 指令每次运行要执行 fork 操作创建子进程,会牺牲一些性能
- RDB 方式无论是执行指令还是利用配置,无法做到实时持久化,具有丢失数据的可能性,最后一次持久化后的数据可能丢失
- Redis 的众多版本中未进行 RDB 文件格式的版本统一,可能出现各版本之间数据格式无法兼容
AOF 特点:
- AOF 的优点:数据持久化有较好的实时性,通过 AOF 重写可以降低文件的体积
- AOF 的缺点:文件较大时恢复较慢
AOF 和 RDB ��同时开启,系统默认取 AOF 的数据(数据不会存在丢失)
应用场景:
-
对数据非常敏感,建议使用默认的 AOF 持久化方案,AOF 持久化策略使用 everysecond,每秒钟 fsync 一次,该策略 Redis 仍可以保持很好的处理性能
注意:AOF 文件存储体积较大,恢复速度较慢,因为要执行每条指令
-
数据呈现阶段有效性,建议使用 RDB 持久化方案,可以做到阶段内无丢失,且恢复速度较快
注意:利用 RDB 实现紧凑的数据持久化,存储数据量较大时,存储效率较低
综合对比:
- RDB 与 AOF 的选择实际上是在做一种权衡,每种都有利有弊
- 灾难恢复选用 RDB
- 如不能承受数分钟以内的数据丢失,对业务数据非常敏感,选用 AOF;如能承受数分钟以内的数据丢失,且追求大数据集的恢复速度,选用 RDB
- 双保险策略,同时开启 RDB 和 AOF,重启后 Redis 优先使用 AOF 来恢复数据,降低丢失数据的量
- 不建议单独用 AOF,因为可能会出现 Bug,如果只是做纯内存缓存,可以都不用
fork
介绍
fork() 函数创建一个子进程,子进程与父进程几乎是完全相同的进程,系统先给子进程分配资源,然后把父进程的所有数据都复制到子进程中,只有少数值与父进程的值不同,相当于克隆了一个进程
在完成对其调用之后,会产�生 2 个进程,且每个进程都会从 fork() 的返回处开始执行,这两个进程将执行相同的程序段,但是拥有各自不同的堆段,栈段,数据段,每个子进程都可修改各自的数据段,堆段,和栈段
#include<unistd.h>
pid_t fork(void);
// 父进程返回子进程的pid,子进程返回0,错误返回负值,根据返回值的不同进行对应的逻辑处理
fork 调用一次,却能够返回两次,可能有三种不同的返回值:
- 在父进程中,fork 返回新创建子进程的进程 ID
- 在子进程中,fork 返回 0
- 如果出现错误,fork 返回一个负值,错误原因:
- 当前的进程数已经达到了系统规定的上限,这时 errno 的值被设置为 EAGAIN
- 系统内存不足,这时 errno 的值被设置为 ENOMEM
fpid 的值在父子进程中不同:进程形成了链表,父进程的 fpid 指向子进程的进程 id,因为子进程没有子进程,所以其 fpid 为0
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的调度策略
每个进程都有一个独特(互不相同)的进程标识符 process ID,可以通过 getpid() 函数获得;还有一个记录父进程 pid 的变量,可以通过 getppid() 函数获得变量的值
使用
基本使用:
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid; // fpid表示fork函数返回的值
int count = 0;
fpid = fork();
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0) {
printf("i am the child process, my process id is %d/n", getpid());
count++;
}
else {
printf("i am the parent process, my process id is %d/n", getpid());
count++;
}
printf("count: %d/n",count);// 1
return 0;
}
/* 输出内容:
i am the child process, my process id is 5574
count: 1
i am the parent process, my process id is 5573
count: 1
*/
进阶使用:
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i = 0;
// ppid 指当前进程的父进程pid
// pid 指当前进程的pid,
// fpid 指fork返回给当前进程的值,在这可以表示子进程
for(i = 0; i < 2; i++){
pid_t fpid = fork();
if(fpid == 0)
printf("%d child %4d %4d %4d/n",i, getppid(), getpid(), fpid);
else
printf("%d parent %4d %4d %4d/n",i, getppid(), getpid(),fpid);
}
return 0;
}
/*输出内容:
i 父id id 子id
0 parent 2043 3224 3225
0 child 3224 3225 0
1 parent 2043 3224 3226
1 parent 3224 3225 3227
1 child 1 3227 0
1 child 1 3226 0
*/
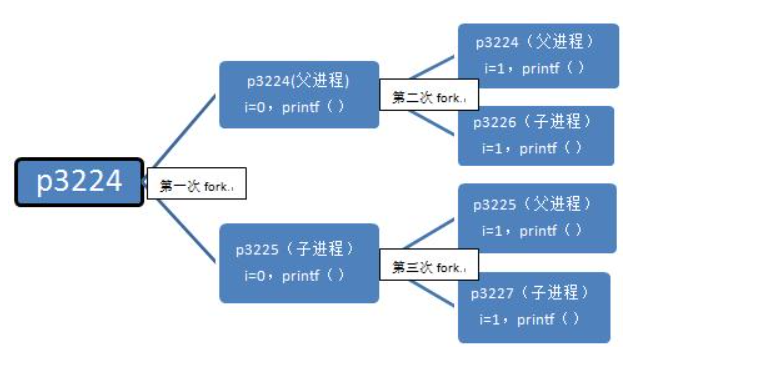
在 p3224 和 p3225 执行完第二个循环后,main 函数退出,进程死亡。所以 p3226,p3227 就没有父进程了,成为孤儿进程,所以 p3226 和 p3227 的父进程就被置为 ID 为 1 的 init 进程(笔记 Tool → Linux → 进程管理详解)
参考文章:https://blog.csdn.net/love_gaohz/article/details/41727415
内存
fork() 调用之后父子进程的内存关系
早期 Linux 的 fork() 实现时,就是全部复制,这种方法效率太低,而且造成了很大的内存浪费,现在 Linux 实现采用了两种方法:
-
父子进程的代码段是相同的,所以代码段是没必要复制的,只需内核将代码段标记为只读,父子进程就共享此代码段。fork() 之后在进程创建代码段时,子进程的进程级页表项都指向和父进程相同的物理页帧
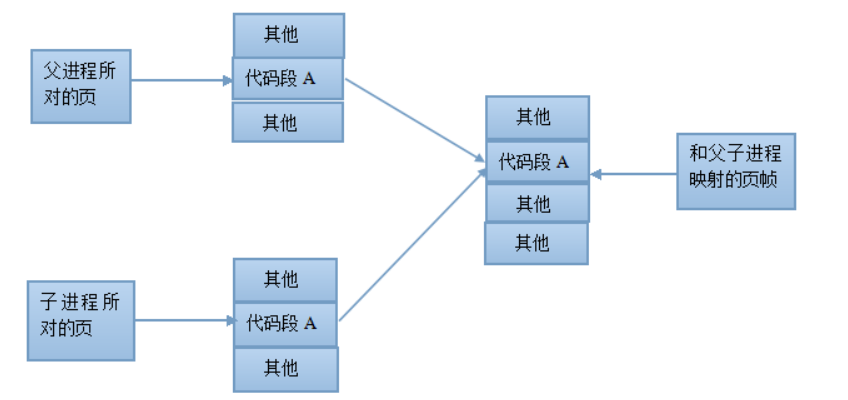
-
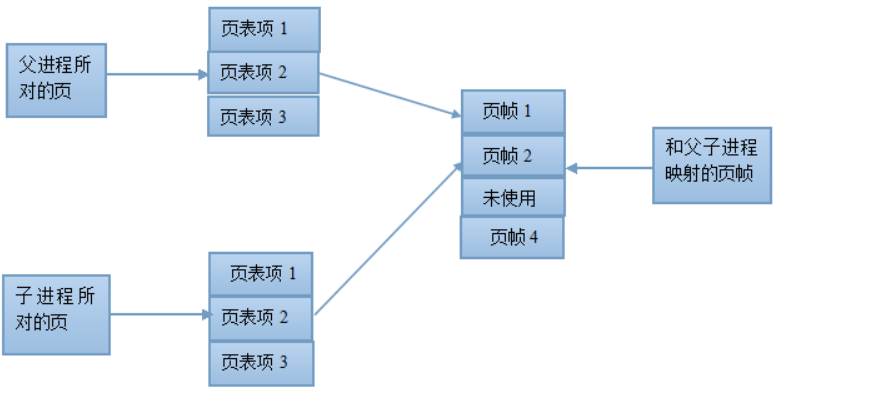
对于父进程的数据段,堆段,栈段中的各页,由于父子进程相互独立,采用写时复制 COW 的技术,来提高内存以及内核的利用率
在 fork 之后两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,两者的虚拟空间不同,但其对应的物理空间是同一个,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。如果两者的代码完全相同,代码段继续共享父进程的物理空间;而如果两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
fork 之后内核会将子进程放在队列的前面,让子进程先执行,以免父进程执行导致写时复制,而后子进程再执行,因无意义的复制而造成效率的下降
补充知识:
vfork(虚拟内存 fork virtual memory fork):调用 vfork() 父进程被挂起,子进程使用父进程的地址空间。不采用写时复制,如果子进程修改父地址空间的任何页面,这些修改过的页面对于恢复的父进程是可见的
参考文章:https://blog.csdn.net/Shreck66/article/details/47039937
事务机制
事务特征
Redis 事务就是将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务去执行其他的命令请求,会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求,Redis 事务的特性:
- Redis 事务没有隔离级别的概念,队列中的命令在事务没有提交之前都不会实际被执行
- Redis 单条命令式保存原子性的,但是事务不保证原子性,事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
工作流程
事务的执行流程分为三个阶段:
-
事务开始:MULTI 命令的执行标志着事务的开始,通过在客户端状态的 flags 属性中打开 REDIS_MULTI 标识,将执行该命令的客户端从非事务状态切换至事务状态
MULTI # 设定事务的开启位置,此指令执行后,后续的所有指令均加入到事务中 -
命令入队�:事务队列以先进先出(FIFO)的方式保存入队的命令,每个 Redis 客户端都有事务状态,包含着事务队列:
typedef struct redisClient {// 事务状态multiState mstate; /* MULTI/EXEC state */}typedef struct multiState {// 事务队列,FIFO顺序multiCmd *commands;// 已入队命令计数int count;}- 如果命令为 EXEC、DISCARD、WATCH、MULTI 四个命中的一个,那么服务器立即执行这个命令
- 其他命令服务器不执行,而是将命令放入一个事务队列里面,然后向客户端返回 QUEUED 回复
-
事务执行:EXEC 提交事务给服务器执行,服务器会遍历这个客户端的事务队列,执行队列中的命令并将执行结果返回
EXEC # Commit 提交,执行事务,与multi成对出现,成对使用
事务取消的方法:
-
取消事务:
DISCARD # 终止当前事务的定义,发生在multi之后,exec之前一般用于事务执行过程中输入了错误的指令,直接取消这次事务,类似于回滚
WATCH
监视机制
WATCH 命令是一个乐观锁(optimistic locking),可以在 EXEC 命令执行之前,监视任意数量的数据库键,并在 EXEC 命令执行时,检查被监视的键是否至少有一个已经被修改过了,如果是服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复
-
添加监控锁
WATCH key1 [key2……] #可以监控一个或者多个key -
取消对所有 key 的监视
UNWATCH
实现原理
每个 Redis 数据库都保存着一个 watched_keys 字典,键是某个被 WATCH 监视的数据库键,值则是一个链表,记录了所有监视相应数据库键的客户端:
typedef struct redisDb {
// 正在被 WATCH 命令监视的键
dict *watched_keys;
}
所有对数据库进行修改的命令,在执行后都会调用 multi.c/touchWatchKey 函数对 watched_keys 字典进行检查,是否有客户端正在监视刚被命令修改过的数据库键,如果有的话函数会将监视被修改键的客户端的 REDIS_DIRTY_CAS 标识打开,表示该客户端的事务安全性已经被破坏
服务器接收到个客户端 EXEC 命令时,会根据这个客户端是否打开了 REDIS_DIRTY_CAS 标识,如果打开了说明客户端提交事务不安全,服务器会拒绝执行
ACID
原子性
事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
原子性指事务队列中的命令要么就全部都执行,要么一个都不执行,但是在命令执行出错时,不会保证原子性(下一节详解)
Redis 不支持事务回滚机制(rollback),即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止
回滚需要程序员在代码中实现,应该尽可能避免:
-
事务操作之前记录数据的状态
-
单数据:string
-
多数据:hash、list、set、zset
-
-
设置指令恢复所有的被修改的项
-
单数据:直接 set(注意周边属性,例如时效)
-
多数据:修改对应值或整体克隆复制
-
一致性
事务具有一致性指的是,数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然是一致的
一致是数据符合数据库的定义和要求,没有包含非法或者无效的错误数据,Redis 通过错误检测和简单的设计来保证事务的一致性:
-
入队错误:命令格式输入错误,出现语法错误造成,整体事务中所有命令均不会执行,包括那些语法正确的命令
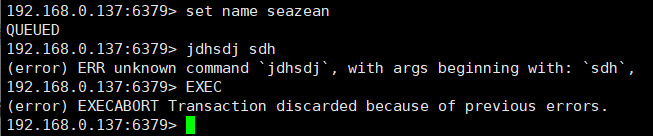
-
执行错误:命令执行出现错误,例如对字符串进行 incr 操作,事务中正确的命令会被执行,运行错误的命令不会被执行
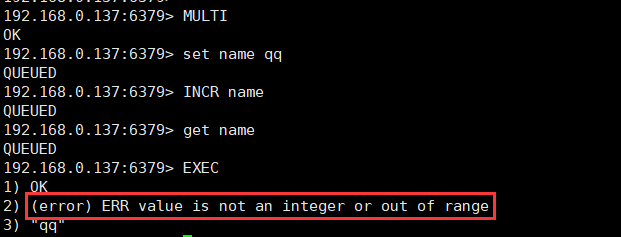
-
服务器停机:
- 如果服务器运行在无持久化的内存模式下,那么重启之后的数据库将是空白的,因此数据库是一致的
- 如果服务器运行在持久化模式下,重启之后将数据库还原到一致的状态
隔离性
Redis 是一个单线程的执行原理,所以对于隔离性,分以下两种情况:
- 并发操作在 EXEC 命令前执行,隔离性的保证要使用 WATCH 机制来实现,否则隔离性无法保证
- 并发操作在 EXEC 命令后执行,隔离性可以保证
持久性
Redis 并没有为事务提供任何额外的持久化功能,事务的持久性由 Redis 所使用的持久化模式决定
配置选项 no-appendfsync-on-rewrite 可以配合 appendfsync 选项在 AOF 持久化模式使用:
- 选项打开时在执行 BGSAVE 或者 BGREWRITEAOF 期间,服务器会暂时停止对 AOF 文件进行同步,从而尽可能地减少 I/O 阻塞
- 选项打开时运行在 always 模式的 AOF 持久化,事务也不具有持久性,所以该选项默认关闭
在一个事务的最后加上 SAVE 命令总可以保证事务的耐久性
Lua 脚本
环境创建
基本介绍
Redis 对 Lua 脚本支持,通过在服务器中嵌入 Lua 环境,客户端可以使用 Lua 脚本直接在服务器端原子地执行多个命令
EVAL <script> <numkeys> [key ...] [arg ...]
EVALSHA <sha1> <numkeys> [key ...] [arg ...]
EVAL 命令可以直接对输入的脚本计算:
redis> EVAL "return 1 + 1" 0 # 0代表需要的参数
(integer) 2
EVALSHA 命令根据脚本的 SHA1 校验和来对脚本计算:
redis> EVALSHA "2f3lba2bb6d6a0f42ccl59d2e2dad55440778de3" 0
(integer) 2
应用场景:Redis 只保证单条命令的原子性,所以为了实现原子操作,将多条的对 Redis 的操作整合到一个脚本里,但是避免把不需要做并发控制的操作写入脚本中
Lua 语法特点:
- 声明变量的时候无需指定数据类型,而是用 local 来声明变量为局部变量
- 数组下标是从 1 开始
创建过程
Redis 服务器创建并修改 Lua 环境的整个过程:
-
创建一个基础的 Lua 环境,调用 Lua 的 API 函数 lua_open
-
载入多个函数库到 Lua 环境里面,让 Lua 脚本可以使用这些函数库来进行数据操作,包括基础核心函数
-
创建全局变量 redis 表格,表格包含以下函数:
- 执行 Redis 命令的 redis.call 和 redis.pcall 函数
- 记录 Redis 日志的 redis.log 函数,以及相应的日志级别 (level) 常量 redis.LOG_DEBUG 等
- 计算 SHAl 校验和的 redis.shalhex 函数
- 返回错误信息的 redis.error_reply 函数和 redis.status_reply 函数
-
使用 Redis 自制的随机函数来替换 Lua 原有的带有副作用的随机函数,从而避免在脚本中引入副作用
Redis 要求所有传入服务器的 Lua 脚本,以及 Lua 环境中的所有函数,都必须是无副作用(side effect)的纯函数(pure function),所以对有副作用的随机函数
math.random和math.randornseed进行替换 -
创建排序辅助函数
_redis_compare_helper,使用辅助函数来对一部分 Redis 命令的结果进行排序,从而消除命令的不确定性比如集合元素的排列是无序的, 所以即使两个集合的元素完全相同,输出��结果也不一定相同,Redis 将 SMEMBERS 这类在相同数据集上产生不同输出的命令称为带有不确定性的命令
-
创建 redis.pcall 函数的错误报告辅助函数
_redis_err_handler,这个函数可以打印出错代码的来源和发生错误的行数 -
对 Lua 环境中的全局环境进行保护,确保传入服务器的脚本不会因忘记使用 local 关键字,而将额外的全局变量添加到 Lua 环境
-
将完成修改的 Lua 环境保存到服务器状态的 lua 属性中,等待执行服务器传来的 Lua 脚本
struct redisServer {Lua *lua;};
Redis 使用串行化的方式来执行 Redis 命令,所以在任何时间里最多都只会有一个脚本能够被放进 Lua 环境里面运行,因此整个 Redis 服务器只需要创建�一个 Lua 环境即可
协作组件
伪客户端
Redis 服务器为 Lua 环境创建了一个伪客户端负责处理 Lua 脚本中包含的所有 Redis 命令,工作流程:
- Lua 环境将 redis.call 或者 redis.pcall 函数想要执行的命令传给伪客户端
- 伪客户端将命令传给命令执行器
- 命令执行器执行命令并将命令的执行结果返回给伪客户端
- 伪客户端接收命令执行器返回的命令结果,并将结果返回给 Lua 环境
- Lua 将命令结果返回给 redis.call 函数或者 redis.pcall 函数
- redis.call 函数或者 redis.pcall 函数会将命令结果作为返回值返回给脚本的调用者
脚本字典
Redis 服务器为 Lua 环境创建 lua_scripts 字典,键为某个 Lua 脚本的 SHA1 校验和(checksum),值则是校验和对应的 Lua 脚本
struct redisServer {
dict *lua_scripts;
};
服务器会将所有被 EVAL 命令执行过的 Lua 脚本,以及所有被 SCRIPT LOAD 命令载入过的 Lua 脚本都保存到 lua_scripts 字典
redis> SCRIPT LOAD "return 'hi'"
"2f3lba2bb6d6a0f42ccl59d2e2dad55440778de3" # 字典的键,SHA1 校验和
命令实现
脚本函数
EVAL 命令的执行的第一步是为传入的脚本定义一个相对应的 Lua 函数,Lua 函数的名字由 f_ 前缀加上脚本的 SHA1 校验和(四十个字符长)组成,而函数的体(body)则是脚本本身
EVAL "return 'hello world'" 0
# 命令将会定义以下的函数
function f_533203lc6b470dc5a0dd9b4bf2030dea6d65de91() {
return 'hello world'
}
使用函数来保存客户端传入的脚本有以下优点:
- 通过函数的局部性来让 Lua 环境保持清洁,减少了垃圾回收的工作最, 并且避免了使用全局变量
- 如果某个脚本在 Lua 环境中被定义过至少一次,那么只需要 SHA1 校验和,服务器就可以在不知道脚本本身的情况下,直接通过调用 Lua 函数来执行脚本
EVAL 命令第二步是将客户端传入的脚本保存到服务器的 lua_scripts 字典里,在字典中新添加一个键值对
执行函数
EVAL 命令第三步是执行脚本函数
-
将 EVAL 命令中传入的键名参数和脚本参数分别保存到 KEYS 数组和 ARGV 数组,将这两个数组作为全局变量传入到 Lua 环境
-
为 Lua 环境装载超时处理钩子(hook),这个钩子可以在脚本出现超时运行情况时,让客户端通过
SCRIPT KILL命令停止脚本,或者通过 SHUTDOWN 命令直接关闭服务器因为 Redis 是单线程的执行命令,当 Lua 脚本阻塞�时需要兜底策略,可以中断执行
-
执行脚本函数
-
移除之前装载的超时钩子
-
将执行脚本函数的结果保存到客户端状态的输出缓冲区里,等待服务器将结果返回给客户端
EVALSHA
EVALSHA 命令的实现原理就是根据脚本的 SHA1 校验和来调用脚本对应的函数,如果函数在 Lua 环境中不存在,找不到 f_ 开头的函数,就会返回 SCRIPT NOT FOUND
管理命令
Redis 中与 Lua 脚本有关的管理命令有四个:
-
SCRIPT FLUSH:用于清除服务器中所有和 Lua 脚本有关的信息,会释放并重建 lua_scripts 字典,关闭现有的 Lua 环境并重新创建一个新的 Lua 环境
-
SCRIPT EXISTS:根据输入的 SHA1 校验和(允许一次传入多个校验和),检查校验和对应的脚本是否存在于服务器中,通过检查 lua_scripts 字典实现
-
SCRIPT LOAD:在 Lua 环境中为脚本创建相对应的函数,然后将脚本保存到 lua_scripts字典里
redis> SCRIPT LOAD "return 'hi'""2f3lba2bb6d6a0f42ccl59d2e2dad55440778de3" -
SCRIPT KILL:停止脚本
如果服务器配置了 lua-time-limit 选项,那么在每次执行 Lua 脚本之前,都会设置一个超时处理的钩子。钩子会在脚本运行期间会定期检查运行时间是否超过配置时间,如果超时钩子将定期在脚本运行的间隙中,查看是否有 SCRIPT KILL 或者 SHUTDOWN 到达:
- 如果超时运行的脚本没有执行过写入操作,客户端可以通过 SCRIPT KILL 来停止这个脚本
- 如果执行过写入操作,客户端只能用 SHUTDOWN nosave 命令来停止服务器,防止不合法的数据被写入数据库中
脚本复制
命令复制
当服务器运行在复制模式时,具有写性质的脚本命令也会被复制到从服务器,包括 EVAL、EVALSHA、SCRIPT FLUSH,以及 SCRIPT LOAD 命令
Redis 复制 EVAL、SCRIPT FLUSH、SCRIPT LOAD 三个命令的方法和复制普通 Redis 命令的方法一样,当主服务器执行完以上三个命令的其中一个时,会直接将被执行的命令传播(propagate)给所有从服务器,在从服务器中产生相同的效果
EVALSHA
EVALSHA 命令的复制操作相对复杂,因为多个从服务器之间载入 Lua 脚本的清况各有不同,一个在主服务器被成功执行的 EVALSHA 命令,在从服务器执行时可能会出现脚本未找到(not found)错误
Redis 要求主服务器在传播 EVALSHA 命令时,必须确保 EVALSHA 命令要执行的脚本已经被所有从服务器载入过,如果不能确保主服务器会将 EVALSHA 命令转换成一个等价的 EVAL 命令,然后通过传播 EVAL 命令来代替 EVALSHA 命令
主服务器使用服务器状态的 repl_scriptcache_dict 字典记录已经将哪些脚本传播给了所有从服务器,当一个校验和出现在字典时,说明校验和对应的 Lua 脚本已经传播给了所有从服务器,主服务器可以直接传播 EVALSHA 命令
struct redisServer {
// 键是一个个 Lua 脚本的 SHA1 校验和,值则全部都是 NULL
dict *repl_scriptcache_dict;
}
注意:每当主服务器添加一个新的从服务器时,都会清空 repl_scriptcache_dict 字典,因为字典里面记录的脚本已经不再被所有从服务器载入过,所以服务器以清空字典的方式,强制重新向所有从服务器传播脚本
通过使用 EVALSHA 命令指定的 SHA1 校验和,以及 lua_scripts 字典保存的 Lua 脚本,可以将一个 EVALSHA 命令转化为 EVAL 命令
EVALSHA "533203lc6b470dc5a0dd9b4bf2030dea6d65de91" 0
# -> 转换
EVAL "return'hello world'" 0
脚本内容 "return'hello world'" 来源于 lua_scripts 字典 533203lc6b470dc5a0dd9b4bf2030dea6d65de91 键的值
分布式锁
基本操作
在分布式场景下,锁变量需要由一个共享存储系统来维护,多个客户端才可以通过访问共享存储系统来访问锁变量,加锁和释放锁的操作就变成了读取、判断和设置共享存储系统中的锁变量值多步操作
Redis 分布式锁的基本使用,悲观锁
-
使用 SETNX 设置一个公共锁
SETNX lock-key value # value任意数,返回为1设置成功,返回为0设置失败NX:只在键不存在时,才对键进行设置操作,SET key value NX效果等同于SETNX key valueXX:只在键已经存在时,才对键进行设置操作EX:设置键 key 的过期时间,单位时秒PX:��设置键 key 的过期时间,单位时毫秒说明:由于
SET命令加上选项已经可以完全取代 SETNX、SETEX、PSETEX 的功能,Redis 不推荐使用这几个命令 -
操作完毕通过 DEL 操作释放锁
DEL lock-key -
使用 EXPIRE 为锁 key 添加存活(持有)时间,过期自动删除(放弃)锁,防止线程出现异常,无法释放锁
EXPIRE lock-key secondPEXPIRE lock-key milliseconds通过 EXPIRE 设置过期时间缺乏原子性,如果在 SETNX 和 EXPIRE 之间出现异常,锁也无法释放
-
在 SET 时指定过期时间,保证原子性
SET key value NX [EX seconds | PX milliseconds]
防误删
场景描述:线程 A 正在执行,但是业务阻塞,在锁的过期时间内未执行完成,过期删除后线程 B 重新获取到锁,此时线程 A 执行完成,删除锁,导致线程 B 的锁被线程 A 误删
SETNX 获取锁时,设置一个指定的唯一值(UUID),释放前获取这个值,判断是否自己的锁,防止出现线程之间误删了其他线程的锁
// 加锁, unique_value作为客户端唯一性的标识,
// PX 10000 则表示 lock_key 会在 10s 后过期,以免客户端在这期间发生异常而无法释放锁
SET lock_key unique_value NX PX 10000
Lua 脚本(unlock.script)实现的释放锁操作的伪代码:key 类型参数会放入 KEYS 数组,其它参数会放入 ARGV 数组,在脚本中通过 KEYS 和 ARGV 传递参数,保证判断标识和释放锁这两个操作的原子性
EVAL "return redis.call('set', KEYS[1], ARGV[1])" 1 lock_key unique_value # 1 代表需要一个参数
// 释放锁,KEYS[1] 就是锁的 key,ARGV[1] 就是标识值,避免误释放
// 获取标识值,判断是否与当前线程标示一致
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
优化锁
不可重入
不可重入:同一个线程无法多次获取同一把锁
使用 hash 键,filed 是加锁的线程标识, value 是锁重入次数
| key | value |
| | filed | value |
|-------------------------------|
| lock_key | thread1 | 1 |
锁重入:
- 加锁时判断锁的 filed 属性是否是当前线程,如果是将 value 加 1
- 解锁时判断锁的 filed 属性是否是当前线程,首先将 value 减一,如果 value 为 0 直接释放锁
使用 Lua 脚本保证多条命令的原子性
不可重试
不可重试:获取锁只尝试一次就返回 false,没有重试机制
- 利用 Lua 脚本尝试获取锁,获取失败获取锁的剩余超时时间 ttl,或者通过参数传入线程抢锁允许等待的时间
- 利用订阅功能订阅锁释放的信息,然后线程挂起等待 ttl 时间
- 利用 Lua 脚本在释放锁时,发布一条锁释放的消息
超时释放
超时释放:锁超时释放可以避免死锁,但如果是业务执行耗时较长,需要进行锁续时,防止业务未执行完提前释放锁
看门狗 Watch Dog 机制:
- 获取锁成功后,提交周期任务,每隔一段时间(Redisson 中默认为过期时间 / 3),重置一次超时时间
- 如果服务宕机,Watch Dog 机制线程就停止,就不会再延长 key 的过期时间
- 释放锁后,终止周期任务
主从一致
主从一致性:集群模式下,主从同步存在延迟,当加锁后主服务器宕机时,从服务器还没同步主服务器中的锁数据,此时从服务器升级为主服务器,其他线程又可以获取到锁
将服务器升级为多主多从:
- 获取锁需要从所有主服务器 SET 成功才算获取成功
- 某个 master 宕机,slave 还没有同步锁数据就升级为 master,其他线程尝试加锁会加锁失败,因为其他 master 上已经存在该锁
主从复制
基本操作
主从介绍
主从复制:一个服务器去复制另一个服务器,被复制的服务器为主服务器 master,复制的服务器为从服务器 slave
- master 用来写数据,执行写操作时,将出现变化的数据自动同步到 slave,很少会进行读取操作
- slave 用来读数据,禁止在 slave 服务器上进行读操作
进行复制中的主从服务器双方的数据库将保存相同的数据,将这种现象称作数据库状态一致
主从复制的特点:
-
薪火相传:一个 slave 可以是下一个 slave 的 master,slave 同样可以接收其他 slave 的连接和同步请求,那么该 slave 作为了链条中下一个的 master,可以有效减轻 master 的写压力,去中心化降低风险
注意:主机挂了,从机还是从机,无法写数据了
-
反客为主:当一个 master 宕机后,后面的 slave 可以立刻升为 master,其后面的 slave 不做任何修改
主从复制的作用:
- 读写分离:master 写、slave 读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由 slave 分担 master 负载,并根据需求的变化,改变 slave 的数量,通过多个从节点分担数据读取负载,大大提高 Redis 服务器并发量与数据吞吐量
- 故障恢复:当 master 出现问题时,由 slave 提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制,构建哨兵模式与集群,实现 Redis 的高可用方案
三高架构:
-
高并发:应用提供某一业务要能支持很多客户端同时访问的能力,称为并发
-
高性能:性能最直观的感受就是速度快,时间短
-
高可用:
- 可用性:应用服务在全年宕机的时间加在一起就是全年应用服务不可用的时间
- 业界可用性目标 5 个 9,即 99.999%,即服务器年宕机时长低于 315 秒,约 5.25 分钟
操作指令
系统状态指令:
INFO replication
master 和 slave 互连:
-
方式一:客户端发送命令,设置 slaveof 选项,产生主从结构
slaveof masterip masterport -
方式二:服务器带参启动
redis-server --slaveof masterip masterport -
方式三:服务器配置(主流方式)
slaveof masterip masterport
主从断开连接:
-
slave 断开连接后,不会删除已有数据,只是不再接受 master 发送的数据,可以作为从服务器升级为主服务器的指令
slaveof no one
授权访问:master 有服务端和客户端,slave 也有服务端和客户端,不仅服务端之间可以发命令,客户端也可以
-
master 客户端发送命令设置密码:
requirepass passwordmaster 配置文件设置密码:
config set requirepass passwordconfig get requirepass -
slave 客户端发送命令设置密码:
auth passwordslave 配置文件设置密码:
masterauth passwordslave 启动服务器设置密码:
redis-server –a password
复制流程
旧版复制
Redis 的复制功能分为同步(sync)和命令传播(command propagate)两个操作,主从库间的复制是异步进行的
同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态,该过程又叫全量复制:
- 从服务器向主服务器发送 SYNC 命令来进行同步
- 收到 SYNC 的主服务器执行 BGSAVE 命令,在后台生成一个 RDB 文件,并使用一个缓冲区记录从现在开始执行的所有写命令
- 当 BGSAVE 命令执行完毕时,主服务器会将 RDB 文件发送给从服务器
- 从服务接收并载入 RDB 文件(从服务器会清空原有数据)
- 缓冲区记录了 RDB 文件所在状态后的所有写命令,主服务器将在缓冲区的所有命令发送给从服务器,从服务器执行这些写命令
- 至此从服务器的数据库状态和主服务器一致
命令传播用于在主服务器的数据库状态被修改,导致主从数据库状态出现不一致时, 让主从服务器的数据库重新回到一致状态
- 主服务器会将自己执行的写命令,也即是造成主从服务器不一致的那条写命令,发送给从服务器
- 从服务器接受命令并执行,主从服务器将再次回到一致状态
功能缺陷
SYNC 本身就是一个非常消耗资源的操作,每次执行 SYNC 命令,都需要执行以下动作:
- 生成 RDB 文件,耗费主服务器大量 CPU 、内存和磁盘 I/O 资源
- RDB 文件发�送给从服务器,耗费主从服务器大量的网络资源(带宽和流量),并对主服务器响应命令请求的时间产生影响
- 从服务器载入 RDB 文件,期间会因为阻塞而没办法处理命令请求
SYNC 命令下的从服务器对主服务器的复制分为两种情况:
- 初次复制:从服务器没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同
- 断线后重复制:处于命令传播阶段的主从服务器因为网络原因而中断了复制,自动重连后并继续复制主服务器
旧版复制在断线后重复制时,也会创建 RDB 文件进行全量复制,但是从服务器只需要断线时间内的这部分数据,所以旧版复制的实现方式非常浪费资源
新版复制
Redis 从 2.8 版本开始,使用 PSYNC 命令代替 SYNC 命令来执行复制时的同步操作(命令传播阶段相同),解决了旧版复制在处理断线重复制情况的低效问题
PSYNC 命令具有完整重同步(full resynchronization)和部分重同步(partial resynchronization)两种模式:
- 完整重同步:处理初次复制情况,执行步骤和 SYNC命令基本一样
- 部分重同步:处理断线后重复制情况,主服务器可以将主从连接断开期间执行的写命令发送给从服务器,从服务器只要接收并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态,该过程又叫部分复制
部分同步
部分重同步功能由以下三个部分构成:
- 主服务器的复制偏移量(replication offset)和从服务器的复制偏移量
- 主服务器的复制积压缓冲区(replication backlog)
- 服务器的运行 ID (run ID)
偏移量
主服务器和从服务器会分别维护一个复制偏移量:
-
主服务器每次向从服务器传播 N 个字节的数据时,就将自己的复制偏移量的值加上 N
-
从服务器每次收到主服务器传播来的 N 个字节的数据时,就将自己的复制偏移量的值加上 N
通过对比主从服务器的复制偏移量,可以判断主从服务器是否处于一致状态
- 主从服务器的偏移量是相同的,说明主从服务器处于一致状态
- 主从服务器的偏移量是不同的,说明主从服务器处于不一致状态
缓冲区
复制积压缓冲区是由主服务器维护的一个固定长度(fixed-size)先进先出(FIFO)队列,默认大小为 1MB
- 出队规则跟普通的先进先出队列一样
- 入队规则是当入队元素的数量大于队列长度时,最先入队的元素会被弹出,然后新元素才会被放入队列
当主服务器进行命令传播时,不仅会将写命令发送给所有从服务器�,还会将写命令入队到复制积压缓冲区,缓冲区会保存着一部分最近传播的写命令,并且缓冲区会为队列中的每个字节记录相应的复制偏移量

从服务器会通过 PSYNC 命令将自己的复制偏移量 offset 发送给主服务器,主服务器会根据这个复制偏移量来决定对从服务器执行何种同步操作:
- offset 之后的数据(即 offset+1)仍然存在于复制积压缓冲区里,那么主服务器将对从服务器执行部分重同步操作
- offset 之后的数据已经不在复制积压缓冲区,说明部分数据已经丢失,那么主服务器将对从服务器执行完整重同步操作
复制缓冲区大小设定不合理,会导致数据溢出。比如主服务器需要执行大量写命令,又或者主从服务器断线后重连接所需的时间较长,导致缓冲区中的数据已经丢失,则必须进行完整重同步
repl-backlog-size ?mb
建议设置如下,这样可以保证绝大部分断线情况都能用部分重同步来处理:
- 从服务器断线后重新连接上主服务器所需的平均时间 second
- 获取 master 平均每秒产生写命令数据总量 write_size_per_second
- 最优复制缓冲区空间 = 2 * second * write_size_per_second
运行ID
服务器运行 ID(run ID):是每一台服务器每次运行的身份识别码,在服务器启动时自动生成,由 40 位随机的十六进制字符组成,一台服务器多次运行可以生成多个运行 ID
作用:服务器间进行传输识别身份,如果想两次操作均对同一台服务器进行,每次必须操作携带对应的运行 ID,用于对方识别
从服务器对主服务器进行初次复制时,主服务器将自己的运行 ID 传送给从服务器,然后从服务器会将该运行 ID 保存。当从服务器断线并重新连上一个主服务器时,会向当前连接的主服务器发送之前保存的运行 ID:
- 如果运行 ID 和当前连接的主服务器的运行 ID 相同,说明从服务器断线之前复制的就是当前连接的这个主服务器,执行部分重同步
- 如果不同,需要执行完整重同步操作
PSYNC
PSYNC 命令的调用方法有两种
- 如果从服务器之前没有复制过任何主服务器,或者执行了
SLAVEOF no one,开始一次新的复制时将向主服务器发送PSYNC ? -1命令,主动请求主服务器进行完整重同步 - 如果从服务器已经复制过某个主服务器,那么从服务器在开始一次新的复制时将向主服务器发送
PSYNC <runid> <offset>命令,runid 是上一次复制的主服务器的运行 ID,offset 是复制的偏移量
接收到 PSYNC 命令的主服务器会�向从服务器返回以下三种回复的其中一种:
- 执行完整重同步操作:返回
+FULLRESYNC <runid> <offset>,runid 是主服务器的运行 ID,offset 是主服务器的复制偏移量 - 执行部分重同步操作:返回
+CONTINUE,从服务器收到该回复说明只需要等待主服务器发送缺失的部分数据即可 - 主服务器的版本低于 Redis2.8:返回
-ERR,版本过低识别不了 PSYNC,从服务器将向主服务器发送 SYNC 命令
复制实现
实现流程
通过向从服务器发送 SLAVEOF 命令,可以让从服务器去复制一个主服务器
-
设置主服务器的地址和端口:将 SLAVEOF 命令指定的 ip 和 port 保存到服务器状态 redisServer
struct redisServer {// 主服务器的地址char *masterhost;//主服务器的端口int masterport;};SLAVEOF 命令是一个异步命令,在完成属性的设置后服务器直接返回 OK,而实际的复制工作将在 OK 返回之后才真正开始执行
-
建立套接字连接:
- 从服务器 connect 主服务器建立套接字连接,成功后从服务器将为这个套接字关联一个用于复制工作的文件事件处理器,负责执行后续的复制工作,如接收 RDB 文件、接收主服务器传播来的写命令等
- 主服务器在接受 accept 从务器的套接字连接后,将为该套接字创建相应的客户端状态,将从服务器看作一个客户端,从服务器将同时具有 server 和 client(可以发命令)两个身份
-
发送 PING 命令:从服务器向主服务器发送一个 PING 命令,检查主从之间的通信是否正常、主服务器处理命令的能力是否正常
- 返回错误,表示主服务器无法处理从服务器的命令请求(忙碌),从服务器断开并重新创建连向主服务器的套接字
- 返回命令回复,但从服务器不能在规定的时间内读取出命令回复的内容,表示主从之间的网络状态不佳,需要断开重连
- 读取到 PONG,表示一切状态正常,可以执行复制
-
身份验证:如果从服务器设置了 masterauth 选项就进行身份验证,将向主服务器发送一条 AUTH 命令,命令参数为从服务器 masterauth 选项的值,如果主从设置的密码不相同,那么主将返回一个 invalid password 错误
-
发送端口信息:身份验证后
- 从服务器执行命令
REPLCONF listening-port <portnumber>, 向主服务器发送从服务器的监听端口号 - 主服务器在接收到这个命令后,会将端口号记录在对应的客户端状态 redisClient.slave_listening_port 属性中:
- 从服务器执行命令
-
同步:从服务器将向主服务器发送 PSYNC 命令,在同步操作执行之后,主从服务器双方都是对方的客户端,可以相互发送命令
-
完整重同步:主服务器需要成为从服务器的客户端,才能将保存在缓冲区里面的写命令发送给从服务器执行
-
部分重同步:主服务器需要成为从服务器的客户端,才能向从服务器发送保存在复制积压缓冲区里面的写命令
-
-
命令传播:主服务器将写命令发送给从服务器,保持数据库的状态一致
复制图示

心跳检测
心跳机制
心跳机制:进入命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令:REPLCONF ACK <replication_offset>,replication_offset 是从服务器当前的复制偏移量
心跳的作用:
- 检测主从服务器的网络连接状态
- 辅助实现 min-slaves 选项
- 检测命令丢失
网络状态
如果主服务器超过一秒钟没有收到从服务器发来的 REPLCONF ACK 命令,主服务就认为主从服务器之间的连接出现问题
向主服务器发送 INFO replication 命令,lag 一栏表示从服务器最后一次向主服务器发送 ACK 命令距离现在多少秒:
127.0.0.1:6379> INFO replication
# Replication
role:master
connected_slaves:2
slave0: ip=127.0.0.1,port=11111,state=online,offset=123,lag=0 # 刚刚发送过 REPLCONF ACK
slavel: ip=127.0.0.1,port=22222,state=online,offset=456,lag=3 # 3秒之前发送过REPLCONF ACK
在一般情况下,lag 的值应该在 0 或者 1 秒之间跳动,如果超过 1 秒说明主从服务器之间的连接出现了故障
配置选项
Redis 的 min-slaves-to-write 和 min-slaves-max-lag 两个选项可以防止主服务器在不安全的情况下拒绝执行写命令
比如向主服务器设置:
- min-slaves-to-write:主库最少有 N 个健康的从库存活才能执行写命令,没有足够的从库直接拒绝写入
- min-slaves-max-lag:从库和主库进行数据复制时的 ACK 消息延迟的最大时间
min-slaves-to-write 5
min-slaves-max-lag 10
那么在从服务器的数少于 5 个,或者 5 个从服务器的延迟(lag)值都大于或等于10 秒时,主服务器将拒绝执行写命令
命令丢失
检测命令丢失:由于网络或者其他原因,主服务器传播给从服务器的写命令丢失,那么当从服务器向主服务器发送 REPLCONF ACK 命令时,主服务器会检查从服务器的复制偏移量是否小于自己的,然后在复制积压缓冲区里找到从服务器缺少的数据,并将这些数据重新发送给从服务器
说明:REPLCONF ACK 命令和复制积压缓冲区都是 Redis 2.8 版本新增的,在 Redis 2.8 版本以前,即使命令在传播过程中丢失,主从服务器都不会注意到,也不会向从服务器补发丢失的数据,所以为了保证主从复制的数据一致性,最好使用 2.8 或以上版本的 Redis
常见问题
重启恢复
系统不断运行,master 的数据量会越来越大,一旦 master 重启,runid 将发生变化,会导致全部 slave 的全量复制操作
解决方法:本机保存上次 runid,重启后恢复该值,使所有 slave 认为还是之前的 master
优化方案:
-
master 内部创建 master_replid 变量,使用 runid 相同的策略生成,并发送给所有 slave
-
在 master 关闭时执行命令
shutdown save,进行 RDB 持久化,将 runid 与 offset 保存到 RDB 文件中redis-check-rdb dump.rdb命令可以查看该信息,保存为 repl-id 和 repl-offset -
master 重启后加载 RDB 文件,恢复数据,将 RDB 文件中保存的 repl-id 与 repl-offset 加载到内存中,master_repl_id = repl-id,master_repl_offset = repl-offset
-
通过 info 命令可以查看该信息
网络中断
master 的 CPU 占用过高或 slave 频繁断开连接
-
出现的原因:
- slave 每 1 秒发送 REPLCONF ACK 命令到 master
- 当 slave 接到了慢查询时(keys * ,hgetall 等),会大量占用 CPU 性能
- master 每 1 秒调用复制定时函数 replicationCron(),比对 slave 发现长时间没有进行响应
最终导致 master 各种资源(输出缓冲区、带宽、连接等)被严重占用
-
解决方法:通过设置合理的超时时间,确认是否释放 slave
repl-timeout # 该参数定义了超时时间的阈值(默认60秒),超过该值,释放slave
slave 与 master 连接断开
-
出现的原因:
- master 发送 ping 指令频度较低
- master 设定超时时间较短
- ping 指令在网络中存在丢包
-
解决方法:提高 ping 指令发送的频度
repl-ping-slave-period超时时间 repl-time 的时间至少是 ping 指令频度的5到10倍,否则 slave 很容易判定超时
一致性
网络信息不同步,数据发送有延迟,导致多个 slave 获取相同数据不同步
解决方案:
-
优化主从间的网络环境,通常放置在同一个机房部署,如使用阿里云等云服务器时要注意此现象
-
监控主从节点延迟(通过offset)判断,如果 slave 延迟过大,暂时屏��蔽程序对该 slave 的数据访问
slave-serve-stale-data yes|no开启后仅响应 info、slaveof 等少数命令(慎用,除非对数据一致性要求很高)
-
多个 slave 同时对 master 请求数据同步,master 发送的 RDB 文件增多,会对带宽造成巨大冲击,造成 master 带宽不足,因此数据同步需要根据业务需求,适量错峰
哨兵模式
哨兵概述
Sentinel(哨兵)是 Redis 的高可用性(high availability)解决方案,由一个或多个 Sentinel 实例 instance 组成的 Sentinel 系统可以监视任意多个主服务器,以及这些主服务器的所有从服务器,并在被监视的主服务器下线时进行故障转移
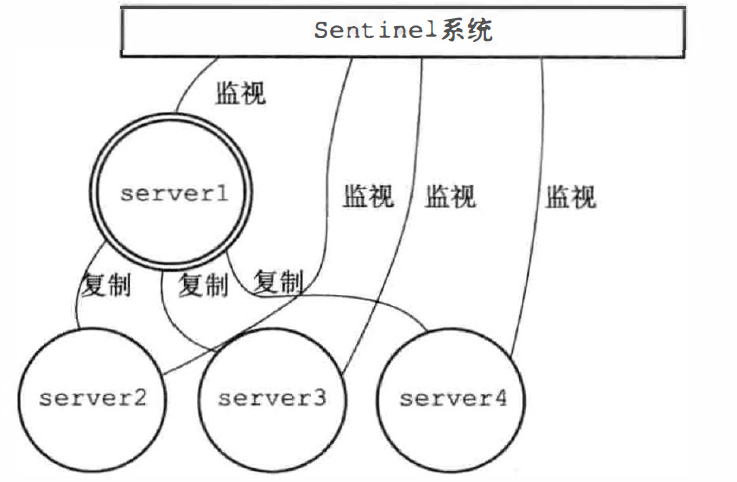
- 双环图案表示主服务器
- �单环图案表示三个从服务器
哨兵的作用:
-
监控:监控 master 和 slave,不断的检查 master 和 slave 是否正常运行,master 存活检测、master 与 slave 运行情况检测
-
通知:当被监控的服务器出现问题时,向其他哨兵发送通知
-
自动故障转移:断开 master 与 slave 连接,选取一个 slave 作为 master,将其他 slave 连接新的 master,并告知客户端新的服务器地址
启用哨兵
配置方式
配置三个哨兵 sentinel.conf:一般多个哨兵配置相同、端口不同,特殊需求可以配置不同的属性
port 26401
dir "/redis/data"
sentinel monitor mymaster 127.0.0.1 6401 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 20000
sentinel parallel-sync mymaster 1
sentinel deny-scripts-reconfig yes
配置说明:
-
设置哨兵监听的主服务器信息,判断主观下线所需要的票数
sentinel monitor <master-name> <master_ip> <master_port> <quorum> -
指定哨兵在监控 Redis 服务时,设置判定服务器宕机的时长,该设置控制是否进行主从切换
sentinel down-after-milliseconds <master-name> <million_seconds> -
出现故障后,故障切换的最大超时时间,超过该值,认定切换失败,默认 3 分钟
sentinel failover-timeout <master_name> <million_seconds> -
故障转移时,同时进行主从同步的 slave 数量,数值越大,要求网络资源越高
sentinel parallel-syncs <master_name> <sync_slave_number>
启动哨兵:服务端命令(Linux 命令)
redis-sentinel filename
初始化
Sentinel 本质上只是一个运行在特殊模式下的 Redis 服务器,当一个 Sentinel 启动时,首先初始化 Redis 服务器,但是初始化过程和普通 Redis 服务器的初始化过程并不完全相同,哨兵不提供数据相关服务,所以不会载入 RDB、AOF 文件
整体流程:
-
初始化服务器
-
将普通 Redis 服务器使用的代码替换成 Sentinel 专用代码
-
初始化 Sentinel 状态
-
根据给定的配置文件,初始化 Sentinel 的监视主服务器列表
-
创建连向主服务器的网络连接
代码替换
将一部分普通 Redis 服务器使用的代码替换成 Sentinel 专用代码
Redis 服务器端口:
# define REDIS_SERVERPORT 6379 // 普通服务器端口
# define REDIS_SENTINEL_PORT 26379 // 哨兵端口
服务器的命令表:
// 普通 Redis 服务器
struct redisCommand redisCommandTable[] = {
{"get", getCommand, 2, "r", 0, NULL, 1, 1, 1, 0, 0},
{"set", setCommand, -3, "wm", 0, noPreloadGetKeys, 1, 1, 1, 0, 0},
//....
}
// 哨兵
struct redisCommand sentinelcmds[] = {
{"ping", pingCommand, 1, "", 0, NULL, 0, 0, 0, 0, 0},
{"sentinel", sentinelCommand, -2,"",0,NULL,0,0,0,0,0},
{"subscribe",...}, {"unsubscribe",...O}, {"psubscribe",...}, {"punsubscribe",...},
{"info",...}
};
上述表是哨兵模式下客户端可以执行的命令,所以对于 GET、SET 等命令,服务器根本就没有载入
哨兵状态
服务器会初始化一个 sentinelState 结构,又叫 Sentinel 状态,结构保存了服务器中所有和 Sentinel 功能有关的状态(服务器的一般状态仍然由 redisServer 结构保存)
struct sentinelState {
// 当前纪元,用于实现故障转移
uint64_t current_epoch;
// 【保存了所有被这个sentinel监视的主服务器】
dict *masters;
// 是否进入了 TILT 模式
int tilt;
// 进入 TILT 模式的时间
mstime_t tilt_start_time;
// 最后一次执行时间处理的事件
mstime_t previous_time;
// 目前正在执行的脚本数�量
int running_scripts;
// 一个FIFO队列,包含了所有需要执行的用户脚本
list *scripts_queue;
} sentinel;
监控列表
Sentinel 状态的初始化将 masters 字典的初始化,根据被载入的 Sentinel 配置文件 conf 来进行属性赋值
Sentinel 状态中的 masters 字典记录了所有被 Sentinel 监视的主服务器的相关信息,字典的键是被监视主服务器的名字,值是主服务器对应的实例结构
实例结构是一个 sentinelRedisinstance 数据类型,代表被 Sentinel 监视的实例,这个实例可以是主、从服务器,或者其他 Sentinel
typedef struct sentinelRedisinstance {
// 标识值,记录了实例的类型,以及该实例的当前状态
int flags;
// 实例的名字,主服务器的名字由用户在配置文件中设置,
// 从服务器和哨兵的名字由 Sentinel 自动设置,格式为 ip:port,例如 127.0.0.1:6379
char *name;
// 实例运行的 ID
char *runid;
// 配置纪元,用于实现故障转移
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 如果当前实例时主服务器,该字段保存从服务器信息,键是名字格式为 ip:port,值是实例结构
dict *slaves;
// 所有监视当前服务器的 Sentinel 实例,键是名字格式为 ip:port,值是实例结构
dict *sentinels;
// sentinel down-after-milliseconds 的值,表示实例无响应多少毫秒后会被判断为主观下线(subjectively down)
mstime_t down_after_period;
// sentinel monitor 选项中的quorum参数,判断这个实例为客观下线(objectively down)所需的支持投票数量
int quorum;
// sentinel parallel-syncs 的值,在执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量
int parallel-syncs;
// sentinel failover-timeout的值,刷新故障迁移状态的最大时限
mstime_t failover_timeout;
}
addr 属性是一个指向 sentinelAddr 的指针:
typedef struct sentinelAddr {
char *ip;
int port;
}
网络连接
初始化 Sentinel 的最后一步是创建连向被监视主服务器的网络连接,Sentinel 将成为主服务器的客户端,可以向主服务器发送命令,并从命令回复中获取相关的信息
每个被 Sentinel 监视的主服务器,Sentinel 会创建两个连向主服务器的异步网络连接:
- 命令连接:用于向主服务器发送命令,并接收命令回复
- 订阅连接:用于订阅主服务器的
_sentinel_:hello频道
建立两个连接的原因:
-
在 Redis 目前的发布与订阅功能中,被发送的信息都不会保存在 Redis 服务器里, 如果在信息发送时接收信息的客户端离线或断线,那么这个客户端就会丢失这条信息,为了不丢失 hello 频道的任何信息,Sentinel 必须用一个订阅连接来接收该频道的信息
-
Sentinel 还必须向主服务器发送命令,以此来与主服务器进行通信,所以 Sentinel 还必须向主服务器创建命令连接
说明:断线的意思就是网络连接断开
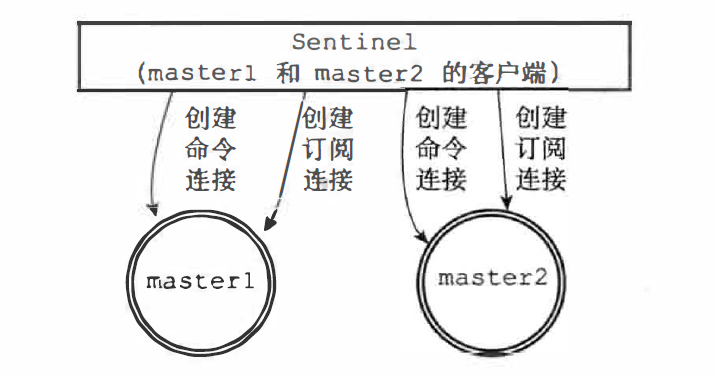
信息交互
获取信息
主服务器
Sentinel 默认会以每十秒一次的频率,通过命令连接向被监视的主服务器发送 INFO 命令,来获取主服务器的信息
- 一部分是主服务器本身的信息,包括 runid 域记录的服务器运行 ID,以及 role 域记录的服务器角色
- 另一部分是服务器属下所有从服务器的信息,每个从服务器都由一个 slave 字符串开头的行记录,根据这些 IP 地址和端口号,Sentinel 无须用户提供从服务器的地址信息,就可以自动发现从服务器
# Server
run_id:76llc59dc3a29aa6fa0609f84lbb6al019008a9c
...
# Replication
role:master
...
slave0: ip=l27.0.0.1, port=11111, state=online, offset=22, lag=0
slave1: ip=l27.0.0.1, port=22222, state=online, offset=22, lag=0
...
根据 run_id 和 role 记录的信息 Sentinel 将对主服务器的实例结构进行更新,比如主服务器重启之后,运行 ID 就会和实例结构之前保存的运行 ID 不同,哨兵检测到这一情况之后就会对实例结构的运行 ID 进行更新
对于主服务器返回的从服务器信息,用实例结构的 slaves 字典记录了从服务器的信息:
- 如果从服务器对应的实例结构已经存在,那么 Sentinel 对从服务器的实例结构进行更新
- 如果不存在,为这个从服务器新创建一个实例结构加入字典,字典键为
ip:port
从服务器
当 Sentinel 发现主服务器有新的从服务器出现时,会为这个新的从服务器创建相应的实例结构,还会创建到从服务器的命令连接和订阅连接,所以 Sentinel 对所有的从服务器之间都可以进行命令操作
Sentinel 默认会以每十秒一次的频率,向从服务器发送 INFO �命令:
# Server
run_id:76llc59dc3a29aa6fa0609f84lbb6al019008a9c #从服务器的运行 id
...
# Replication
role:slave # 从服务器角色
...
master_host:127.0.0.1 # 主服务器的 ip
master_port:6379 # 主服务器的 port
master_link_status:up # 主从服务器的连接状态
slave_repl_offset:11111 # 从服务器的复制偏移蜇
slave_priority:100 # 从服务器的优先级
...
- 优先级属性在故障转移时会用到
根据这些信息,Sentinel 会对从服务器的实例结构进行更新
发送信息
Sentinel 在默认情况下,会以每两秒一次的频率,通过命令连接向所有被监视的主服务器和从服务器发送以下格式的命令:
PUBLISH _sentinel_:hello "<s_ip>, <s_port>, <s_runid>, <s_epoch>, <m_name>, <m_ip>, <m_port>, <m_epoch>
这条命令向服务器的 _sentinel_:hello 频道发送了一条信息,信息的内容由多个参数组成:
- 以 s_ 开头的参数记录的是 Sentinel 本身的信息
- 以 m_ 开头的参数记录的则是主服务器的信息
说明:通过命令连接发送的频道信息
接受信息
订阅频道
Sentinel 与一个主或从服务器建立起订阅连接之后,就会通过订阅连接向服务器发送订阅命令,频道的订阅会一直持续到 Sentinel 与服务器的连接断开为止
SUBSCRIBE _sentinel_:hello
订阅成功后,Sentinel 就可以通过订阅连接从服务器的 _sentinel_:hello 频道接收信息,对消息分析:
- 如果信息中记录的 Sentinel 运行 ID 与自己的相同,不做进一步处理
- 如果不同,将根据信息中的各个参数,对相应主服务器的实例结构进行更新
Sentinel 为主服务器创建的实例结构的 sentinels 字典保存所有同样监视这个主服务器的 Sentinel 信息(包括 Sentinel 自己),字典的键是 Sentinel 的名字,格式为 ip:port,值是键所对应 Sentinel 的实例结构
监视同一个服务器的 Sentinel 订阅的频道相同,Sentinel 发送的信息会被其他 Sentinel 接收到(发送信息的为源 Sentinel,接收信息的为目标 Sentinel),目标 Sentinel 在自己的 sentinelState.masters 中查找源 Sentinel 服务器的实例结构进行添加或更新
因为 Sentinel 可以接收�到的频道信息来感知其他 Sentinel 的存在,并通过发送频道信息来让其他 Sentinel 知道自己的存在,所以用户在使用 Sentinel 时并不需要提供各个 Sentinel 的地址信息,监视同一个主服务器的多个 Sentinel 可以相互发现对方
哨兵实例之间可以相互发现,要归功于 Redis 提供发布订阅机制
命令连接
Sentinel 通过频道信息发现新的 Sentinel,除了创建实例结构,还会创建一个连向新 Sentinel 的命令连接,而新 Sentinel 也同样会创建连向这个 Sentinel 的命令连接,最终监视同一主服务器的多个 Sentinel 将形成相互连接的网络
作用:通过命令连接相连的各个 Sentinel 可以向其他 Sentinel 发送命令请求来进行信息交换
Sentinel 之间不会创建订阅连接:
- Sentinel 需要通过接收主服务器或者从服务器发来的频道信息来发现未知的新 Sentinel,所以才创建订阅连接
- 相互已知的 Sentinel 只要使用命令连接来进行通信就足够了
下线检测
主观下线
Sentinel 在默认情况下会以每秒一次的频率向所有与它创建了命令连接的实例(包括主从服务器、其他 Sentinel)发送 PING 命令,通过实例返回的 PING �命令回复来判断实例是否在线
- 有效回复:实例返回 +PONG、-LOADING、-MASTERDOWN 三种回复的其中一种
- 无效回复:实例返回除上述三种以外的任何数据
Sentinel 配置文件中 down-after-milliseconds 选项指定了判断实例进入主观下线所需的时长,如果主服务器在该时间内一直向 Sentinel 返回无效回复,Sentinel 就会在该服务器对应实例结构的 flags 属性打开 SRI_S_DOWN 标识,表示该主服务器进入主观下线状态
配置的 down-after-milliseconds 值不仅适用于主服务器,还会被用于当前 Sentinel 判断主服务器属下的所有从服务器,以及所有同样监视这个主服务器的其他 Sentinel 的主观下线状态
注意:对于监视同一个主服务器的多个 Sentinel 来说,设置的 down-after-milliseconds 选项的值可能不同,所以当一个 Sentinel 将主服务器判断为主观下线时,其他 Sentinel 可能仍然会认为主服务器处于在线状态
客观下线
当 Sentinel 将一个主服务器判断为主观下线之后,会向同样监视这一主服务器的其他 Sentinel 进行询问
Sentinel 使用命令询问其他 Sentinel 是否同意主服务器已下线:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
- ip:被 Sentinel 判断为主观下线的主服务器的 IP 地址
- port:被 Sentinel 判断为主观下线的主服务器的端口号
- current_epoch:Sentinel 当前的配置纪元,用于选举领头 Sentinel
- runid:取值为 * 符号代表命令仅仅用于检测主服务器的客观下线状态;取值为 Sentinel 的运行 ID 则用于选举领头 Sentinel
目标 Sentinel 接收到源 Sentinel 的命令时,会根据参数的 lP 和端口号,检查主服务器是否已下线,然后返回一条包含三个参数的 Multi Bulk 回复:
- down_state:返回目标 Sentinel 对服务器的检查结果,1 代表主服务器已下线,0 代表未下线
- leader_runid:取值为 * 符号代表命令仅用于检测服务器的下线状态;而局部领头 Sentinel 的运行 ID 则用于选举领头 Sentinel
- leader_epoch:目标 Sentinel 的局部领头 Sentinel 的配置纪元
源 Sentinel 将统计其他 Sentinel 同意主服务器已下线的数量,当这一数量达到配置指定的判断客观下线所需的数量(quorum)时,Sentinel 会将主服务器对应实例结构 flags 属性的 SRI_O_DOWN 标识打开,代表客观下��线,并对主服务器执行故障转移操作
注意:不同 Sentinel 判断客观下线的条件可能不同,因为载入的配置文件中的属性 quorum 可能不同
领头选举
主服务器被判断为客观下线时,监视该主服务器的各个 Sentinel 会进行协商,选举出一个领头 Sentinel 对下线服务器执行故障转移
Redis 选举领头 Sentinel 的规则:
-
所有在线的 Sentinel 都有被选为领头 Sentinel 的资格
-
每个发现主服务器进入客观下线的 Sentinel 都会要求其他 Sentinel 将自己设置为局部领头 Sentinel
-
在一个配置纪元里,所有 Sentinel 都只有一次将某个 Sentinel 设置为局部领头 Sentinel 的机会,并且局部领头一旦设置,在这个配置纪元里就不能再更改
-
Sentinel 设置局部领头 Sentinel 的规则是先到先得,最先向目标 Sentinel 发送设置要求的源 Sentinel 将成为目标 Sentinel 的局部领头 Sentinel,之后接收到的所有设置要求都会被目标 Sentinel 拒绝
-
领头 Sentinel 的产生需要半数以上 Sentinel 的支持,并且每个 Sentinel 只有一票,所以一个配置纪元只会出现一个领头 Sentinel,比如 10 个 Sentinel 的系统中,至少需要
10/2 + 1 = 6票
选举过程:
- 一个 Sentinel 向目标 Sentinel 发送
SENTINEL is-master-down-by-addr命令,命令中的 runid 参数不是*符号而是源 Sentinel 的运行 ID,表示源 Sentinel 要求目标 Sentinel 将自己设置为它的局部领头 Sentinel - 目标 Sentinel 接受命令处理完成后,将返回一条命令回复,回复中的 leader_runid 和 leader_epoch 参数分别记录了目标 Sentinel 的局部领头 Sentinel 的运行 ID 和配置纪元
- 源 Sentinel 接收目标 Sentinel 命令回复之后,会判断 leader_epoch 是否和自己的相同,相同就继续判断 leader_runid 是否和自己的运行 ID 一致,成立表示目标 Sentinel 将源 Sentinel 设置成了局部领头 Sentinel,即获得一票
- 如果某个 Sentinel 被半数以上的 Sentinel 设置成了局部领头 Sentinel,那么这个 Sentinel 成为领头 Sentinel
- 如果在给定时限内,没有一个 Sentinel 被选举为领头 Sentinel,那么各个 Sentinel 将在一段时间后再次选举,直到选出领头
- 每次进行领头 Sentinel 选举之后,不论选举是否成功,所有 Sentinel 的配置纪元(configuration epoch)都要自增一次
Sentinel 集群至少 3 个节点的原因:
- 如果 Sentinel 集群只有 2 个 Sentinel 节点,则领头选举需要
2/2 + 1 = 2票,如果一个节点挂了,那就永远选不出领头 - Sentinel 集群允许 1 个 Sentinel 节点故障则需要 3 个节点的集群,允许 2 个节点故障则需要 5 个节点集群
如何获取哨兵节点的半数数量?
- 客观下线是通过配置文件获取的数量,达到 quorum 就客观下线
- 哨兵数量是通过主节点是实例结构中,保存着监视该主节点的所有哨兵信息,从而获取得到
故障转移
执行流程
领头 Sentinel 将对已下线的主服务器执行故障转移操作,该操作包含以下三个步骤
-
从下线主服务器属下的所有从服务器里面,挑选出一个从服务器,执行
SLAVEOF no one,将从服务器升级为主服务器在发送 SLAVEOF no one 命令后,领头 Sentinel 会以每秒一次的频率(一般是 10s/次)向被升级的从服务器发送 INFO 命令,观察命令回复中的角色信息,当被升级服务器的 role 从 slave 变为 master 时,说明从服务器已经顺利升级为主服务器
-
将已下线的主服务器的所有从服务器改为复制新的主服务器,通过向从服务器发送 SLAVEOF 命令实现
-
将已经下线的主服务器设置为新的主服务器的从服务器,设置是保存在服务器对应的实例结构中,当旧的主服务器重新上线时,Sentinel 就会向它发送 SLAVEOF 命令,成为新的主服务器的从服务器
示例:sever1 是主,sever2、sever3、sever4 是从服务器,sever1 故障后选中 sever2 升级
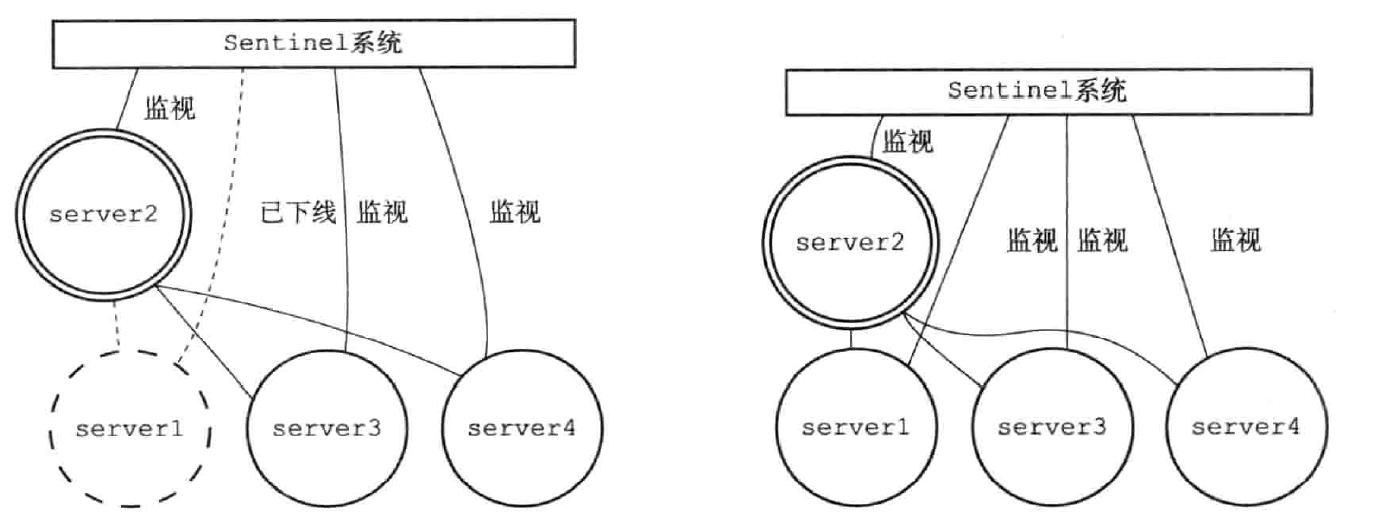
选择算法
领头 Sentinel 会将已下线主服务器的所有从服务器保存到一个列表里,然后按照以下规则对列表进行过滤,最后挑选出一个状态良好、数据完整的从服务器
-
删除列表中所有处于下线或者断线状态的从服务器,保证列表中的从服务器都是正常在线的
-
删除列表中所有最近五秒内没有回复过领头 Sentinel 的 INFO 命令的从服务器,保证列表中的从服务器最近成功进行过通信
-
删除所有与已下线主服务器连接断开超过
down-after-milliseconds * 10毫秒的从服务器,保证列表中剩余的从服务器都没有过早地与主服务器断开连接,保存的数据都是比较新的down-after-milliseconds 时间用来判断是否主观下线,其余的时间完全可以完成客观下线和领头选举
-
根据从服务器的优先级,对列表中剩余的从服务器进行排序,并选出其中优先级最高的从服务器
-
如果有多个具有相同最高优先级的从服务器,领头 Sentinel 将对这些相同优先级的服务器按照复制偏移量进行排序,选出其中偏移量最大的从服务器,也就是保存着最新数据的从服务器
-
如果还没选出来,就按照运行 ID 对这些从服务器进行排序,并选出其中运行 ID 最小的从服务器
集群模式
集群节点
节点概述
Redis 集群是 Redis 提供的分布式数据库方案,集群通过分片(sharding)来进行数据共享, 并提供复制和故障转移功能,一个 Redis 集群通常由多个节点(node)组成,将各个独立的节点连接起来,构成一个包含多节点的集群
一个节点就是一个运行在集群模式下的 Redis 服务器,Redis 在启动时会根据配置文件中的 cluster-enabled 配置选项是否为 yes 来决定是否开启服务器的集群模式
节点会继续使用所有在单机模式中使用的服务器组件,使用 redisServer 结构来保存服务器的状态,使用 redisClient 结构来保存客户端的状态,也有集群特有的数据结构
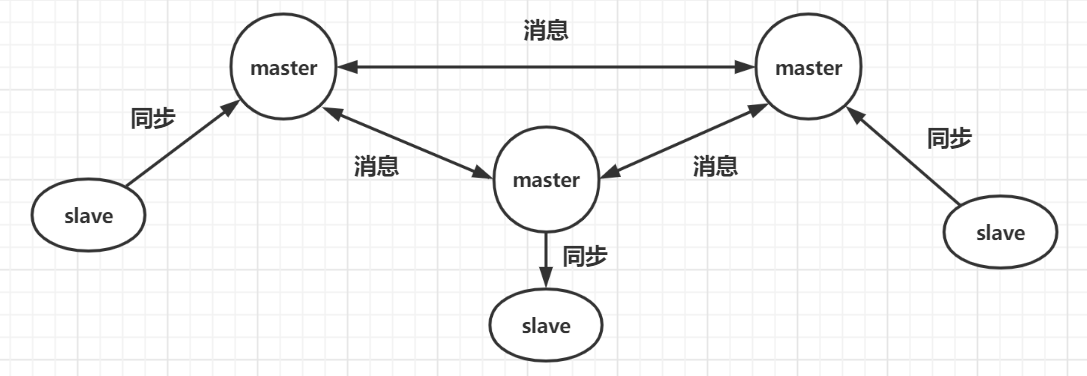
数据结构
每个节点都保存着一个集群状态 clusterState 结构,这个结构记录了在当前节点的视角下,集群目前所处的状态
typedef struct clusterState {
// 指向当前节点的指针
clusterNode *myself;
// 集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
// 集群当前的状态,是在线还是下线
int state;
// 集群中至少处理着一个槽的(主)��节点的数量,为0表示集群目前没有任何节点在处理槽
// 【选举时投票数量超过半数,从这里获取的】
int size;
// 集群节点名单(包括 myself 节点),字典的键为节点的名字,字典的值为节点对应的clusterNode结构
dict *nodes;
}
每个节点都会使用 clusterNode 结构记录当前状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的 clusterNode 结构,以此来记录其他节点的状态
struct clusterNode {
// 创建节点的时间
mstime_t ctime;
// 节点的名字,由 40 个十六进制字符组成
char name[REDIS_CLUSTER_NAMELEN];
// 节点标识,使用各种不同的标识值记录节点的��角色(比如主节点或者从节点)以及节点目前所处的状态(比如在线或者下线)
int flags;
// 节点当前的配置纪元,用于实现故障转移
uint64_t configEpoch;
// 节点的IP地址
char ip[REDIS_IP_STR_LEN];
// 节点的端口号
int port;
// 保存连接节点所需的有关信息
clusterLink *link;
}
clusterNode 结构的 link 属性是一个 clusterLink 结构,该结构保存了连接节点所需的有关信息
typedef struct clusterLink {
// 连接的创建时间
mstime_t ctime;
// TCP套接字描述符
int fd;
// 输出缓冲区,保存着等待发送给其他节点的消息(message)。
sds sndbuf;
// 输入缓冲区,保存着从其他节点接收到的消息。
sds rcvbuf;
// 与这个连接相关联的节点,如果没有的话就为NULL
struct clusterNode *node;
}
- redisClient 结构中的套接宇和缓冲区是用于连接客户端的
- clusterLink 结构中的套接宇和缓冲区则是用于连接节点的
MEET
CLUSTER MEET 命令用来将 ip 和 port 所指定的节点添加到接受命令的节点所在的集群中
CLUSTER MEET <ip> <port>
假设向节点 A 发送 CLUSTER MEET 命令,让节点 A 将另一个节点 B 添加到节点 A 当前所在的集群里,收到命令的节点 A 将与根据 ip 和 port 向节点 B 进行握手(handshake):
- 节点 A 会为节点 B 创建一个 clusterNode 结构,并将该结构添加到自己的 clusterState.nodes 字典里,然后节点 A 向节点 B 发送 MEET 消息(message)
- 节点 B 收到 MEET 消息后,节点 B 会为节点 A 创建一个 clusterNode 结构,并将该结构添加到自己的 clusterState.nodes 字典里,之后节点 B 将向节点 A 返回一条 PONG 消息
- 节点 A 收到 PONG 消息后,代表节点 A 可以知道节点 B 已经成功地接收到了自已发送的 MEET 消息,此时节点 A 将向节点 B 返回一条 PING 消息
- 节点 B 收到 PING 消息后, 代表节点 B 可以知道节点 A 已经成功地接收到了自己返回的 PONG 消息,握手完成
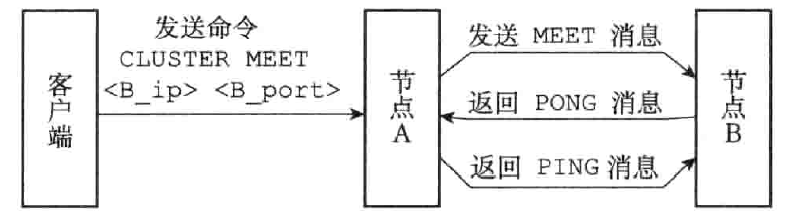
节点 A 会将节点 B 的信息通过 Gossip 协议传播给集群中的其他节点,让其他节点也与节点 B 进行握手,最终经过一段时间之后,节点 B 会被集群中的所有节点认识
槽指派
基本操作
Redis 集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为 16384 个槽(slot),数据库中的每个键都属于 16384 个槽中的一个,集群中的每个节点可以处理 0 个或最多 16384 个槽(每个主节点存储的数据并不一样)
- 当数据库中的 16384 个槽都有节点在处理时,集群处于上线状态(ok)
- 如果数据库中有任何一个槽得到处理,那么集群处于下线状态(fail)
通过向节点发送 CLUSTER ADDSLOTS 命令,可以将一个或多个槽指派(assign)给节点负责
CLUSTER ADDSLOTS <slot> [slot ... ]
127.0.0.1:7000> CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000 # 将槽0至槽5000指派给节点7000负责
OK
命令执行细节:
- 如果命令参数中有一个槽已经被指派给了某个节点,那么会向客户端返回错误,并终止命令执行
- 将 slots 数组中的索引 i 上的二进制位设置为 1,就代表指派成功
节点指派
clusterNode 结构的 slots 属性和 numslot 属性记录了节点负责处理哪些槽:
struct clusterNode {
// 处理信息,一字节等于 8 位
unsigned char slots[l6384/8];
// 记录节点负责处理的槽的数量,就是 slots 数组中值为 1 的二进制位数量
int numslots;
}
slots 是一个二进制位数组(bit array),长度为 16384/8 = 2048 个字节,包含 16384 个二进制位,Redis 以 0 为起始索引,16383 为终止索引,对 slots 数组的 16384 个二进制位进行编号,并根据索引 i 上的二进制位的值来判断节点是否负责处理槽 i:
- 在索引 i 上的二进制位的值为 1,那么表示节点负责处理槽 i
- 在索引 i 上的二进制位的值为 0,那么表示节点不负责处理槽 i

取出和设置 slots 数组中的任意一个二进制位的值的复杂度仅为 O(1),所以对于一个给定节点的 slots 数组来说,检查节点是否负责处理某个槽或者将某个槽指派给节点负责,这两个动作的复杂度都是 O(1)
传播节点的槽指派信息:一个节点除了会将自己负责处理的槽记录在 clusterNode 中,还会将自己的 slots 数组通过消息发送给集群中的其他节点,每个接收到 slots 数组的节点都会将数组保存到相应节点的 clusterNode 结构里面,因此集群中的每个节点都会知道数据库中的 16384 个槽分别被指派给了集群中的哪些节点
集群指派
集群状态 clusterState 结构中的 slots 数组记录了集群中所有 16384 个槽的指派信息,数组每一项都是一个指向 clusterNode 的指针
typedef struct clusterState {
// ...
clusterNode *slots[16384];
}
- 如果 slots[i] 指针指向 NULL,那么表示槽 i 尚未指派给任何节点
- 如果 slots[i] 指针��指向一个 clusterNode 结构,那么表示槽 i 已经指派给该节点所代表的节点
通过该节点,程序检查槽 i 是否已经被指派或者取得负责处理槽 i 的节点,只需要访问 clusterState. slots[i] 即可,时间复杂度仅为 O(1)
集群数据
集群节点保存键值对以及键值对过期时间的方式,与单机 Redis 服务器保存键值对以及键值对过期时间的方式完全相同,但是集群节点只能使用 0 号数据库,单机服务器可以任意使用
除了将键值对保存在数据库里面之外,节点还会用 clusterState 结构中的 slots_to_keys 跳跃表来保存槽和键之间的关系
typedef struct clusterState {
// ...
zskiplist *slots_to_keys;
}
slots_to_keys 跳跃表每个节点的分值(score)都是一个槽号,而每个节点的成员(member)都是一个数据库键(按槽号升序)
- 当节点往数据库中添加一个新的键值对时,节点就会将这个键以及键的槽号关联到 slots_to_keys 跳跃表
- 当节点删除数据库中的某个键值对时,节点就会在 slots_to_keys 跳跃表解除被删除键与槽号的关联
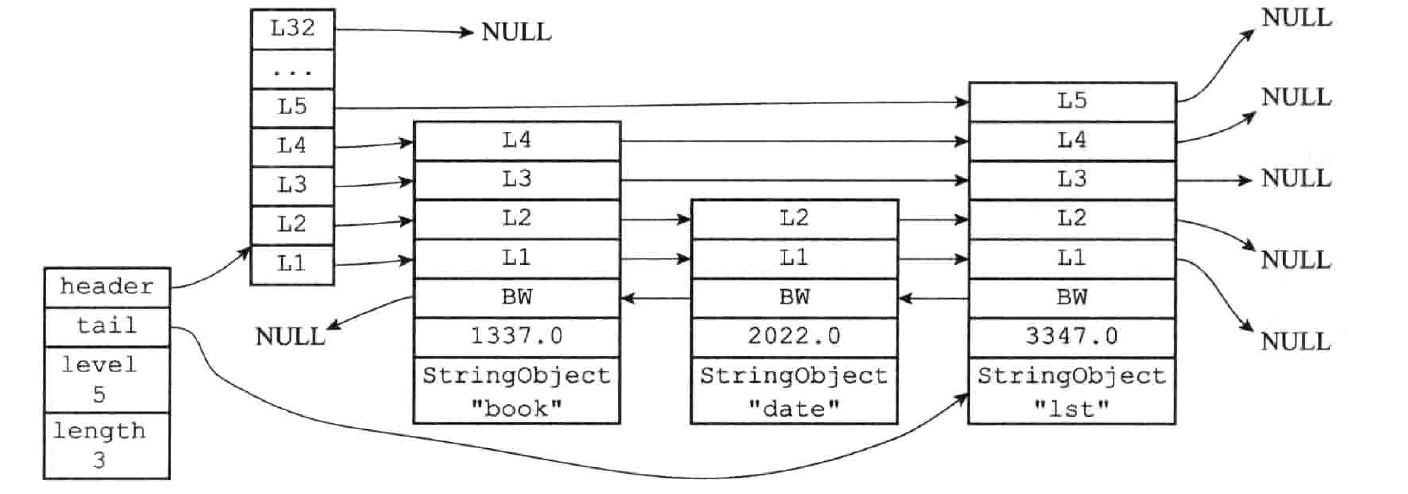
通过在 slots_to_keys 跳跃表中记录各个数据库键所属的槽,可以很方便地对属于某个或某些槽的所有数据库键进行批量操作,比如 CLUSTER GETKEYSINSLOT <slot> <count> 命令返回最多 count 个属于槽 slot 的数据库键,就是通过该跳表实现
集群命令
执行命令
集群处于上线状态,客户端就可以向集群中的节点发送命令(16384 个槽全部指派就进入上线状态)
当客户端向节点发送与数据库键有关的命令时,接收命令的节点会计算出命令该键属于哪个槽,并检查这个槽是否指派给了自己
- 如果键所在的槽正好就指派给了当前节点,那么节点直接执行这个命令
- 反之,节点会向客户端返回一个 MOVED 错误,指引客户端转向(redirect)至正确的节点,再次发送该命令
计算键归属哪个槽的寻址算法:
def slot_number(key): // CRC16(key) 语句计算键 key 的 CRC-16 校验和
return CRC16(key) & 16383; // 取模,十进制对16384的取余
使用 CLUSTER KEYSLOT <key> 命令可以查看一个给定键属于哪个槽,底层实现:
def CLUSTER_KEYSLOT(key):
// 计算槽号
slot = slot_number(key);
// 将槽号返回给客户端
reply_client(slot);
判断槽是否由当前节点负责处理:如果 clusterState.slots[i] 不等于 clusterState.myself,那么说明槽 i 并非由当前节点负责,节点会根据 clusterState.slots[i] 指向的 clusterNode 结构所记录的节点 IP 和端口号,向客户端返回 MOVED 错误
MOVED
MOVED 错误的格式为:
MOVED <slot> <ip>:<port>
参数 slot 为键所在的槽,ip 和 port 是负责处理槽 slot 的节点的 ip 地址和端口号
MOVED 12345 127.0.0.1:6380 # 表示槽 12345 正由 IP地址为 127.0.0.1, 端口号为 6380 的节点负责
当客户端接收到节点返回的 MOVED 错误时,客户端会根据 MOVED 错误中提供的 IP 地址和端口号,转至负责处理槽 slot 的节点重新发送执行的命令
-
一个集群客户端通常会与集群中的多个节点创建套接字连接,节点转向实际上就是换一个套接字来发送命令
-
如果客户端尚未与转向的节点创建套接字连接,那么客户端会先根据 IP 地址和端口号来连接节点,然后再进行转向
集群模式的 redis-cli 在接收到 MOVED 错误时,并不会打印出 MOVED 错误,而是根据错误自动进行节点转向,并打印出转向信息:
$ redis-cli -c -p 6379 #集群模式
127.0.0.1:6379> SET msg "happy"
-> Redirected to slot [6257] located at 127.0.0.1:6380
OK
127.0.0.1:6379>
使用单机(stand alone)模式的 redis-cli 会打印错误,因为单机模式客户端不清楚 MOVED 错误的作用,不会进行自动转向:
$ redis-cli -c -p 6379 #集群模式
127.0.0.1:6379> SET msg "happy"
(error) MOVED 6257 127.0.0.1:6380
127.0.0.1:6379>
重新分片
实现原理
Redis 集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点),并且相关槽的键值对也会从源节点被移动到目标节点,该操作是可以在线(online)进行,在重新分片的过程中源节点和目标节点都可以处理命令请求
Redis 的集群管理软件 redis-trib 负责执行重新分片操作,redis-trib 通过向源节点和目标节点发送命令来进行重新分片操作
- 向目标节点发送
CLUSTER SETSLOT <slot> IMPORTING <source_id>命令,准备好从源节点导入属于槽 slot 的键值对 - 向源节点发送
CLUSTER SETSLOT <slot> MIGRATING <target_id>命令,让源节点准备好将属于槽 slot 的键值对迁移 - redis-trib 向源节点发送
CLUSTER GETKEYSINSLOT <slot> <count>命令,获得最多 count 个属于槽 slot 的键值对的键名 - 对于每个 key,redis-trib 都向源节点发送一个
MIGRATE <target_ip> <target_port> <key_name> 0 <timeout>命令,将被选中的键原子地从源节点迁移至目标节点 - 重复上述步骤,直到源节点保存的所有槽 slot 的键值对都被迁移至目标节点为止
- redis-trib 向集群中的任意一个节点发送
CLUSTER SETSLOT <slot> NODE <target _id>命令,将槽 slot 指派给目标节点,这一指派信息会通过消息传播至整个集群,最终集群中的所有节点都直到槽 slot 已经指派给了目标节点
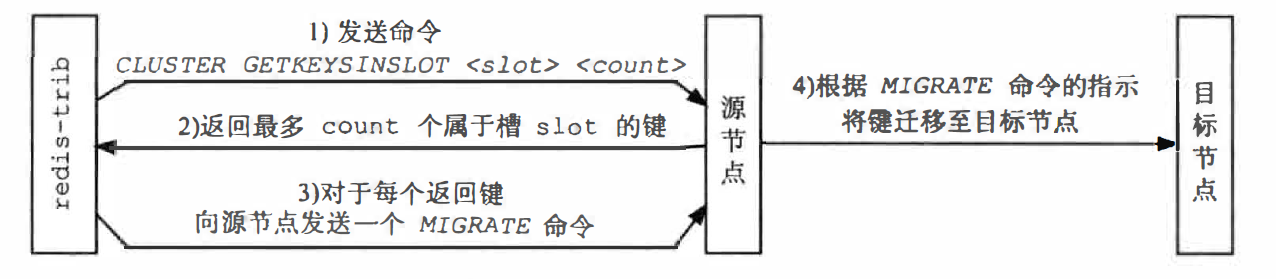
如果重新分片涉及多个槽,那么 redis-trib 将对每个给定的槽分别执行上面给出的步骤
命令原理
clusterState 结构的 importing_slots_from 数组记录了当前节点正在从其他节点导入的槽,migrating_slots_to 数组记录了当前节点正在迁移至其他节点的槽:
typedef struct clusterState {
// 如果 importing_slots_from[i] 的值不为 NULL,而是指向一个 clusterNode 结构,
// 那么表示当前节点正在从 clusterNode 所代表的节点导入槽 i
clusterNode *importing_slots_from[16384];
// 表示当前节点正在将槽 i 迁移至 clusterNode 所代表的节点
clusterNode *migrating_slots_to[16384];
}
CLUSTER SETSLOT <slot> IMPORTING <source_id> 命令:将目标节点 clusterState.importing_slots_from[slot] 的值设置为 source_id 所代表节点的 clusterNode 结构
CLUSTER SETSLOT <slot> MIGRATING <target_id> 命令:将源节点 clusterState.migrating_slots_to[slot] 的值设置为target_id 所代表节点的 clusterNode 结构
ASK 错误
重新分片期间,源节点向目标节点迁移一个槽的过程中,可能出现被迁移槽的一部分键值对保存在源节点,另一部分保存在目标节点
客户端向源节点发送命令请求,并且命令要处理的数据库键属于被迁移的槽:
-
源节点会先在数据库里面查找指定键,如果找到的话,就直接执行客户端发送的命令
-
未找到会检查 clusterState.migrating_slots_to[slot],看键 key 所属的槽 slot 是否正在进行迁移
-
槽 slot 正在迁移则源节点将向客户端返回一个 ASK 错误,指引客户端转向正在导入槽的目标节点
ASK <slot> <ip:port> -
接到 ASK 错误的客户端,会根据错误提供的 IP 地址和端口号转向目标节点,首先向目标节点发送一个 ASKING 命令,再重新发送原本想要执行的命令
和 MOVED 错误情况类似,集群模式的 redis-cli 在接到 ASK 错误时不会打印错误进行自动转向;单机模式的 redis-cli 会打印错误
对比 MOVED 错误:
-
MOVED 错误代表槽的负责权已经从一个节点转移到了另一个节点,转向是一种持久性的转向
-
ASK 错误只是两个节点在迁移槽的过程中使用的一种临时措施,ASK 的转向不会对客户端今后发送关于槽 slot 的命令请求产生任何影响,客户端仍然会将槽 slot 的命令请求发送至目前负责处理槽 slot 的节点,除非 ASK 错误再次出现
ASKING
客户端不发送 ASKING 命令,而是直接发送执行的命令,那么客户端发送的命令将被节点拒绝执行,并返回 MOVED 错误
ASKING 命令作用是打开发送该命令的客户端的 REDIS_ASKING 标识,该命令的伪代码实现:
def ASKING ():
// 打开标识
client.flags |= REDIS_ASKING
// 向客户端返回OK回复
reply("OK")
当前节点正在导入槽 slot,并且发送命令的客户端带有 REDIS_ASKING 标识,那么节点将破例执行这个关于槽 slot 的命令一次
客户端的 REDIS_ASKING 标识是一次性标识,当节点执行了一个带有 REDIS_ASKING 标识的客户端发送的命令之后,该客户端的 REDIS_ASKING 标识就会被移除
高可用
节点复制
Redis 集群中的节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,而从节点则用于复制主节点,并在被复制的主节点下线时,代替下线主节点继续处理命令请求
CLUSTER REPLICATE <node_id>
向一个节点发送命令可以让接收命令的节点成为 node_id 所指定节点的从节点,并开始对主节点进行复制
-
接受命令的节点首先会在的 clusterState.nodes 字典中找到 node_id 所对应节点的 clusterNode 结构,并将自己的节点中的 clusterState.myself.slaveof 指针指向这个结构,记录这个节点正在复制的主节点
-
节点会修改 clusterState.myself.flags 中的属性,关闭 REDIS_NODE_MASTER 标识,打开 REDIS_NODE_SLAVE 标识
-
节点会调用复制代码,对主节点进行复制(节点的复制功能和单机 Redis 服务器的使用了相同的代码)
一个节点成为从节点,并开始复制某个主节点这一信息会通过消息发送给集群中的其他节点,最终集群中的所有节点都会知道某个从节点正在复制某个主节点
主节点的 clusterNode 结构的 slaves 属性和 numslaves 属性中记录正在复制这个主节点的从节点名单:
struct clusterNode {
// 正在复制这个主节点的从节点数量
int numslaves;
// 数组项指向一个正在复制这个主节点的从节点的clusterNode结构
struct clusterNode **slaves;
}
故障检测
集群中的每个节点都会定期地向集群中的其他节点发送 PING 消息,来检测对方是否在线,如果接收 PING 的节点没有在规定的时间内返回 PONG 消息,那么发送消息节点就会将接收节点标记为疑似下线(probable fail)
集群中的节点会互相发送消息,来交换集群中各个节点的状态信息,当一个主节点 A 通过消息得知主节点 B 认为主节点 C 进入了疑似下线状态时,主节点 A 会在 clusterState.nodes 字典中找到主节点 C 所对应的节点,并将主节点 B 的下线报告(failure report)添加到 clusterNode.fail_reports 链表里面
struct clusterNode {
// 一个链表,记录了所有其他节点对该节点的下线报告
list *fail_reports;
}
// 每个下线报告由一个 clusterNodeFailReport 结构表示
struct clusterNodeFailReport {
// 报告目标节点巳经下线的节点
struct clusterNode *node;
// 最后一次从node节点收到下线报告的时间
// 程序使用这个时间戳来检查下线报告是否过期,与当前时间相差太久的下线报告会被删除
mstime_t time;
};
集群里半数以上负责处理槽的主节点都将某个主节点 X 报告为疑似下线,那么 X 将被标记为已下线(FAIL),将 X 标记为已下线的节点会向集群广播一条关于主节点 X 的 FAIL 消息,所有收到消息的节点都会将 X 标记为已下线
故障转移
当一个从节点发现所属的主节点进入了已下线状态,从节点将开始对下线主节点进行故障转移,执行步骤:
- 下属的从节点通过选举产生一个节点
- 被选中的从节点会执行
SLAVEOF no one命令,成为新的主节点 - 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自��己
- 新的主节点向集群广播一条 PONG 消息,让集群中的其他节点知道当前节点变成了主节点,并且接管了下线节点负责处理的槽
- 新的主节点开始接收有关的命令请求,故障转移完成
选举算法
集群选举新的主节点的规则:
- 集群的配置纪元是一个自增的计数器,初始值为 0
- 当集群里某个节点开始一次故障转移,集群的配置纪元就是增加一
- 每个配置纪元里,集群中每个主节点都有一次投票的机会,而第一个向主节点要求投票的从节点将获得该主节点的投票
- 具有投票权的主节点是必须具有正在处理的槽
- 集群里有 N 个具有投票权的主节点,那么当一个从节点收集到大于等于
N/2+1张支持票时,从节点就会当选 - 每个配置纪元里,具有投票权的主节点只能投一次票,所以获得一半以上票的节点只会有一个
选举流程:
- 当某个从节点发现正在复制的主节点进入已下线状态时,会向集群广播一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有收到这条消息、并且具有投票权的主节点向这个从节点投票 - 如果主节点尚未投票给其他从节点,将向要求投票的从节点返回一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示这个主节点支持从节点成为新的主节点 - 如果从节点获取到了半数以上的选票,则会当选新的主节点
- 如果一个配置纪元里没有从节点能收集到足够多的支待票,那么集群进入一个新的配置纪元,并再次进行选举,直到选出新的主节点
选举新主节点的方法和选举领头 Sentinel 的方法非常相似,两者都是基于 Raft 算法的领头选举(leader election)方法实现的
消息机制
消息结构
集群中的各个节点通过发送和接收消息(message)来进行通信,将发送消息的节点称为发送者(sender),接收消息的节点称为接收者(receiver)
节点发送的消息主要有:
-
MEET 消息:当发送者接到客户端发送的 CLUSTER MEET 命令时,会向接收者发送 MEET 消息,请求接收者加入到发送者当前所处的集群里
-
PING 消息:集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个,然后对这五个节点中最长时间没有发送过 PING 消息的节点发送 PING,以此来随机检测被选中的节点是否在线
如果节点 A 最后一次收到节点 B 发送的 PONG 消息的时间,距离当前已经超过了节点 A 的 cluster-node-timeout 设置时长的一半,那么 A 也会向 B 发送 PING 消息,防止 A 因为长时间没有随机选中 B 发送 PING,而导致对节点 B 的信息更新滞后
-
PONG 消息:当接收者收到 MEET 消息或者 PING 消息时,为了让发送者确认已经成功接收消息,会向发送者返回一条 PONG;节点也可以通过向集群广播 PONG 消息来让集群中的其他节点立即刷新��关于这个节点的认识(从升级为主)
-
FAIL 消息:当一个主节点 A 判断另一个主节点 B 已经进入 FAIL 状态时,节点 A 会向集群广播一条 B 节点的 FAIL 信息
-
PUBLISH 消息:当节点接收到一个 PUBLISH 命令时,节点会执行这个命令并向集群广播一条 PUBLISH 消息,接收到 PUBLISH 消息的节点都会执行相同的 PUBLISH 命令
消息头
节点发送的所有消息都由一个消息头包裹,消息头除了包含消息正文之外,还记录了消息发送者自身的一些信息
消息头:
typedef struct clusterMsg {
// 消息的长度(包括这个消息头的长度和消息正文的长度)
uint32_t totlen;
// 消息的类型
uint16_t type;
// 消息正文包含的节点信息数量,只在发送MEET、PING、PONG这三种Gossip协议消息时使用
uint16_t count;
// 发送者所处的配置纪元
uint64_t currentEpoch;
// 如果发送者是一个主节点,那么这里记录的是发送者的配置纪��元
// 如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的配置纪元
uint64_t configEpoch;
// 发送者的名字(ID)
char sender[REDIS CLUSTER NAMELEN];
// 发送者目前的槽指派信息
unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
// 如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的名字
// 如果发送者是一个主节点,那么这里记录的是 REDIS_NODE_NULL_NAME,一个 40 宇节长值全为 0 的字节数组
char slaveof[REDIS_CLUSTER_NAMELEN];
// 发送者的端口号
uint16_t port;
// 发送者的标识值
uint16_t flags;
//发送者所处集群的状态
unsigned char state;
// 消息的正文(或者说, 内容)
union clusterMsgData data;
}
clusterMsg 结构的 currentEpoch、sender、myslots 等属性记录了发送者的节点信息,接收者会根据这些信息在 clusterState.nodes �字典里找到发送者对应的 clusterNode 结构,并对结构进行更新,比如传播节点的槽指派信息
消息正文:
union clusterMsgData {
// MEET、PING、PONG 消息的正文
struct {
// 每条 MEET、PING、PONG 消息都包含两个 clusterMsgDataGossip 结构
clusterMsgDataGossip gossip[1];
} ping;
// FAIL 消息的正文
struct {
clusterMsgDataFail about;
} fail;
// PUBLISH 消息的正文
struct {
clusterMsgDataPublish msg;
} publish;
// 其他消息正文...
}
Gossip
Redis 集群中的各个节点通过 Gossip 协议来交换各自关于不同节点的状态信息,其中 Gossip 协议由 MEET、PING、PONG 消息实现,三种消息使用相同的消息正文,所以节点通过消息头的 type 属性来判断消息的具体类型
发送者发送这三种消息时,会从已知节点列表中随机选出两个节点(主从都可以),将两个被选中节点信息保存到两个 Gossip 结构
typedef struct clusterMsgDataGossip {
// 节点的名字
char nodename[REDIS CLUSTER NAMELEN];
// 最后一次向该节点发送PING消息的时间戳
uint32_t ping_sent;
// 最后一次从该节点接收到PONG消息的时间戳
uint32_t pong_received;
// 节点的IP地址
char ip[16];
// 节点的端口号
uint16_t port;
// 节点的标识值
uint16_t flags;
}
当接收者收到�消息时,会访问消息正文中的两个数据结构,来进行相关操作
- 如果被选中节点不存在于接收者的已知节点列表,接收者将根据结构中记录的 IP 地址和端口号,与节点进行握手
- 如果存在,根据 Gossip 结构记录的信息对节点所对应的 clusterNode 结构进行更新
FAIL
在集群的节点数量比较大的情况下,使用 Gossip 协议来传播节点的已下线信息会带来一定延迟,因为 Gossip 协议消息通常需要一段时间才能传播至整个集群,所以通过发送 FAIL消息可以让集群里的所有节点立即知道某个主节点已下线,从而尽快进行其他操作
FAIL 消息的正文由 clusterMsgDataFail 结构表示,该结构只有一个属性,记录了已下线节点的名字
typedef struct clusterMsgDataFail {
char nodename[REDIS_CLUSTER_NAMELEN)];
};
因为传播下线信息不需要其他属性,所以节省了传播的资源
PUBLISH
当客户端向集群中的某个节点发送命令,接收到 PUBLISH 命令的节点不仅会向 channel 频道发送消息 message,还会向集群广播一条 PUBLISH 消息,所有接收到这条 PUBLISH 消息的节点都会向 channel 频道发送 message 消息,最终集群中所有节点都发了
PUBLISH <channel> <message>
PUBLISH 消息的正文由 clusterMsgDataPublish 结构表示:
typedef struct clusterMsgDataPublish {
// channel参数的长度
uint32_t channel_len;
// message参数的长度
uint32_t message_len;
// �定义为8字节只是为了对齐其他消息结构,实际的长度由保存的内容决定
// bulk_data 的 0 至 channel_len-1 字节保存的是channel参数
// bulk_data的 channel_len 字节至 channel_len + message_len-1 字节保存的则是message参数
unsigned char bulk_data[8];
}
让集群的所有节点执行相同的 PUBLISH 命令,最简单的方法就是向所有节点广播相同的 PUBLISH 命令,这也是 Redis 复制 PUBLISH 命令时所使用的,但是这种做法并不符合 Redis 集群的各个节点通过发送和接收消息来进行通信的规则
脑裂问题
脑裂指在主从集群中,同时有两个相同的主节点能接收写请求,导致客户端不知道应该往哪个主节点写入数据,最后 不同客户端往不同的主节点上写入数据
- 原主节点并没有真的发生故障,由于某些原因无法处理请求(CPU 利用率很高、自身阻塞),无法按时响应心跳请求,被哨兵/集群主节点错误的判断为下线
- 在被判断下线之后,原主库又重新开始处理请求了,哨兵/集群主节点还没有完成主从切换,客户端仍然可以和原主库通信,客户端发送的写操作就会在原主库上写入数据,造成脑裂问题
数据丢失问题:从库一旦升级为新主库,哨兵就会让原主库执行 slave of 命令,和新主库重新进行全量同步,原主库需要清空本地的数据,加载新主库发送的 RDB 文件,所以原主库在主从切换期间保存的新写数据就丢失了
预防脑裂:在主从集群部署时,合理地配置参数 min-slaves-to-write 和 min-slaves-max-lag
- 假设从库有 K 个,可以将 min-slaves-to-write 设置为 K/2+1(如果 K 等于 1,就设为 1)
- 将 min-slaves-max-lag 设置为十几秒(例如 10~20s)
- 在假故障期间无法响应哨兵发出的心跳测试,无法和从库进行 ACK 确认,并且没有足够的从库,拒绝客户端的写入
结构搭建
整体框架:
- 配置服务器(3 主 3 从)
- 建立通信(Meet)
- 分槽(Slot)
- 搭建主从(master-slave)
创建集群 conf 配置文件:
-
redis-6501.conf
port 6501dir "/redis/data"dbfilename "dump-6501.rdb"cluster-enabled yescluster-config-file "cluster-6501.conf"cluster-node-timeout 5000#其他配置文件参照上面的修改端口即可,内容完全一样 -
服务端启动:
redis-server config_file_name -
客户端启动:
redis-cli -p 6504 -c
cluster 配置:
-
是否启用 cluster,加入 cluster 节点
cluster-enabled yes|no -
cluster 配置文件名,该文件属�于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file filename -
节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-node-timeout milliseconds -
master 连接的 slave 最小数量
cluster-migration-barrier min_slave_number
客户端启动命令:
cluster 节点操作命令(客户端命令):
-
查看集群节点信息
cluster nodes -
更改 slave 指向新的 master
cluster replicate master-id -
发现一个新节点,新增 master
cluster meet ip:port -
忽略一个没有 solt 的节点
cluster forget server_id -
手动故障转移
cluster failover
集群操作命令(Linux):
-
创建集群
redis-cli –-cluster create masterhost1:masterport1 masterhost2:masterport2 masterhost3:masterport3 [masterhostn:masterportn …] slavehost1:slaveport1 slavehost2:slaveport2 slavehost3:slaveport3 -–cluster-replicas n注意:master 与 slave 的数量要匹配,一个 master 对应 n 个 slave,由最后的参数 n 决定。master 与 slave 的匹配顺序为第一个 master 与前 n 个 slave 分为一组,形成主从结构
-
添加 master 到当前集群中,连接时可以指定任意现有节点地址与端口
redis-cli --cluster add-node new-master-host:new-master-port now-host:now-port -
添加 slave
redis-cli --cluster add-node new-slave-host:new-slave-port master-host:master-port --cluster-slave --cluster-master-id masterid -
删除节点,如果删除的节点是 master,必须保障其中没有槽 slot
redis-cli --cluster del-node del-slave-host:del-slave-port del-slave-id -
重新分槽,分槽是从具有槽的 master 中划分一部分给其他 master,过程中不创建新的槽
redis-cli --cluster reshard new-master-host:new-master:port --cluster-from src- master-id1, src-master-id2, src-master-idn --cluster-to target-master-id -- cluster-slots slots注意:将需要参与分槽的所有 masterid 不分先后顺序添加到参数中,使用
,分隔,指定目标得到的槽的数量,所有的槽将平均从每个来源的 master 处获取 -
重新分配槽,从具有槽的 master 中分配指定数量的槽到另一个 master 中,常用于清空指定 master 中的槽
redis-cli --cluster reshard src-master-host:src-master-port --cluster-from src- master-id --cluster-to target-master-id --cluster-slots slots --cluster-yes
其他操作
发布订阅
基本指令
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息
Redis 客户端可以订阅任意数量的频道,每当有客户端向被订阅的频道发送消息(message)时,频道的所有订阅者都会收到消息
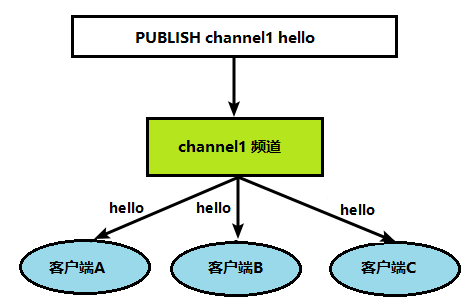
操作过程:
-
打开一个客户端订阅 channel1:
SUBSCRIBE channel1 -
打开另一个客户端,给 channel1 发布消息 hello:
PUBLISH channel1 hello -
第一个客户端可以看到发送的消息
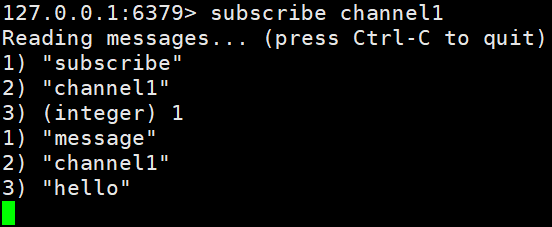
客户端还可以通过 PSUBSCRIBE 命令订阅一个或多个模式,每当有其他客户端向某个频道发送消息时,消息不仅会被发送给这个频道的所有订阅者,还会被发送给所有与这个频道相匹配的模式的订阅者,比如 PSUBSCRIBE channel* 订阅模式,与 channel1 匹配
注意:发布的消息没有持久化,所以订阅的客户端只能收到订阅后发布的消息
频道操作
Redis 将所有频道的订阅关系都保存在服务器状态的 pubsub_channels 字典里,键是某个被订阅的频道,值是一个记录所有订阅这个频道的客�户端链表
struct redisServer {
// 保存所有频道的订阅关系,
dict *pubsub_channels;
}
客户端执行 SUBSCRIBE 命令订阅某个或某些频道,服务器会将客户端与频道进行关联:
- 频道已经存在,直接将客户端添加到链表末尾
- 频道还未有任何订阅者,在字典中为频道创建一个键值对,再将客户端添加到链表
UNSUBSCRIBE 命令用来退订某个频道,服务器将从 pubsub_channels 中解除客户端与被退订频道之间的关联
模式操作
Redis 服务器将所有模式的订阅关系都保存在服务器状态的 pubsub_patterns 属性里
struct redisServer {
// 保存所有模式订阅关系,链表中每个节点是一个 pubsubPattern
list *pubsub_patterns;
}
typedef struct pubsubPattern {
// 订阅的客户端
redisClient *client;
// 被订阅的模式,比如 channel*
robj *pattern;
}
客户端执行 PSUBSCRIBE 命令订阅某个模式,服务器会新建一个 pubsubPattern 结构并赋值,放入 pubsub_patterns 链表结尾
模式的退订命令 PUNSUBSCRIBE 是订阅命令的反操作,服务器在 pubsub_patterns 链表中查找并删除对应的结构
发送消息
Redis 客户端执行 PUBLISH <channel> <message> 命令将消息 message发送给频道 channel,服务器会执行:
- 在 pubsub_channels 字典里找到频道 channel 的订阅者名单,将消息 message 发送给所有订阅者
- 遍历整个 pubsub_patterns 链表,查找与 channel 频道相匹配的模式,并将消息发送给所有订阅了这些模式的客户端
// 如果频道和模式相匹配
if match(channel, pubsubPattern.pattern) {
// 将消息发送给订阅该模式的客户端
send_message(pubsubPattern.client, message);
}
查看信息
PUBSUB 命令用来查看频道或者模式的相关信息
PUBSUB CHANNELS [pattern] 返回服务器当前被订阅的频道,其中 pattern 参数是可选的
- 如果不给定 pattern 参数,那么命令返回服务器当前被订阅的所有频道
- 如果给定 pattern 参数,那么命令返回服务器当前被订阅的频道中与 pattern 模式相匹配的频道
PUBSUB NUMSUB [channel-1 channel-2 ... channel-n] 命令接受任意多个频道作为输入参数,并返回这些频道的订阅者数量
PUBSUB NUMPAT 命令用于返回服务器当前被订阅模式的数量
ACL 指令
Redis ACL 是 Access Control List(访问控制列表)的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接
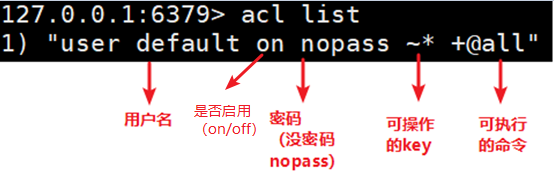
-
acl cat:查看添加权限指令类别
-
acl whoami:查看当前用户
-
acl setuser username on >password ~cached:* +get:设置有用户名、密码、ACL 权限(只能 get)
监视器
MONITOR 命令,可以将客户端变为一个监视器,实时地接收并打印出服务器当前处理的命令请求的相关信息
// 实现原理
def MONITOR():
// 打开客户端的监视器标志
client.flags |= REDIS_MONITOR
// 将客户端添加到服务器状态的 redisServer.monitors链表的末尾
server.monitors.append(client)
// 向客户端返回 ok
send_reply("OK")
服务器每次处理命令请求都会调用 replicationFeedMonitors 函数,函数将被处理的命令请求的相关信息发送给各个监视器
redis> MONITOR
OK
1378822099.421623 [0 127.0.0.1:56604] "PING"
1378822105.089572 [0 127.0.0.1:56604] "SET" "msg" "hello world"
1378822109.036925 [0 127.0.0.1:56604] "SET" "number" "123"
1378822140.649496 (0 127.0.0.1:56604] "SADD" "fruits" "Apple" "Banana" "Cherry"
1378822154.117160 [0 127.0.0.1:56604] "EXPIRE" "msg" "10086"
1378822257.329412 [0 127.0.0.1:56604] "KEYS" "*"
1378822258.690131 [0 127.0.0.1:56604] "DBSIZE"
批处理
Redis 的管道 Pipeline 机制可以一次处理多条指令
- Pipeline 中的多条命令非原子性,因为在向管道内添加命令时,其他客户端的发送的命令仍然在执行
- 原生批命令(MSET 等)是服务端实现,而 Pipeline 需要服务端与客户端共同完成
使用 Pipeline 封装的命令数量不能太多,数据量过大会增加客户端的等待时间,造成网络阻塞,Jedis 中的 Pipeline 使用方式:
// 创建管道
Pipeline pipeline = jedis.pipelined();
for (int i = 1; i <= 100000; i++) {
// 放入命令到管道
pipeline.set("key_" + i, "value_" + i);
if (i % 1000 == 0) {
// 每放入1000条命令,批量执行
pipeline.sync();
}
}
集群下模式下,批处理命令的多个 key 必须落在一个插槽中,否则就会导致执行失败,N 条批处理命令的优化方式:
- 串行命令:for 循环遍历,依次执行每个命令
- 串行 slot:在客户端计算每个 key 的 slot,将 slot 一致的分为一组,每组都利用 Pipeline 批处理,串行执行各组命令
- 并行 slot:在客户端计算每个 key 的 slot,将 slot 一致的分为一组,每组都利用 Pipeline 批处理,并行执行各组命令
- hash_tag:将所有 key 设置相同的 hash_tag,则所有 key 的 slot 一定相同
| 耗时 | 优点 | 缺点 | |
|---|---|---|---|
| 串行命令 | N 次网络耗时 + N 次命令耗时 | 实现简单 | 耗时久 |
| 串行 slot | m 次网络耗时 + N 次命令耗时,m = key 的 slot 个数 | 耗时较短 | 实现稍复杂 |
| 并行 slot | 1 次网络耗时 + N 次命令耗时 | 耗时非常短 | 实现复杂 |
| hash_tag | 1 次网络耗时 + N 次命令耗时 | 耗时非常短、实现简单 | 容易出现数据倾斜 |
解决方案
缓存方案
缓存模式
旁路缓存
缓存本质:弥补 CPU 的高算力和 IO 的慢读写之间巨大的鸿沟
旁路缓存模式 Cache Aside Pattern 是平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准
- 写操作:先更新 DB,然后直接删除 cache
- 读操作:从 cache 中读取数据,读取到就直接返回;读取不到就从 DB 中读取数据返回,并放到 cache
时序导致的不一致问题:
-
在写数据的过程中,不能先删除 cache 再更新 DB,因为会造成缓存的不一致。比如请求 1 先写数据 A,请求 2 随后读数据 A,当请求 1 删除 cache 后,请求 2 直接读取了 DB,此时请求 1 还没写入 DB(延迟双删)
-
在写数据的过程中,先更新 DB 再删除 cache 也会出现问题,但是概率很小,因为缓存的写入速度非常快
旁路缓存的缺点:
- 首次请求数据一定不在 cache 的问题,一般采用缓存预热的方法,将热点数据可以提前放入 cache 中
- 写操作比较频繁的话导致 cache 中的数据会被频繁被删除,影响缓存命中率
删除缓存而不是更新缓存的原因:每次更新数据库都更新缓存,造成无效写操作较多(懒惰加载,需要的时候再放入缓存)
读写穿透
读写穿透模式 Read/Write Through Pattern:服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中,cache 负责将此数据同步写入 DB,从而减轻了应用程序的职责
-
写操作:先查 cache,cache 中不存在,直接更新 DB;cache 中存在则先更新 cache,然后 cache 服务更新 DB(同步更新 cache 和 DB)
-
读操作:从 cache 中读取数据,读取到就直接返回 ;读取不到先从 DB 加载,写入到 cache 后返回响应
Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,对客户端是透明的
Read-Through Pattern 也存在首次不命中的问题,采用缓存预热解决
异步缓存
异步缓存写入 Write Behind Pattern 由 cache 服务来负责 cache 和 DB 的读写,对比读写穿透不同的是 Write Behind Caching 是只更新缓存,不直接更新 DB,改为异步批量的方式来更新 DB,可以减小写的成本
缺点:这种模式对数据一致性没有高要求,可能出现 cache 还没异步更新 DB,服务就挂掉了
应用:
-
DB 的写性能非常高,适合一些数据经常变化又对数据一致性要求不高的场景,比如浏览量、点赞量
-
MySQL 的 InnoDB Buffer Pool 机制用到了这种策略
缓存一致
使用缓存代表不需要强一致性,只需要最终一致性
缓存不一致的方法:
-
数据库和缓存数据强一致场景:
-
同步双写:更新 DB 时同样更新 cache,保证在一个事务中,通过加锁来保证更新 cache 时不存在线程安全问题
-
延迟双删:先淘汰缓存再写数据库,休眠 1 秒再次淘汰缓存,可以将 1 秒内造成的缓存脏数据再次删除
-
异步通知:
- 基于 MQ 的异步通知:对数据的修改后,代码需要发送一条消息到 MQ 中,缓存服务监听 MQ 消息
- Canal 订阅 MySQL binlog 的变更上报给 Kafka,系统监听 Kafka 消息触发缓存失效,或者直接将变更发送到处理服务,没有任何代码侵入
低耦合,可以同时通知多个缓存服务,但是时效性一般,可能存在中间不一致状态
-
-
低一致性场景:
- 更新 DB 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样就可以保证即使数据不一致影响也比较小
- 使用 Redis 自带的内存淘汰机制
缓存问题
缓存预热
场景:宕机,服务器启动后迅速宕机
问题排查:
-
请求数量较高,大�量的请求过来之后都需要去从缓存中获取数据,但是缓存中又没有,此时从数据库中查找数据然后将数据再存入缓存,造成了短期内对 redis 的高强度操作从而导致问题
-
主从之间数据吞吐量较大,数据同步操作频度较高
解决方案:
-
前置准备工作:
-
日常例行统计数据访问记录,统计访问频度较高的热点数据
-
利用 LRU 数据删除策略,构建数据留存队列例如:storm 与 kafka 配合
-
-
准备工作:
-
将统计结果中的数据分类,根据级别,redis 优先加载级别较高的热点数据
-
利用分布式多服务器同时进行数据读取,提速数据加载过程
-
热点数据主从同时预热
-
-
实施:
-
使用脚本程序固定触发数据预热过程
-
如果条件允许,使用了 CDN(内容分发网络),效果会更好
-
总的来说:缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据
缓存雪崩
场景:数据库服务器崩溃,一连串的问题会随之而来
问题排查:在一个较短的时间内,缓存中较多的 key 集中过期,此周期内请求访问过期的数据 Redis 未命中,Redis 向数据库获取数据,数据库同时收到大量的请求无法及时处理��。
解决方案:
- 加锁,慎用
- 设置热点数据永远不过期,如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 构建多级缓存架构,Nginx 缓存 + Redis 缓存 + ehcache 缓存
- 灾难预警机制,监控 Redis 服务器性能指标,CPU 使用率、内存容量、平均响应时间、线程数
- 限流、降级:短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问
总的来说:缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如能够有效避免过期时间集中,可以有效解决雪崩现象的出现(约 40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整。
缓存击穿
缓存击穿也叫热点 Key 问题
-
Redis 中某个 key 过期,该 key 访问量巨大
-
多个数据请求从服务器直接压到 Redis 后,均未命中
-
Redis 在短时间内发起了大量对数据库中同一数据的访问
解决方案:
-
预先设定:以电商为例,每个商家根据店铺等级,指定若干款主打商品,在购物节期间,加大此类信息 key 的过期时长 注意:购物节不仅仅指当天,以及后续若干天,访问峰值呈现逐渐降低的趋势
-
现场调整:监控访问量,对自然流量激增的数据延长过期时间或设置为永久性 key
-
后台刷新数据:启动定时任务,高峰期来临之前,刷新数据有效期,确保不丢失
-
二级缓存:设置不同的失效时间,保障不会被同时淘汰就行
-
加锁:分布式锁,防止被击穿,但是要注意也是性能瓶颈,慎重
总的来说:缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中 Redis 后,发起了大量对同一数据的数据库访问,导致对数据库服务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个 key 的过期监控难度较高,配合雪崩处理策略即可
缓存穿透
场景:系统平稳运行过程中,应用服务器流量随时间增量较大,Redis 服务器命中率随时间逐步降低,Redis 内存平稳,内存无压力,Redis 服务器 CPU 占用激增,数据库服务器压力激增,数据库崩溃
问题排查:
-
Redis 中大面积出现未命中
-
出现非正常 URL 访问
问题分析:
- 访问了不存在的数据,跳过了 Redis 缓存,数据库页查询不到对应数据
- Redis 获取到 null 数据未进行持久化,直接返回
- 出现黑客攻击服务器
解决方案:
-
缓存 null:对查询结果为 null 的数据进行缓存,设定短时限,例如 30-60 秒,最高 5 分钟
-
白名单策略:提前预热各种分类数据 id 对应的 bitmaps,id 作为 bitmaps 的 offset,相当于设置了数据白名单。当加载正常数据时放行,加载异常数据时直接拦截(效率偏低),也可以使用布隆过滤器(有关布隆过滤器的命中问题对当前状况可以忽略)
-
实时监控:实时监控 Redis 命中率(业务正常范围时,通常会有一个波动值)与 null 数据的占比
- 非活动时段波动:通常检测 3-5 倍,超过 5 倍纳入重点排查对象
- 活动时段波动:通常检测10-50 倍,超过 50 倍纳入重点排查对象
根据倍数不同,启动不同的排查流程。然后使用黑名单进行防控
-
key 加密:临时启动防灾业务 key,对 key 进行业务层传输加密服务,设定校验程序,过来的 key 校验;例如每天随机分配 60 个加密串,挑选 2 到 3 个,混淆到页面数据 id 中,发现访问 key 不满足规则,驳回数据访问
总的来说:缓存击穿是指访问了不存在的数据,跳过了合法数据的 Redis 数据缓存阶段,每次访问数据库,导致对数据库服务器造成压力。通常此类数据的出现量是一个较低的值,当出现此类情况以毒攻毒,并及时报警。无论是黑名单还是白名单,都是对整体系统的压力,警报解除后尽快移除
参考视频:https://www.bilibili.com/video/BV15y4y1r7X3
Key 设计
大 Key:通常以 Key 的大小和 Key 中成员的数量来综合判定,引发的问题:
- 客户端执行命令的时长变慢
- Redis 内存达到 maxmemory 定义的上限引发操作阻塞或重要的 Key 被逐出,甚至引发内存溢出(OOM)
- 集群架构下,某个数据分片的内存使用率远超其他数据分片,使数据分片的内存资源不均衡
- 对大 Key 执行读请求,会使 Redis 实例的带宽使用率被占满,导致自身服务变慢,同时易波及相关的服务
- 对大 Key 执行删除操作,会造成主库较长时间的阻塞,进而可能引发同步中断或主从切换
热 Key:通常以其接收到的 Key 被请求频率来判定,引发的问题:
- 占用大量的 CPU 资源,影响其他请求并导致整体性能降低
- 分布式集群架构下,产生访问倾斜,即某个数据分片被大量访问,而其他数据分片处于空闲状态,可能引起该数据分片的连接数被耗尽,新的连接建立请求被拒绝等问题
- 在抢购或秒杀场景下,可能因商品对应库存 Key 的请求量过大,超出 Redis 处理能力造成超卖
- 热 Key 的请求压力数量超出 Redis 的承受能力易造成缓存击穿,即大量请求将被直接指向后端的存储层,导致存储访问量激增甚至宕机,从而影响其他业务
热 Key 分类两种,治理方式如下:
- 一种是单一数据,比如秒杀场景,假设总量 10000 可以拆为多个 Key 进行访问,每次对请求进行路由到不同的 Key 访问,保证最终一致性,但是会出现访问不同 Key 产生的剩余量是不同的,这时可以通过前端进行 Mock 假数据
- 一种是多数据集合,比如进行 ID 过滤,这时可以添加本地 LRU 缓存,减少对热 Key 的访问
参考文档:https://help.aliyun.com/document_detail/353223.html
慢查询
确认服务和 Redis 之间的链路是否正常,排除网络原因后进行 Redis 的排查:
- 使用复杂度过高的命令
- 操作大 key,分配内存和释放内存会比较耗时
- key 集中过期,导致定时任务需要更长的时间去清理
- 实例内存达到上限,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据
参考文章:https://www.cnblogs.com/traditional/p/15633919.html(非常好)