数据块 ⭐️⭐️
1. 数据块的概念理解
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位,HDFS同样也有块(block)的概念,它是抽象的块,而非整个文件作为存储单元,在Hadoop2.x版本下,默认大小是128M/256M,可以通过配置参数dfs.blocksize修改,且备份3份,且为了保证数据的安全,每个块会尽可能地存储于不同的DataNode节点上。按块存储的好处主要是屏蔽了文件的大小,提供数据的容错性和可用性。
重点说明:这里的block size只是逻辑上的限定大小,只是为了方便namennode管理数据块存储的一个逻辑概念,物理块是真实存储在datanode服务器上的磁盘上的文件。当一个物理块文件大小小于block size时,它不会占用一个block size大小的存储空间,而是它自己本身实际的文件大小。
例如,当我们把dfs.blocksize设置为128MB时,此时有一个存储在hdfs上的文件大小只有10MB,那么它存储在磁盘上实际的占用空间就是10MB,而不是128MB。下面也会带领大家通过案例实操验证这一说法。

2. 数据块的设计的优点
- 分散存储:利用块对文件进行切分,可以把大文件切分成多个小文件,这样原本只能存储在一块磁盘上的文件,可以分散存储在多个磁盘上,甚至存储在多个机器上的多个磁盘上。
- 简化存储管理:使用抽象块作为存储的单元,大大简化了存储子系统的设计。例如因为块的大小是固定的,所以计算单个磁盘能存储的块数就很简单了,再有,块只是存储一个块文件,并不需要关心此文件的权限等元数据属性。
- 增强数据容错性:数据最大的安全风险就是数据的丢失(或缺失),因为一个单独的块,是很容易进行复制备份的,所以可以将一个块备份在不同的磁盘上,备份在不同的主机的不同磁盘上,如果成本上允许,甚至于可以备份在不同机房的机器上。这样就极大的避免了数据丢失,从而极大的提高了数据的安全和高可用性。
3. 数据块占用磁盘实际大小案例演示
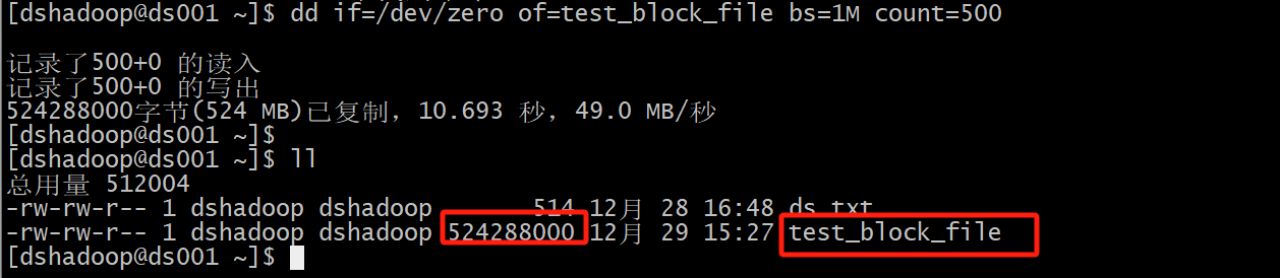
准备一个1G大小的文件
# 使用 dd 命令生成一个指定大小的测试文件
dd if=/dev/zero of=test_block_file bs=1M count=1000
# 参数说明:
# ---------------------------------------------------
# if :输入文件,这里使用 /dev/zero 设备,
# 它会持续输出 0 字节数据(即全是零的字节流)。
#
# of :输出文件,这里设置为 test_block_file,
# 表示生成的内容将写入这个文件。
#
# bs :块大小(block size),这里设置为 1M,
# 表示每次读写操作的块大小为 1 兆字节。
#
# count :块数,这里设置为 1000,
# 表示生成 1000 个 1MB 大小的块,
# 因此文件总大小约为 1000MB(即 1GB)。
# ---------------------------------------------------
执行结果:
上传文件到hdfs系统
上传到HDFS目录:/user/hdfs/hdfs_file
#创建hdfs目录上对应的用户文件夹
[root@ds-bigdata-001 ~]# hdfs dfs -mkdir /user/hdfs/
#上传本地文件到HDFS目录
[root@ds-bigdata-001 ~]# hdfs dfs -put /tmp/hdfs_file /user/hdfs/hdfs_file
[root@ds-bigdata-001 ~]#
在HDFS目录查看此文件信息,数据块默认大小为128MB,我们上传的文件使用1024进制换算后,大小为976.56MB ,会被分成8个block块。
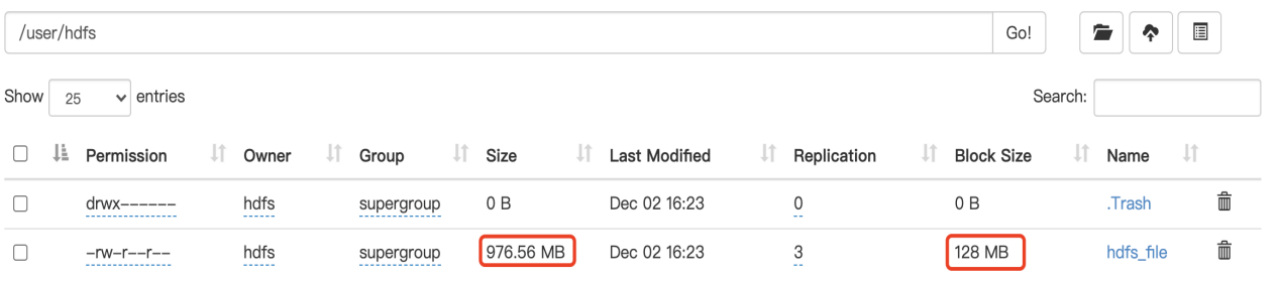
Permission:-rw-r—r--#和linux 权限结构一致
Size:文件大小为976.56MB(进制换算)
Block size:128MB
数据被分成8个块,切换每个块,查看具体块信息。
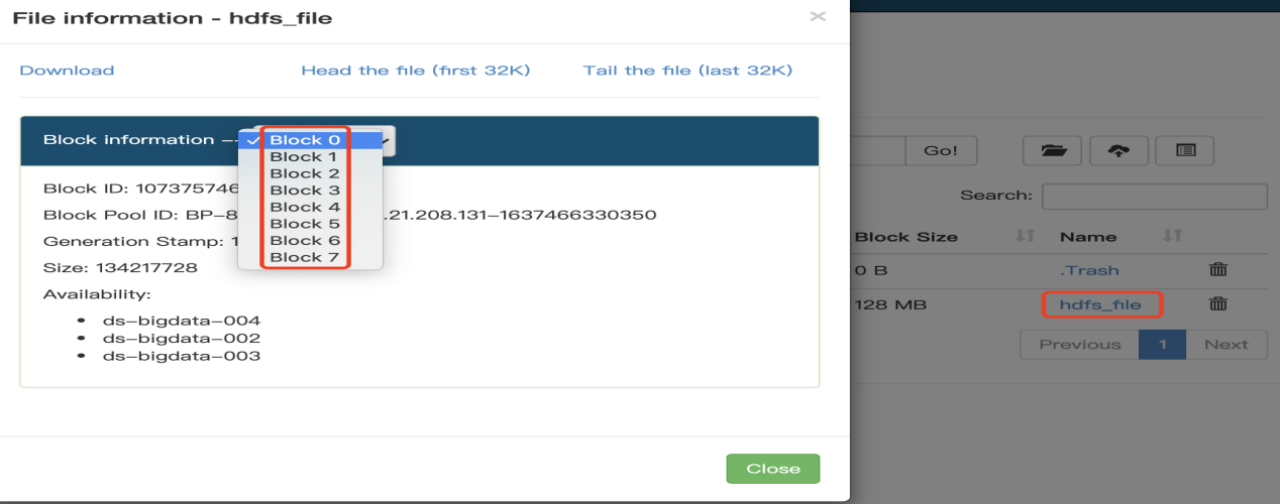
其中,0-6个块,大小�为128MB,最后一个块为80.56MB
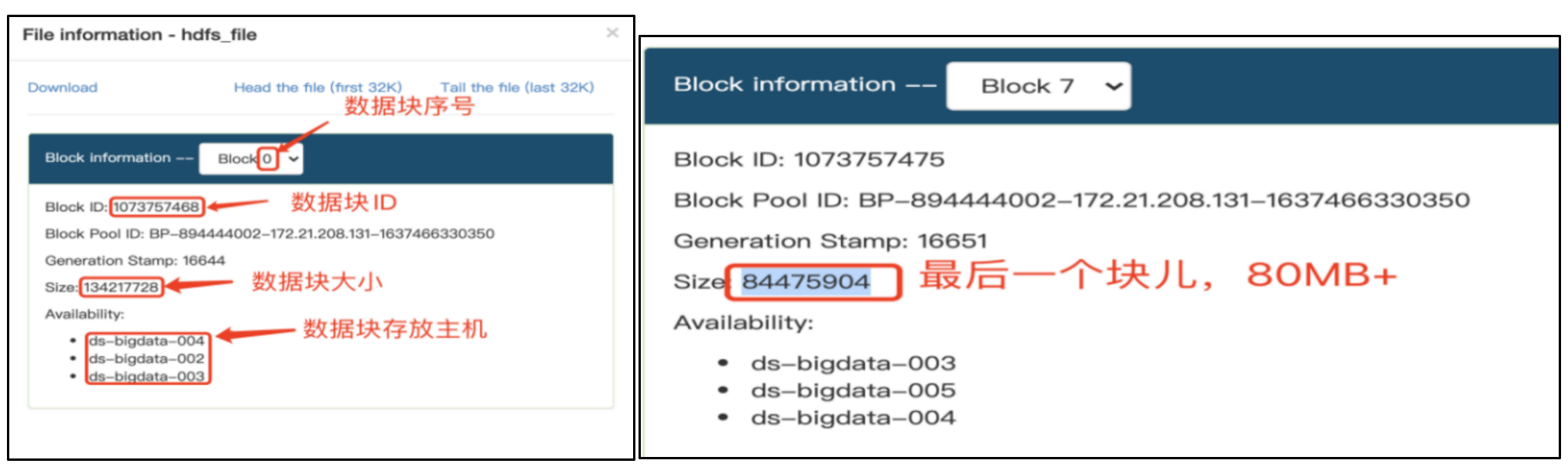
结论总结: 如上图,最后一个块实际占用的存储空间大小只有80MB,也验证了数据块的物理存储不一定就是block size的大小。
思考:实际占用存储空间是多少?
查看对应的具体空间(虚拟机环境,阿里云环境权限)
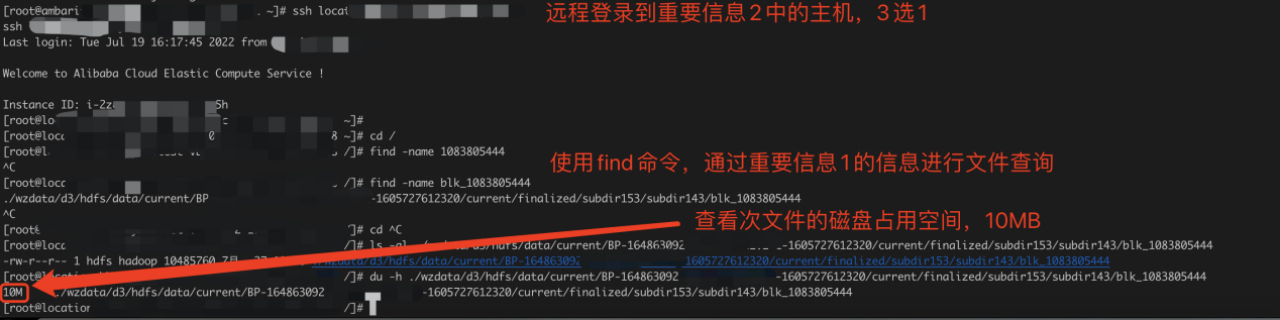
结论:80MB的文件,占用一个BLOCK块地址,实际磁盘占用80MB * 3
4. 数据块存放策略(机架感知)
- 一般默认存放 3 份副本:也是容错安全考虑
- 假设我们提交的数据正好是DataNode节点,那么根据就近原则这个block就是放置在这个DataNode节点;如果不是就随机挑选一台资源空闲的节点存储。
- 第二个副本存放在不同与当前节点所在机架的某一个节点上;
- 第三个副本存放在与第二个副本相同机架的不同节点上;
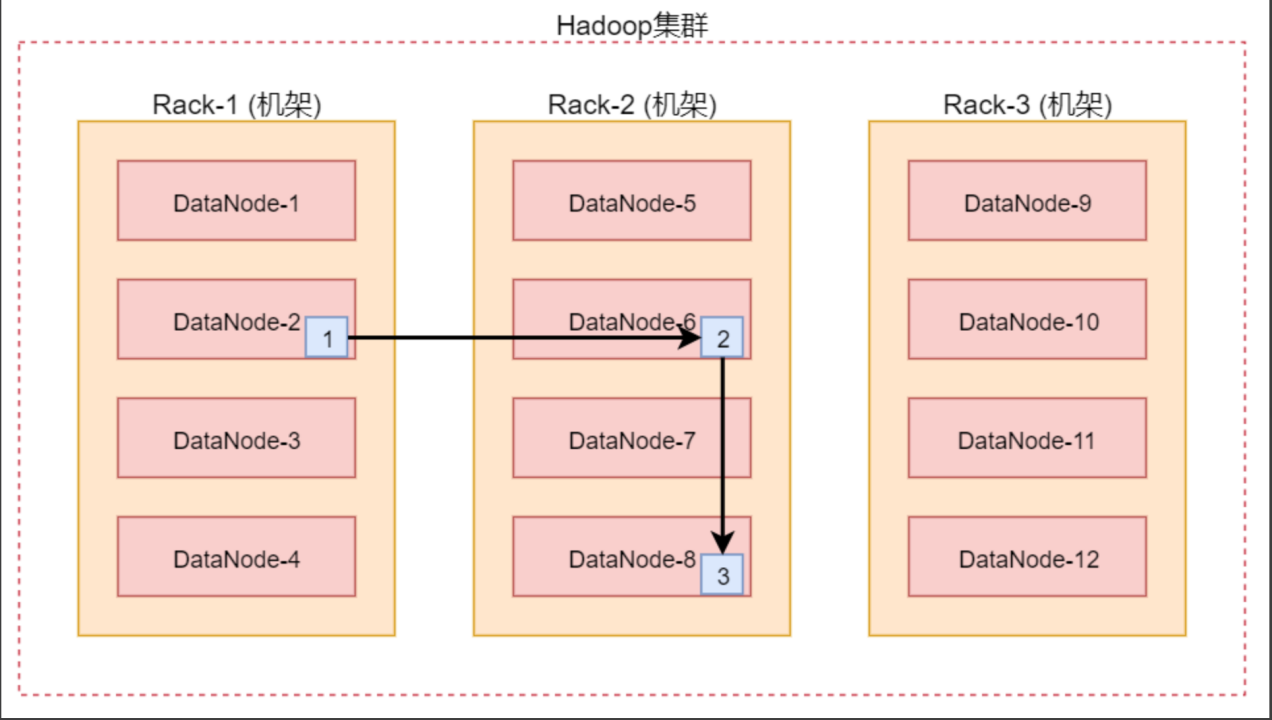
这样的策略可以保证对该block所属文件的访问能够优先在本rack下找到,��如果整个rack发生了异常,也可以在另外的rack上找到该block的副本。这样足够的高效,并且同时做到了数据的容错。
实践出真知,上才艺
案例环境:2 + 15 主机机架配置如下:
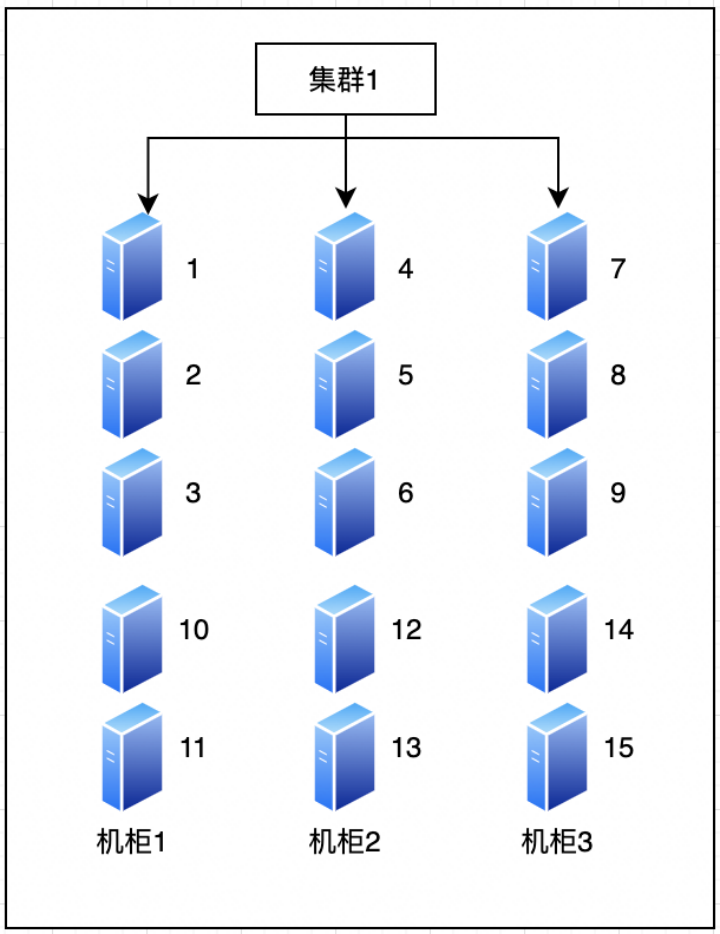
在节点5上传1个1G测试文件
到主机5上执行
dd if=/dev/zero of=test1_1G.txt bs=1M count=1024
hdfs dfs -put test1_1G.txt /tmp
存储编号所在节点对应信息
| Block 编号 | Block1位置 | 2位置 | 3位置 |
|---|---|---|---|
| 0 | 5 | 1 | 12 |
| 1 | 5 | 3 | 11 |
| 2 | 5 | 8 | 9 |
| 3 | 5 | 2 | 3 |
| 4 | 5 | 1 | 11 |
| 5 | 5 | 7 | 15 |
| 6 | 5 | 8 | 9 |
| … |