HDFS写流程 ⭐️⭐️⭐️
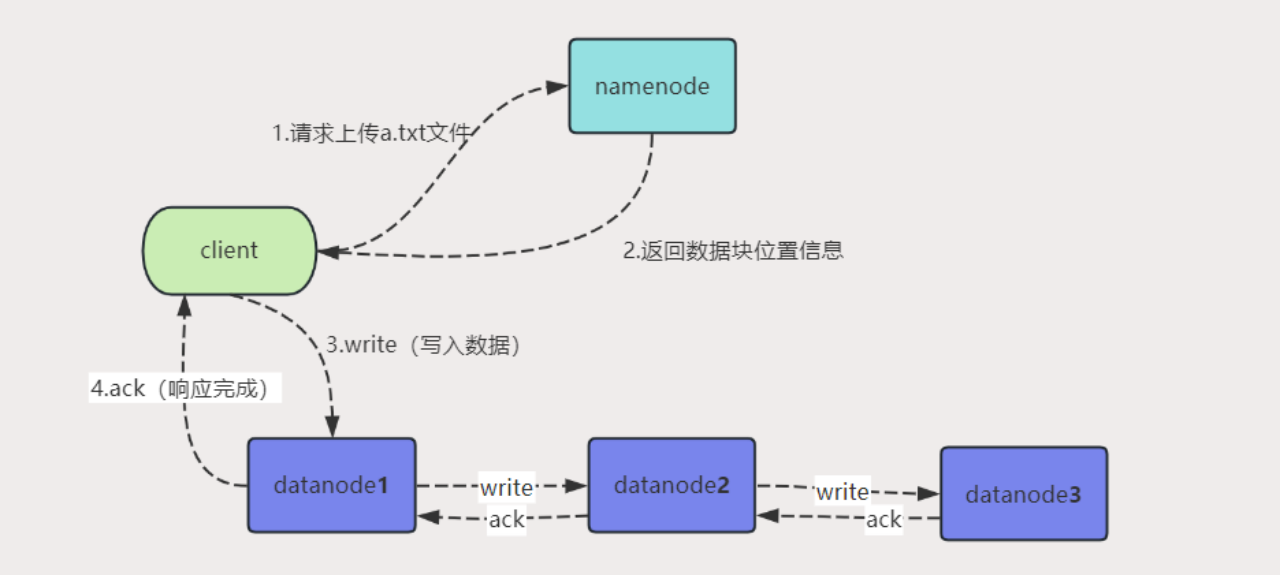
普通版 ⭐️⭐️⭐️
HDFS写数据的精简流程如下:
- 客户端向Namenode发送写入请求。
- Namenode检查允许客户端写入,确定要写入数据块的位置信息并返回给客户端。
- 客户端将要写入的数据块划分为若干数据包,并根据数据块位置信息,与对应的DataNode数据节点建立连接,将数据包传输给DataNode数据节点。
- DataNode数据节点接收数据包,并将其存储在本地磁盘上。
- DataNode数据节点之间进行数据复制,将数据块的副本传输给其他DataNode数据节点。
- 当DataNode数据块的所有副本都成功写入DataNode数据节点后,客户端收到写入成功的响应。
- 名称节点更新文件的元数据,包括文件大小、数据块位置等信息。
精细版
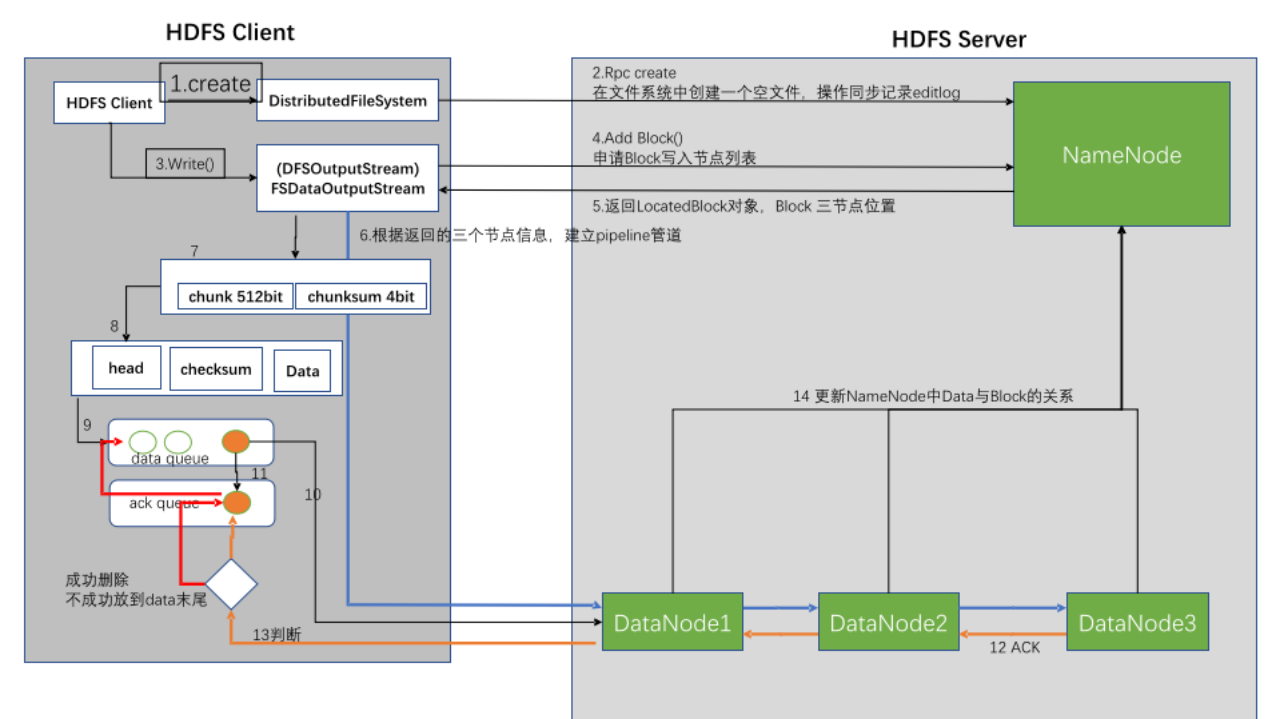
- 客户端通过调用DistributedFileSystem对象的create()方法来新建文件。DistributedFileSystem向Namenode发送RPC调用,在文件系统的命名空间中新建一个文件,此时文件中还没有对应的数据块。
- Namenode执行各种检查,确保文件不存在并且客户端有新建该文件的权限。如果��检查通过,namenode为创建新文件记录一条记录;否则,文件创建失败并向客户端抛出IOException异常。DistributedFileSystem返回一个FSDataOutputStream对象给客户端以便开始写入数据。
- 客户端写入数据时,DFSOutputStream将数据分成一个个的数据包,并写入数据队列。DataStreamer负责处理数据队列,选择一组适合存储数据副本的DataNode,并要求Namenode分配新的数据块。
- DataStreamer将数据包流式传输到管线中的第一个DataNode,该DataNode存储数据包并将其发送给管线中的下一个DataNode。数据包依次经过管线中的所有DataNode。
- DFSOutputStream维护一个确认队列,等待管线中所有DataNode的确认信息。只有当收到管线中所有DataNode的确认信息后,数据包才从确认队列删除。
- 如果在数据写入期间有任何DataNode发生故障,管线会关闭并将队列中的所有数据包添加回数据队列的最前端,以确保故障节点下游的DataNode不会漏掉任何数据包。同时,为存储在另一个正常DataNode上的当前数据块指定一个新的标识,并将该标识传送给Namenode,以便故障DataNode在恢复后可以删除存储的部分数据块。然后建立基于两个正常DataNode的新管线,将余下的数据块写入管线中的正常DataNode。
- 客户端完成数据的写入后,对数据流调用close()方法。这将把剩余的所有数据包写入DataNode管线,并在联系Namenode之前等待确认。Namenode在返回成功前只需要等待数据块进行最少量的复制,因为它已经知道文件由哪些块组成。
需要注意的是,写入期间可能会有多个DataNode发生故障,但只要写入了最小复本数,写操作就会成功,并且这个块可以在集群中异步复制,直到达到目标复本数。