Hive 表详解 ⭐️⭐️
内部表、外部表的区别: 重点掌握 ⭐️⭐️⭐️
内部表、外部表的生产应用: 理解记忆 ⭐️⭐️
分区表&分桶表: 重点掌握 ⭐️⭐️⭐️
Hive 有四种基本的表类型:内部表(Managed Table)、外部表(External Table)、分区表(Partitioned Table)和分桶表(Bucketed Table),它们分别对应不同的业务需求。
我们可以将它们从两个维度进行分组理解:
- 数据管理维度:内部表和外部表,核心区别在于 Hive 是否完全控制数据的生命周期。
- 数据组织维度:分区表和分桶表,核心目标是通过优化数据存储结构来提升查询性能。
其中,��分区表在企业级应用中最为常见,可以说百分之八九十的表都是分区表。

1. 核心维度一:内部表 vs 外部表
这个维度决定了 Hive 与数据之间的“关系”,是 Hive 完全拥有数据,还是仅仅“引用”数据。
1.1 内部表 (Managed Table)
内部表是 Hive 默认的表类型。当创建内部表时,Hive 会(或多或少地)控制着数据的整个生命周期。
理论核心:
- 数据位置:默认情况下,Hive 会将表的数据存储在由配置项
hive.metastore.warehouse.dir所定义的目录(默认为/user/hive/warehouse)的子目录下。 - 生命周期:当我们删除一个内部表时,Hive 会同时删除表的元数据和存储在 HDFS 上的数据文件。因此,内部表不适合与其他工具共享数据。
案例实操:内部表
(1)准备原始数据
在服务器路径 /home/hewwen8888/data 下创建 ch4_emp.txt 文件。
[root@hadoop102 datas]$ vim ch4_emp.txt
1001 emp1
1002 emp2
1003 emp3
1004 emp4
1005 emp5
1006 emp6
1007 emp7
1008 emp8
1009 emp9
(2)创建内部表
创建一个普通的内部表,Hive 会在默认仓库路径下为其创建目录。
CREATE TABLE IF NOT EXISTS ds_hive.ch4_emp(
id INT,
name STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
(3)加载数据
LOAD DATA LOCAL INPATH "/home/hewwen8888/data/ch4_emp.txt" OVERWRITE INTO TABLE ds_hive.ch4_emp;
(4)查看表的类型
通过 DESC FORMATTED 命令可以看到表的类型为 MANAGED_TABLE。
DESC FORMATTED ds_hive.ch4_emp;
-- 输出结果中会包含
-- Table Type: MANAGED_TABLE
(5)删除内部表
执行删除操作后,不仅表的元数据被清除了,HDFS 上对应的数据文件也会被一并删除。
DROP TABLE ds_hive.ch4_emp;
1.2 外部表 (External Table)
对于外部表,Hive 并不认为其完全拥有这份数据,它只负责管理表的元数据。
理论核心:
- 数据位置:创建外部表时,必须使用
LOCATION关键字明确指定一个 HDFS 路径,数据文件存放在该路径下。 - 生命周期:删除外部表时,Hive 只会删除元数据,不会删除 HDFS 上的数据文件。这使得数据可以在多个表或不同工具之间安全地共享。
案例实操:外部表与内部表的交互
(1)创建一个指向内部表路径的外部表
这是一个有趣的实验:假设我们有一个内部表 ds_hive.ch4_emp_01,它的数据存储在 /user/hive/warehouse/ds_hive.db/ch4_emp_01。现在我们创建一个外部表,让它的 LOCATION 指向同一个路径。
CREATE EXTERNAL TABLE IF NOT EXISTS ds_hive.ch4_emp_03_w(
id INT,
name STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/ds_hive.db/ch4_emp_01';
(2)测试数据同步
-
向内部表插入数据:
INSERT INTO TABLE ds_hive.ch4_emp_01 SELECT 1, '张三';查询外部表
SELECT * FROM ds_hive.ch4_emp_03_w;,可以看到外部表数据同步变化。 -
向外部表插入数据:
INSERT INTO TABLE ds_hive.ch4_emp_03_w SELECT 2, '李四';查询内部表
SELECT * FROM ds_hive.ch4_emp_01;,可以看到内部表数据也同步变化。因为它们指向的是同一个 HDFS 目录。
(3)测试删除操作的影响
现在,我们删除内部表。
DROP TABLE ds_hive.ch4_emp_01;
结果:因为 ds_hive.ch4_emp_01 是内部表,Hive 会将 HDFS 上的数据文件一并删除。此时再查询外部表 ds_hive.ch4_emp_03_w,会发现外部表也查不到数据了,因为它指向的数据目录已经被清空。
1.3 内部表与外部表的区别与应用 (⭐️⭐️⭐️重点掌握)
| 特性 | 内部表 (Managed Table) | 外部表 (External Table) |
|---|---|---|
| 关键字 | 无 (默认) | EXTERNAL |
| 数据所有权 | Hive 拥有并管理数据 | 外部进程或用户拥有数据,Hive 仅引用 |
DROP 操作 | 删除元��数据 + 数据 | 仅删除元数据,数据保留 |
LOCATION | 可选,默认在 Hive 仓库 | 必须指定 |
| 数据验证 | 遵循 Hive 的 schema on read (读时模式) | 遵循 Hive 的 schema on read (读时模式) |
| 表结构修改 | 直接修改元数据 | 修改后可能需要 MSCK REPAIR TABLE 来同步分区信息 |
Schema on Read vs Schema on Write: 传统数据库是
schema on write(写时模式),在写入数据时就进行格式校验。而 Hive 是schema on read(读时模式),加载数据时(LOAD DATA)只做文件移动或复制,不校验数据格式,只有在真正读取查询时才进行解析和校验。这使得 Hive 的数据加载速度非常快。
生产应用场景 (⭐️⭐️理解记忆)
- 使用内部表:
- ETL 过程中产生的中间表、临时表。这些表生命周期短,用完后可以方便地连同数据一起清理。
- 完全由 Hive SQL 生成和管理的结果表。
- 使用外部表:
- 原始日志数据(如 Nginx 日志、埋点日志)。这些数据由其他程序(如 Flume, Spark Streaming)生成,Hive 仅用于分析,绝不能因为误删表而丢失原始数据。
- 需要被多个工具或框架共享的数据源。例如,一份数据既要用 Hive 分析,也要用 Spark ML 进行模型训练。
- 需要长期保留的源数据层 (ODS) 表。
2. 核心维度二:分区表 vs 分桶表
这个维度通过在物理上组织数据文件来优化查询性能,避免不必要的全表扫描。
2.1 分区表 (Partitioned Table) (⭐️⭐️⭐️重点掌握)
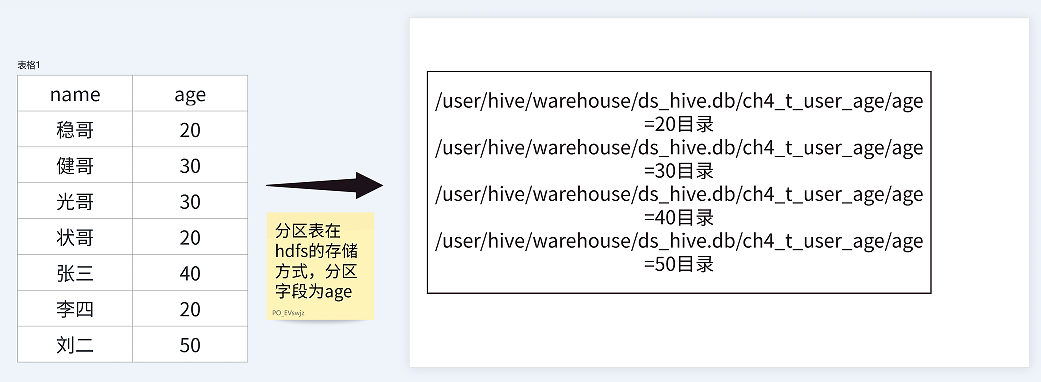
分区表将一张大表的数据,按照分区键的值,分散存储到 HDFS 上的多个子目录中。查询时,如果 WHERE 条件中包含分区键,Hive 会直接扫描对应的分区目录,从而极大地提升查询效率。
静态分区
静态分区是指在加载数据时,需要手动、明确地指定数据要加载到哪个分区。
(1)创建分区表
使用 PARTITIONED BY 关键字定义分区字段。分区字段是表的“伪列”,它不存储在数据文件中,而是体现在 HDFS 的目录结构上。
-- 创建一个按天分区的表
CREATE TABLE IF NOT EXISTS ds_hive.ch4_t_par_emp(
id INT,
name STRING
)
PARTITIONED BY (day STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
(2)加载数据到指定分区
使用 LOAD DATA 时,必须通过 PARTITION 子句指定分区。
LOAD DATA LOCAL INPATH "/home/hewwen8888/data/ch4_emp.txt" OVERWRITE INTO TABLE ds_hive.ch4_t_par_emp PARTITION(day='20250602');
也可以使用 INSERT 语句从其他表加载数据。
INSERT OVERWRITE TABLE ds_hive.ch4_t_par_emp PARTITION (day = '20250602')
SELECT id, name FROM ds_hive.ch4_t_par_emp WHERE day='20240110';
(3)查询分区数据
在查询时带上分区条件,Hive 就会执行“分区裁剪”,只扫描指定分区。
SELECT id, name, day FROM ds_hive.ch4_t_par_emp WHERE day='20250602';
(4)分区管理
- 查看所有分区:
SHOW PARTITIONS ds_hive.ch4_t_par_emp;
- 增加单个/多个分区:
-- 增加单个分区ALTER TABLE ds_hive.ch4_t_par_emp ADD PARTITION(day='20250603');-- 增加多个分区(注意语法,没有逗号)ALTER TABLE ds_hive.ch4_t_par_emp ADD PARTITION(day='20250604') PARTITION(day='20250605');
- 删除单个/多个分区:
-- 删除单个分区ALTER TABLE ds_hive.ch4_t_par_emp DROP PARTITION (day='20250604');-- 删除多个分区(注意语法,有逗号)ALTER TABLE ds_hive.ch4_t_par_emp DROP PARTITION (day='20250605'), PARTITION(day='20250606');
分区修复
若用户手动在 HDFS 上创建/删除分区目录,Hive 的元数据是感知不到的,这会导致元数据与物理路径不一致。
思考:如果手动在 HDFS 添加一个分区目录(如 .../day=20250606)并上传文件,在分区表中能查到新分区的数据吗?
答案:不能,因为元数据中没有这个分区的信息。
这时就需要修复分区,同步元数据和 HDFS 路径。
ADD PARTITION:手动添加元数据。DROP PARTITION:手动删除元数据。MSCK REPAIR TABLE(常用):自动扫描 HDFS 路径,修复元数据。-- 推荐使用,会自动添加 HDFS 上存在但元数据中缺失的分区MSCK REPAIR TABLE ds_hive.ch4_t_par_emp;-- 完整语法-- MSCK REPAIR TABLE table_name [ADD/DROP/SYNC PARTITIONS];
多级分区
如果单级分区(如按天)的数据量依然很大,可以使用多级分区进一步细化,例如按天再按小时。
-- 创建二级分区表
CREATE TABLE IF NOT EXISTS ds_hive.ch4_t_par_emp2(
id INT,
name STRING
)
PARTITIONED BY (day STRING, hour STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
-- 加载数据到二级分区
LOAD DATA LOCAL INPATH "/home/hewwen8888/data/ch4_emp.txt" OVERWRITE INTO TABLE ds_hive.ch4_t_par_emp2 PARTITION(day='20250602', hour='14');
-- 查询二级分区
SELECT * FROM ds_hive.ch4_t_par_emp2 WHERE day='20250602' AND hour='14';
动态分区
当需要一次性将数据插入到多个分区时,如果手动为每个分区写�一条 INSERT 语句会非常繁琐。动态分区允许 Hive 根据查询结果的最后一列或几列的值,自动推断并创建分区。
(1)相关参数设置
-- 动态分区功能总开关(默认 true,开启)
SET hive.exec.dynamic.partition=true;
-- 设置为非严格模式,允许所有分区字段都为动态
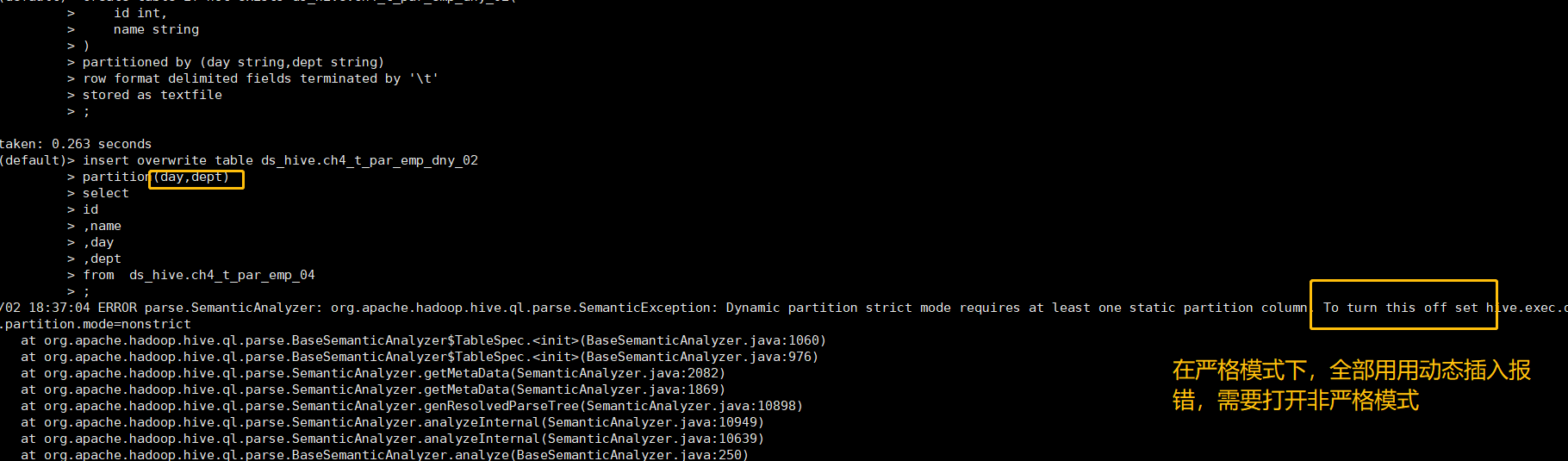
-- strict 模式下,至少要有一个静态分区
SET hive.exec.dynamic.partition.mode=nonstrict;
-- 其他常用参数
SET hive.exec.max.dynamic.partitions=1000; -- 一条 SQL 最多创建的分区数
SET hive.exec.max.dynamic.partitions.pernode=100; -- 每个节点最多创建的分区数
(2)案例实操:单动态分区
需求:将源表 ch4_t_par_emp_01 的数据,按照 day 字段的值,动态插入到目标分区表 ch4_t_par_emp_dny_01 中。
- 创建目标分区表:
CREATE TABLE IF NOT EXISTS ds_hive.ch4_t_par_emp_dny_01(id INT,name STRING)PARTITIONED BY (day STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
- 执行动态分区插入:
SET hive.exec.dynamic.partition.mode=nonstrict;INSERT OVERWRITE TABLE ds_hive.ch4_t_par_emp_dny_01PARTITION(day) -- 声明 day 是动态分区字段SELECTid,name,day -- 动态分区字段必须是 SELECT 语句的最后一列FROM ds_hive.ch4_t_par_emp_01;
要点:Hive 根据
SELECT语句中列的位置来推断分区值。PARTITION(day)对应SELECT的最后一列,PARTITION(day, hour)对应最后两列。列的顺序和数量必须严格匹配。
(3)案例实操:混合分区与全动态分区
- 半动态分区(一个静态,一个动态):
-- 目标表有两个分区字段:day, deptCREATE TABLE ds_hive.ch4_t_par_emp_dny_02(id INT, name STRING)PARTITIONED BY (day STRING, dept STRING);-- day 是静态分区,dept 是动态分区INSERT OVERWRITE TABLE ds_hive.ch4_t_par_emp_dny_02PARTITION(day='20250601', dept)SELECT id, name, dept FROM ds_hive.ch4_t_par_emp_04;
- 全动态分区:
SET hive.exec.dynamic.partition.mode=nonstrict;INSERT OVERWRITE TABLE ds_hive.ch4_t_par_emp_dny_02PARTITION(day, dept)SELECT id, name, day, dept FROM ds_hive.ch4_t_par_emp_04;
2.2 分桶表 (Bucketed Table)
分区提供的是目录级别的粗粒度数据划分。当分区内的数据文件依然很大时,可以使用分桶来进行更细粒度的数据组织。
基本原理:分桶是针对数据文件的。它根据分桶键(通常是表的某个列)的哈希值,对分桶数取模,将数据均匀地写入固定数量的文件(桶)中。
主要优点:
- 提高 Join 查询效率:如果两个表在 Join 的 key 上都进行了分桶,且分桶数成倍数关系,Hive 可以执行更高效的
Bucket Map Join。 - 方便高效抽样:可以对桶进行抽样,快速获取数据的样本。
分桶表基本语法
(1)创建分桶表
使用 CLUSTERED BY 指定分桶键,INTO N BUCKETS 指定分桶数量。
CREATE TABLE ds_hive.ch4_emp_buck(
id INT,
name STRING
)
CLUSTERED BY(id) INTO 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
(2)加载数据到分桶表
注意:向分桶表加载数据通常需要通过
INSERT ... SELECT的方式,因为这会触发 MapReduce 作业,在 Reduce 阶段根据哈希值将数据写入不同的桶。直接LOAD DATA可能不会正确分桶(取决于 Hive 版本)。
-- 准备一张源数据表
CREATE TABLE ds_hive.ch4_source_data (id INT, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/hewwen8888/data/ch4_emp.txt' INTO TABLE ds_hive.ch4_source_data;
-- 通过 INSERT ... SELECT 方式加载数据到分桶表
INSERT OVERWRITE TABLE ds_hive.ch4_emp_buck
SELECT id, name FROM ds_hive.ch4_source_data;
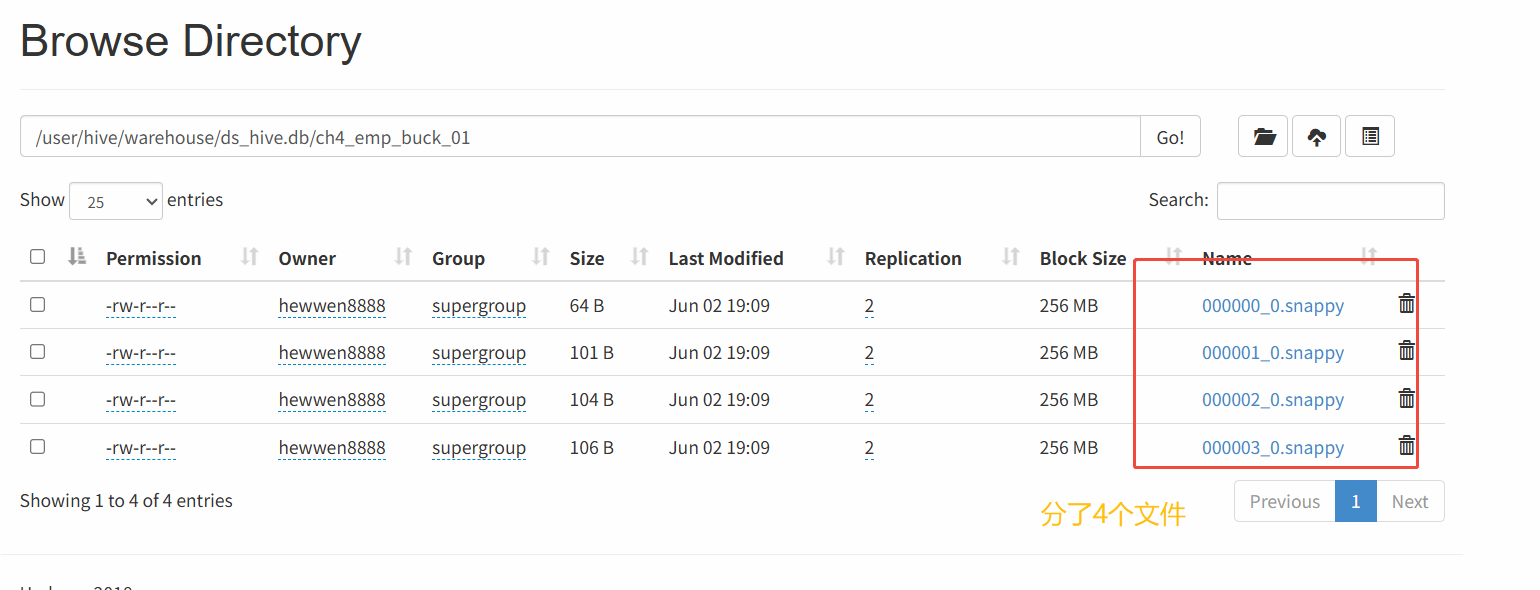
(3)查看分桶结果
在 HDFS 对应的表目录下,可以看到生成了 4 个数据文件,代表 4 个桶。
3. 表的创建与管理
在理解了核心概念后,我们来系统地看一下表的通用操作。
3.1 完整建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
字段解释说明:
EXTERNAL: 创建外部表。PARTITIONED BY: 创建分区表。CLUSTERED BY: 创建分桶表。SORTED BY: 对桶内数据进行排序(不常用)。ROW FORMAT DELIMITED: 定义行格式和分隔符。FIELDS TERMINATED BY char: 字段间分隔符。COLLECTION ITEMS TERMINATED BY char: 集合(如 ARRAY)元素间分隔符。MAP KEYS TERMINATED BY char: Map 的 Key-Value 间分隔符。LINES TERMINATED BY char: 行分隔符。
SERDE: 指定自定义的序列化/反序列化器。STORED AS: 指定存储文件类型,如TEXTFILE,SEQUENCEFILE,ORC,PARQUET。LOCATION: 指定表在 HDFS 上的存储位置。
建表示例(复杂版):
CREATE TABLE IF NOT EXISTS ds_hive.ch4_user_demo1(
id INT COMMENT '用户id',
name STRING COMMENT '姓名',
age INT COMMENT '年龄',
subordinates ARRAY<STRING> COMMENT '下属',
deductions MAP<STRING, FLOAT> COMMENT '税务种类',
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT> COMMENT '地址'
)
COMMENT '用户表'
PARTITIONED BY(data_dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '|'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION 'hdfs://ds/user/hive/warehouse/ds_hive.db/ch4_user_demo1';
3.2 其他建表方式
(1)CTAS: Create Table As Select
根据 SELECT 查询结果直接创建表,新表会包含查询结果的数据和结构。
CREATE TABLE [IF NOT EXISTS] table_name
[STORED AS file_format]
AS
SELECT ...;
-- 示例
CREATE TABLE ds_hive.ch4_emp2
STORED AS TEXTFILE
AS
SELECT id, name FROM ds_hive.ch4_emp;
(2)Create Table Like
复制一张已存在表的结构,但不复制数据。
CREATE TABLE [IF NOT EXISTS] new_table_name LIKE existing_table_name;
-- 示例
CREATE TABLE ds_hive.ch4_emp3 LIKE ds_hive.ch4_emp;
3.3 修改表 (ALTER TABLE)
(1)重命名表
ALTER TABLE ds_hive.ch4_emp RENAME TO ds_hive.ch4_emp1;
注意:重命名内部表时,其在 HDFS 上的目录也会同步重命名。而重命名外部表时,
LOCATION指向的 HDFS 目录不会改变。
(2)增加/修改/替换列
- 增加列 (
ADD COLUMNS):在现有列之后、分区列之前添加新列。ALTER TABLE ds_hive.ch4_emp1 ADD COLUMNS(age INT COMMENT '年龄'); - 修改列 (
CHANGE COLUMN):修改列名、数据类型、注释。数据类型只能从小范围转为大范围(如
INT->DOUBLE),反之不行。ALTER TABLE ds_hive.ch4_emp1 CHANGE COLUMN age ages DOUBLE; - 替换列 (
REPLACE COLUMNS):用一组新列完全替换表原有的所有非分区列。ALTER TABLE ds_hive.ch4_emp1 REPLACE COLUMNS (id INT, emp_name STRING);
总结:所有
ALTER TABLE操作修改的都是 Hive 的元数据信息,不会去修改 HDFS 上的原始数据文件�。 新增的列在查询旧数据时会显示为NULL。
3.4 删除与清空表
(1)删除表 (DROP TABLE)
DROP TABLE ds_hive.ch4_emp1;
- 删除内部表:删除元数据和 HDFS 数据。
- 删除外部表:仅删除元数据。
(2)清空表 (TRUNCATE TABLE)
清空表中的所有数据,但保留表结构。
TRUNCATE TABLE ds_hive.ch4_emp1;
注意:
TRUNCATE命令只能用于内部表,执行该操作会删除 HDFS 目录下的数据文件。它不能用于外部表。