高可用HA ⭐️⭐️
在 Hadoop 2.0.0 之前,NameNode 是 HDFS 集群中的单点故障 (SPOF)。每个集群都有一个 NameNode,如果该机器或进程不可用,则整个集群将不可用,直到 NameNode 重新启动或在单独的机器上启动为止。
1. Namenode的启动流程
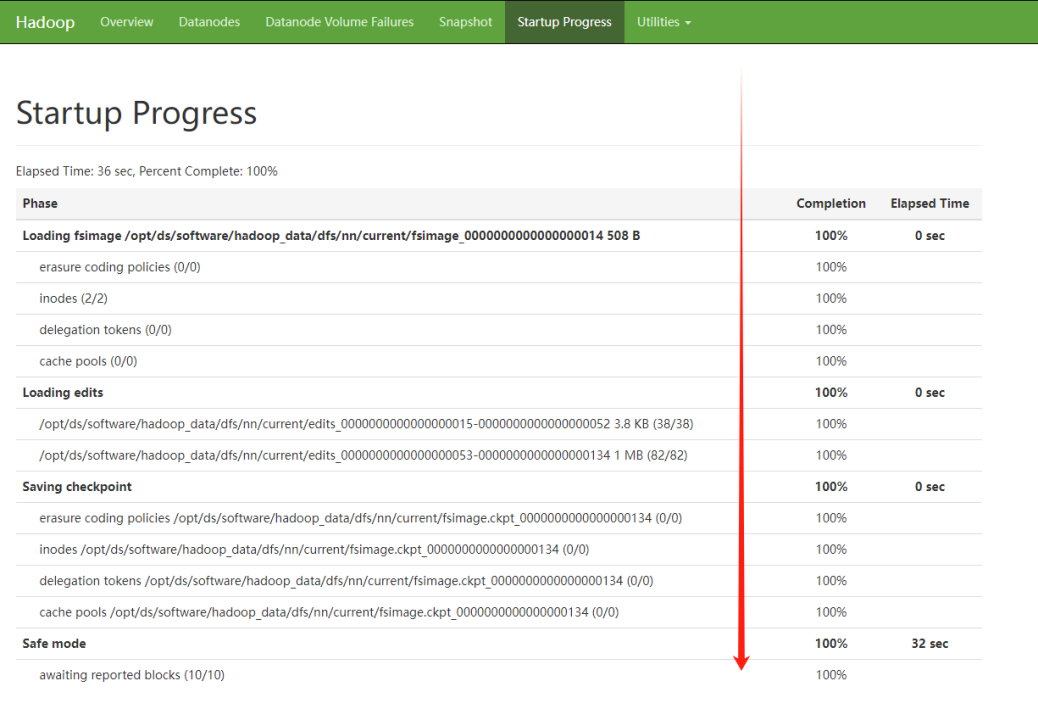
- 将命名空间的映像导入内存中;
- 重演编辑日志;
- 接收到足够多的来自 datanode的数据块报告并退出安全模式。
2. SecondaryNameNode的作用
从namenode的启动过程中可以知道只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是实际的生产环境下namenode是不能够轻易重启的,这就会导致下面的问题出现:
- edit logs变的很庞大。
- fsimage在运行过程中不能更新,导致下次namenode启动时需要加载所有的edit logs,整个过程会变的异常缓慢。
- Secondary NameNode的作用就是在集群运行的状态下来定时的合并fsimage和edit logs,减小edit logs文件的大小和得到一个最新的fsimage文件。充当一个检查点的功能,本质上也可以称之为检查点服务节点。
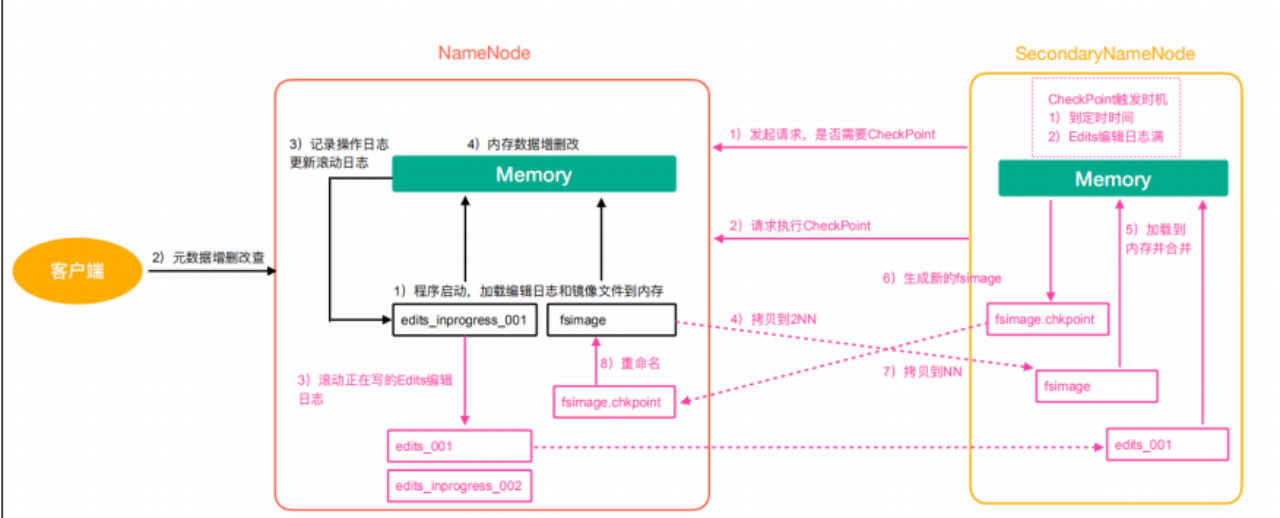
具体的工作过程如下:
- Secondary NameNode询问NameNode�是否需要CheckPoint。直接带回NameNode是否执行检查点操作结果。
- Secondary NameNode请求执行CheckPoint。
- NameNode滚动正在写的Edits日志。
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件chkpoint。
- 拷贝chkpoint到NameNode。
- NameNode将fsimage.chkpoint重新命名成fsimage。
上述的CheckPoint的动作可以通过配置来控制其触发的周期。
修改集群的hdfs-default.xml文件
<configuration>
<!-- 定时一小时进行一次检查点(单位:秒) -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>每隔 3600 秒(即 1 小时)触发一次检查点操作</description>
</property>
<!-- 当操作次数达到 100 万时触发检查点 -->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>当累计操作次数达到 1,000,000 时,SecondaryNameNode 执行一次检查点</description>
</property>
<!-- 每隔 1 分钟检查一次操作次数 -->
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>每隔 60 秒(即 1 分钟)检查操作次数</description>
</property>
</configuration>
3. Standby namenode
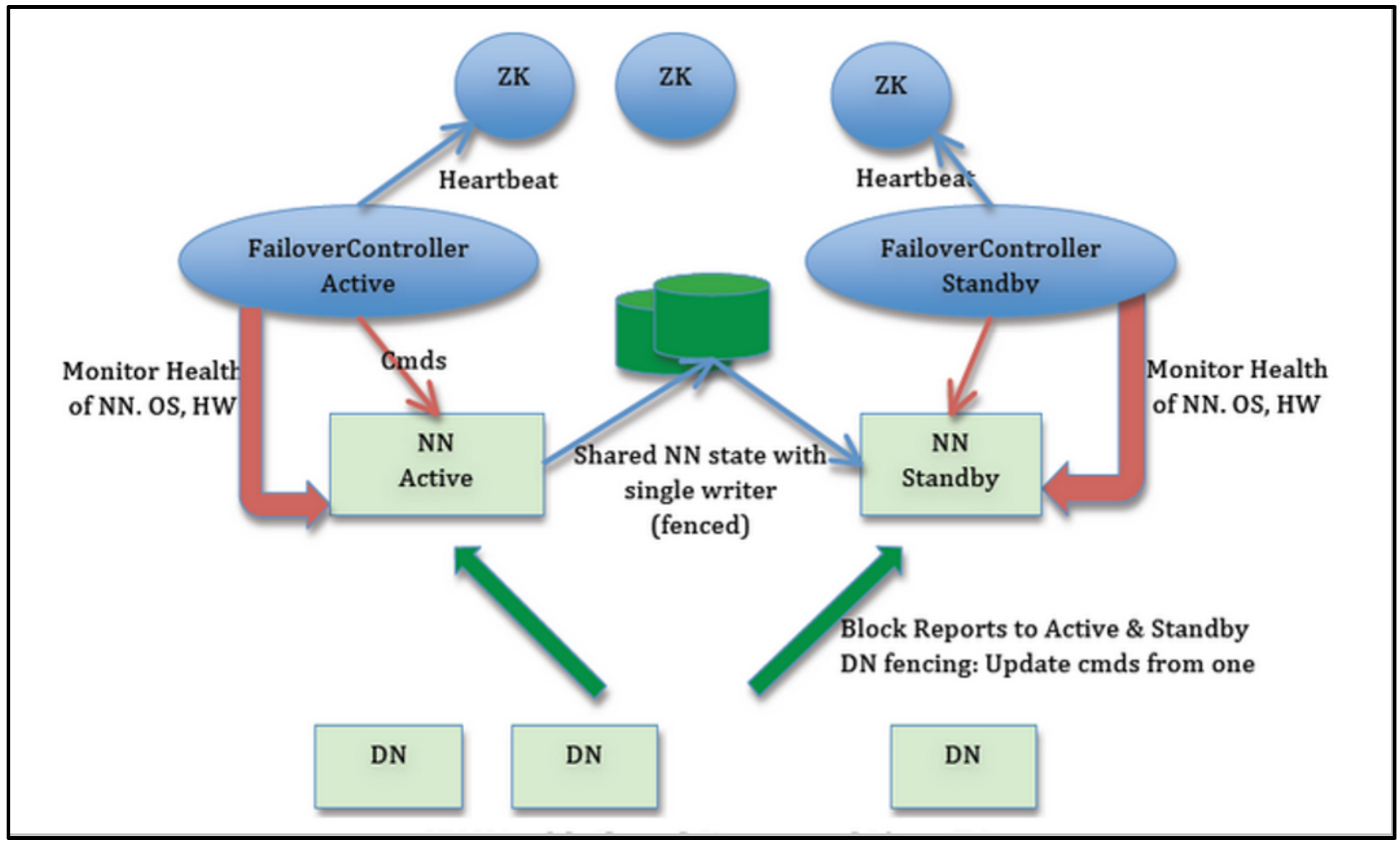
在集群的HA模式下,有两个namenode,一个为active状态,一个为standby状态,当活动namenode发生故障时,备用namenode就会切换为活动的状态,接管它的任务并开始服务于来自客户端的请求,而且此过程不会有任何明显的中断。
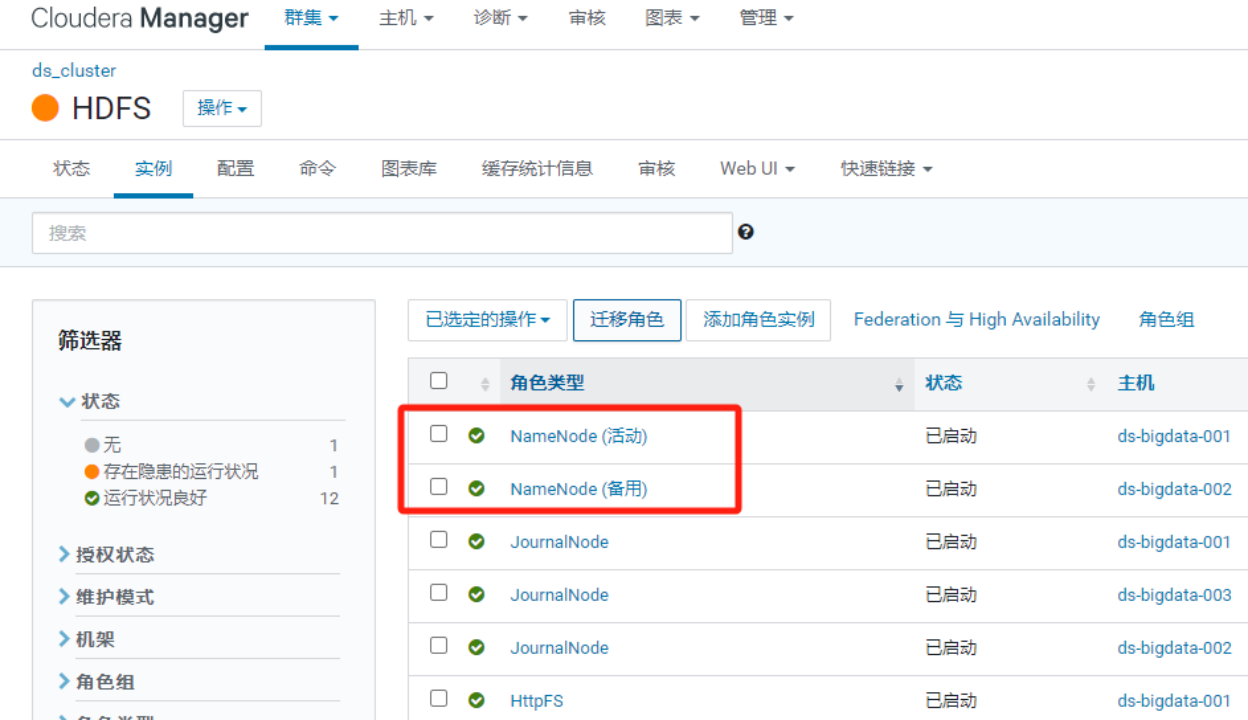
下图以CDH发行版下的HDFS集群启用的HA
Standby namenode 服务节点实现如下功能:
- 两个namenode 之间需要通过高可用共享存储实现编辑日志的共享。当备用 namenode 接管工作之后,它将通读共享编辑日志直至末尾,以实现与活动 namenode 的状态同步,并继续读取由活动 namenode 写入的新条目。
- datanode 需要同时向两个 namenode 发送数据块处理报告,因为数据块的映射信息存储在 namenode 的内存(BlocksMap)中,而非磁盘。
- 客户端使用特定的机制来处理namenode的失效问题,这一机制对用户是透明的。
- 备用 namenode 包含SecondaryNameNode的功能,备用namenode为活动的namenode命名空间设置周期性检查点。
4. HA切换原理与流程
HDFS HA 通过使用两个(多个) NameNode 来实现高可用性。一个是 Active NameNode,负责处理客户端的请求和元数据的管理;另一个是 Standby NameNode,处于备用状态,与 Active NameNode 保持同步。当 Active NameNode 发生故障时,Standby NameNode 会接管成为 Active NameNode,从而实现故障转移。为了保持元数据的一致性,Active NameNode 会定期将编辑日志传输给 Standby NameNode。这种方式确保了 HDFS 服务在 NameNode 故障时的持续可用性。