Hive架构组成 ⭐️⭐️
理解 ⭐️⭐️
由图中可以看出,Hive 是建立在 Hadoop 基础上的,是针对 Hadoop MapReduce 开发的技术。Hive 的组件包括客户端组件和服务端组件。下面我们对这些组件进行逐一说明。
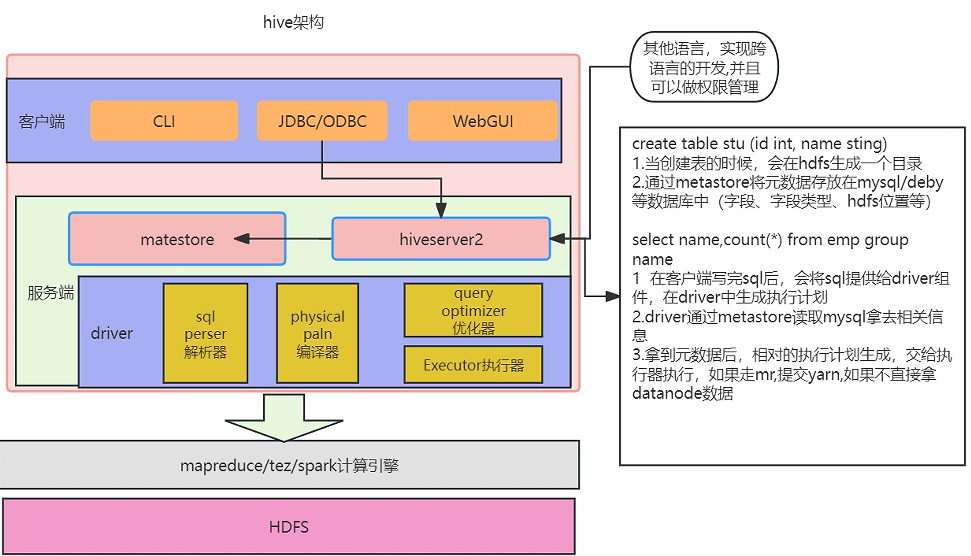
客户端组件
- CLI:Command Line Interface命令行接口。最常用的客户端组件就是CLI,CLI启动的时候,会同时启动一个Hive副��本。
Client是Hive的客户端,用于连接HiveServer。在启动 Client模式的时候,需要指出Hive Server所在的节点,并且在该节点启动Hive Server。图上所示的架构图里没有写上Thrift客户端,但是Hive架构的许多客户端接口都是建立在Thrift客户端之上的,包括JDBC和ODBC接口。
- Web GUI:Hive客户端提供了一种通过网页访问Hive所提供的服务的方式。这个接口对应Hive的HWI(Hive Web Interface)组件,使用前要启动HWI服务。
服务端组件
- Driver组件:该组件包括解析器、编译器、优化器、执行器,其作用是完成 HiveQL(类SQL)查询语句的词法分析、语法分析、编译、优化及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
- MetaStore组件:元数据服务组件,这个组件存储Hive的元数据。Hive的元数据存储在关系数据库里,Hive支持的关系数据库有Derby、MySQL等。Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)表的数据所在目录等。元数据对于Hive十分重要,因此Hive支持把MetaStore服务独立出来,安装到远程的服务器集群里从而解耦Hive服务和MetaStore服务,保证Hive运行的健壮性。关于MetaStore组件,我们下面再展开讲解一下:
Hive的MetaStore组件是Hive元数据的集中存放地。MetaStore组件包括两个部分:MetaStore服务和后台数据的存储。
后台数据存储的介质就是关系数据库。例如Hive默认的嵌入式磁盘数据库Derby还有MySQL数据库。MetaStore�服务是建立在后台数据存储介质之上,并且可以和Hive服务进行交互的服务组件。
默认情况下,MetaStore服务和Hive服务是安装在一起的,运行在同一个进程当中,也可以把MetaStore服务从Hive服务中剥离出来独立安装在一个集群里,Hive远程调用MetaStore服务。
我们可以把元数据这一层放到防火墙之后,当客户端访问Hive服务时就可以连接到元数据这一层从而提供更好的管理性能和安全保障。使用远程的MetaStore服务,可以让MetaStore服务和Hive服务运行在不同的进程里,这样既保证了Hive的稳定性,又提升了Hive服务的效率。
- hiveServer2服务:hiveServer2服务是Facebook开发的一个软件框架,它用来进行可扩展且跨语言服务的开发。Hive集成了该服务,可以让不同的编程语言调用Hive的接口。
正常的hive仅允许使用HiveQL执行查询、更新等操作,并且该方式比较笨拙单一。幸好Hive提供了轻客户端的实现,通过HiveServer或者HiveServer2,客户端可以在不启动CLI的情况下对Hive中的数据进行操作,两者都允许远程客户端使用多种编程语言如Java、Python向Hive提交请求、取回结果,使用jdbc协议连接hive的thriftserver服务器,它可以实现远程访问。
Hive 架构组件列表
1. 用户接口 (Client)
-
提供多种访问方式,如:
-
CLI (command-line interface):命令行界面。
-
JDBC/ODBC:允许Java、Python等应用程序通过标准接口访问Hive。
-
2. 元数据 (Metastore)
-
用于存储Hive的元数据信息,是Hive的核心组件。
-
元数据包括:
-
表名
-
表所属的数据库(默认为 default)
-
表的拥有者
-
列/分区字段
-
表的类型(例如,是否为外部表)
-
表的数据在HDFS上的存储目录等。
-
-
存储方式:默认存储在Hive自带的Derby数据库中,但在生产环境中,强烈推荐使用外部数据库(如MySQL)来存储元数据。
3. Hadoop
-
Hive构建于Hadoop之上,并依赖其核心组件:
-
HDFS:用于存储Hive表的数据。
-
MapReduce:作为Hive的默认计算引擎(新版本中也支持Spark、Tez等)。
-
4. 驱动器 (Driver)
-
驱动器是Hive的核心,负责将SQL查询转化为具体的计算任务,其工作流程包含以下几个主要组件:
-
解析器 (SQL Parser):
-
将SQL字符串转换成抽象语法树(AST)。
-
对AST进行语法分析,检查表或字段是否存在、SQL语义是否有误等。
-
-
编译器 (Compiler):
- 将AST编译生成逻辑执行计划。
-
优化器 (Query Optimizer):
- 对逻辑执行计划进行优化,以提升查询效率。
-
执行器 (Execution):
- 将优化后的逻辑执行计划转换成可以运行的物理计划��(对于Hive来说,就是具体的MapReduce或Spark任务),并提交到集群上执行。
-