Join详解及底层原理 ⭐️⭐️⭐️
掌握 ⭐️⭐️⭐️
核心 Join 类型
准备工作:示例数据
为了清晰地演示不同 JOIN 的效果,后续所有案例都将基于以下两张表。
订单表:ds_hive.ch6_t_order
| order_id | user_id | product |
|---|---|---|
| 1 | 1 | 商品 1 |
| 2 | 2 | 商品 2 |
| 3 | 3 | 商品 3 |
| 4 | 4 | 商品 4 |
用户表:ds_hive.ch6_t_user
| user_id | user_name |
|---|---|
| 1 | user1 |
| 5 | user5 |
| 3 | user3 |
| 7 | user7 |
1. Inner Join (内连接)
内连接是最常用的 Join 类型。它只返回两个表中连接键(ON 子句中的列)能够互相匹配的行。如果某一行在一个表中存在,但在另一个表中没有匹配的键,那么这一行将被舍弃。
逻辑示意图:
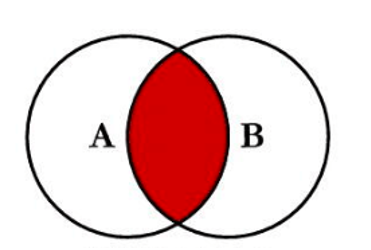
案例:查询成功匹配到用户信息的订单
SELECT
t1.order_id,
t1.user_id,
t1.product,
t2.user_name
FROM ds_hive.ch6_t_order t1
JOIN ds_hive.ch6_t_user t2
ON t1.user_id = t2.user_id;
结果: 只有 user_id 为 1 和 3 的记录在两个表中都存在,因此只有它们被保留。
| order_id | user_id | product | user_name |
|---|---|---|---|
| 1 | 1 | 商品 1 | user1 |
| 3 | 3 | 商品 3 | user3 |
2. Outer Join (外连接)
外连接用于返回一个表中所有记录,以及另一个表中匹配的记录。根据保留哪个表的全部数据,分为左外连接、右外连接和满外连接。
左外连接 (Left Join)
LEFT JOIN 会返回左表(FROM 子句后的第一个表)的所有行。对于左表中的每一行,如果在右表中找到了匹配的行,则返回匹配行;如果找不到,则右表的列将用 NULL 填充。
逻辑示意图:
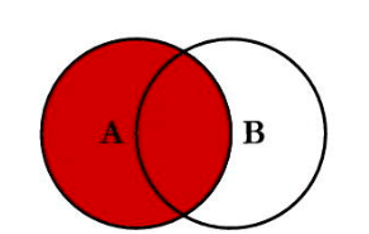
案例:查询所有订单及其对应的用户信息(无论用户是否存在)
SELECT
t1.order_id,
t1.user_id,
t1.product,
t2.user_name
FROM ds_hive.ch6_t_order t1
LEFT JOIN ds_hive.ch6_t_user t2
ON t1.user_id = t2.user_id;
结果: 左表(订单表)的所有记录都被保留。user_id 为 2 和 4 的订单在用户表中没有匹配项,因此 user_name 为 NULL。
| order_id | user_id | product | user_name |
|---|---|---|---|
| 1 | 1 | 商品 1 | user1 |
| 2 | 2 | 商品 2 | null |
| 3 | 3 | 商品 3 | user3 |
| 4 | 4 | 商品 4 | null |
右外连接 (Right Join)
RIGHT JOIN 与 LEFT JOIN 相反,它会返回右表(JOIN 关键字后的表)的所有行。如果右表中的行在左表中找不到匹配项,则左表的列将用 NULL 填充。
逻辑示意图:
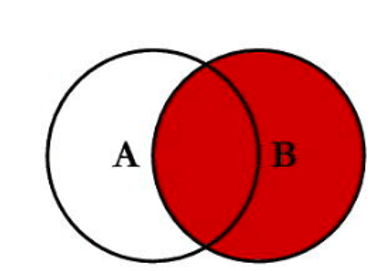
案例:查询所有用户及其订单信息(无论用户是否下过单)
SELECT
t1.order_id,
t2.user_id,
t1.product,
t2.user_name
FROM ds_hive.ch6_t_order t1
RIGHT JOIN ds_hive.ch6_t_user t2
ON t1.user_id = t2.user_id;
结果: 右表(用户表)的所有记录都被保留。user_id 为 5 和 7 的用户没有订单记录,因此订单相关列为 NULL。
| order_id | user_id | product | user_name |
|---|---|---|---|
| 1 | 1 | 商品 1 | user1 |
| null | 5 | null | user5 |
| 3 | 3 | 商品 3 | user3 |
| null | 7 | null | user7 |
满外连接 (Full Outer Join)
FULL OUTER JOIN 结合了 LEFT JOIN 和 RIGHT JOIN 的功能。它会返回两个表中的所有行。如果某一行在一个表中没有匹配项,则另一个表的列将用 NULL 填充。
逻辑示意图:
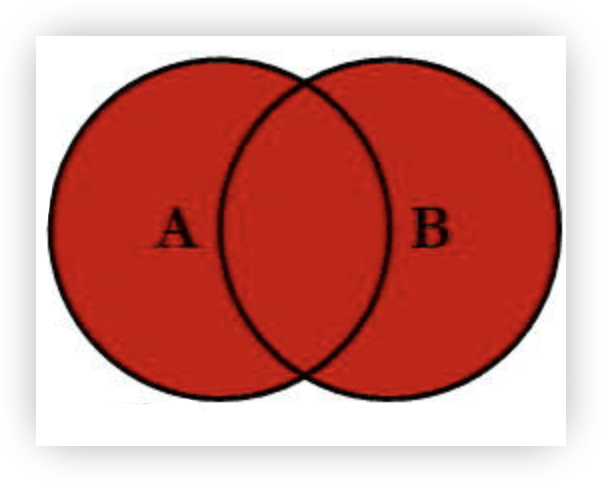
案例:查询所有订单和所有用户的信息
SELECT
t1.order_id,
COALESCE(t1.user_id, t2.user_id) AS user_id, -- 合并 user_id
t1.product,
t2.user_name
FROM ds_hive.ch6_t_order t1
FULL OUTER JOIN ds_hive.ch6_t_user t2
ON t1.user_id = t2.user_id;
结果: 包含所有订单和所有用户。
| order_id | user_id | product | user_name |
|---|---|---|---|
| 1 | 1 | 商品 1 | user1 |
| 2 | 2 | 商品 2 | null |
| 3 | 3 | 商品 3 | user3 |
| 4 | 4 | 商品 4 | null |
| null | 5 | null | user5 |
| null | 7 | null | user7 |
特殊 Join 与查询模式
3. 查找不匹配记录 (Anti-Join)
这是一种常见的查询模式,用于找出存在于一个表但不存在于另一个表中的记录。它通常通过 LEFT JOIN 结合 WHERE ... IS NULL 来实现。
逻辑示意图:
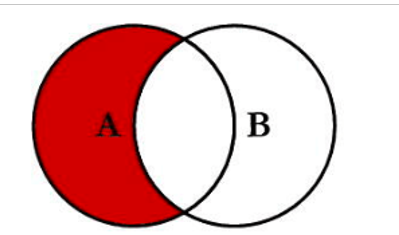
案例:找出下了订单但用户信息不存在的“幽灵”订单
SELECT
t1.*
FROM ds_hive.ch6_t_order t1
LEFT JOIN ds_hive.ch6_t_user t2
ON t1.user_id = t2.user_id
WHERE t2.user_id IS NULL; -- 关键过滤条件
结果��: 返回 user_id 为 2 和 4 的订单记录,因为它们在用户表中没有匹配项。
| order_id | user_id | product |
|---|---|---|
| 2 | 2 | 商品 2 |
| 4 | 4 | 商品 4 |
4. 左半连接 (Left Semi Join)
LEFT SEMI JOIN 是一种更高效的 IN / EXISTS 子查询替代方案。它的核心思想是:“只看不取”。它根据右表的数据来过滤左表,但绝不会把右表的任何列加入到最终结果中。
核心特点:
- 结果集只包含左表的列。
- 右表只用于过滤,其
ON条件中出现的键如果在右表中存在,则左表的对应行被保留。 - 因为
left semi join是in(keySet)的关系,遇到右表重复记录,左表会跳过,而join则会一直遍历。这就导致右表有重复值的情况下left semi join只产生一条,join会产生多条,也会导致left semi join的性能更高。 - 右表的列只能在
ON子句中引用,不能出现在SELECT或WHERE子句中。
案例:查询所有有对应用户信息的订单(但不需要用户信息)
使用 LEFT SEMI JOIN (推荐):
SELECT
t1.order_id,
t1.user_id,
t1.product
FROM ds_hive.ch6_t_order t1
LEFT SEMI JOIN ds_hive.ch6_t_user t2
ON t1.user_id = t2.user_id;
等价的 IN 子查询 (效率较低):
SELECT
t1.order_id,
t1.user_id,
t1.product
FROM ds_hive.ch6_t_order t1
WHERE t1.user_id IN (SELECT user_id FROM ds_hive.ch6_t_user);
两个查询的结果相同,都是 user_id 为 1 和 3 的订单记录,但 LEFT SEMI JOIN 的执行效率通常更高。
其他相关操作
5. 多表连接
Hive 支持连接两个以上的表。连接 n 个表,至少需要 n-1 个 JOIN 条件。
案例:查询订单、用户及商品信息
(假设存在一张商品表 ds_hive.ch6_t_goods,且订单表中有 product_id)
SELECT
t1.order_id,
t2.user_name,
t3.product_name,
t3.price
FROM ds_hive.ch6_t_order t1
JOIN ds_hive.ch6_t_user t2
ON t1.user_id = t2.user_id
JOIN ds_hive.ch6_t_goods t3
ON t1.product_id = t3.product_id;
6. 数据合并 (UNION & UNION ALL)
UNION 与 JOIN 不同,它不是水平连接,而是垂直(上下)拼接两个查询的结果集。
UNION ALL:直接拼接,不去重,效率高。UNION:拼接后会进行去重,效率较低。
使用要求:
- 两个查询结果的列数必须相同。
- 两个查询结果对应列的数据类型必须兼容。
案例:合并订单表和用户表中的所有用户 ID
-- 不去重
SELECT user_id FROM ds_hive.ch6_t_order
UNION ALL
SELECT user_id FROM ds_hive.ch6_t_user;
-- 去重
SELECT user_id FROM ds_hive.ch6_t_order
UNION
SELECT user_id FROM ds_hive.ch6_t_user;
重要注意事项
7. 避免笛卡尔积 (Cartesian Product)
笛卡尔积是一种需要极力避免的错误用法。它会在以下情况产生:
- 省略
JOIN的ON连接条件。 - 连接条件无效,例如
ON 1=1。
这会导致左表的每一行与右表的每一行都进行连接,生成的结果行数是 m * n(m 和 n 分别是两表的行数),可能导致计算资源耗尽。
案例(错误示范):
SELECT t1.order_id, t2.user_name
FROM ds_hive.ch6_t_order t1
JOIN ds_hive.ch6_t_user t2; -- 缺少 ON 条件
为了防止这类危险操作,可以开启 Hive 的严格模式:
set hive.mapred.mode=strict;
严格模式会禁止执行可能产生笛卡尔积的查询、对分区表查询不加分区限制等不安全操作。
8. 理解 Join 导致的数据放大
与笛卡尔积(错误)不同,数据放大是 JOIN 的一种正常但需注意的现象。当连接键不唯一时,就会发生数据放大。
-
一对多 (One-to-Many):如果一个用户有多笔订单,在
user表和order表连接时,该用户的记录会被复制多次,与每一笔订单匹配。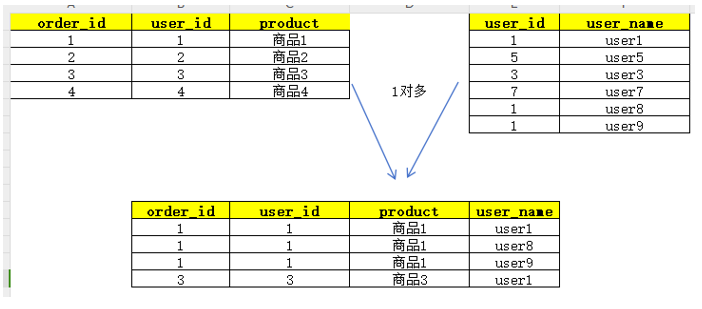
-
多对多 (Many-to-Many):如果连接的两张表的连接键都存在重复,数据会呈指数级增长。
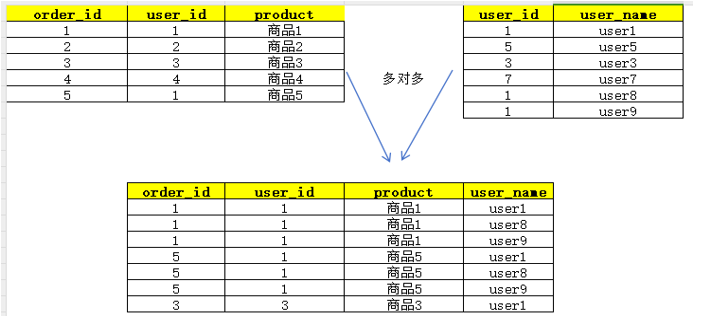
务必注意:在 JOIN 后进行聚合计算(如 COUNT, SUM)时,要警惕数据放大导致的计算错误。通常需要先对数据进行去重或预聚合。
举例说明
假设我们有两张表:一张订单表 (orders) 和一张订单商品详情表 (order_items)。
- 一个订单(orders)可以包含多个商品(order_items)。这是一个典型的“一对多”关系。
表结构和数据
1. 订单表: orders
(记录了每个订单的总金额)
| order_id | user_id | order_amount |
|---|---|---|
| 101 | u01 | 150.00 |
| 102 | u02 | 200.00 |
2. 订单商品详情表: order_items
(记录了每个订单里具体有哪些商品)
| item_id | order_id | product_name |
|---|---|---|
| 1 | 101 | '牛奶' |
| 2 | 101 | '面包' |
| 3 | 102 | '咖啡' |
我们的目标
我们想计算 每个用户的总订单金额。
从 orders 表可以很直观地看出:
- 用户
u01的总订单金额是150.00。 - 用户
u02的总订单金额是200.00。
这是我们期望得到的正确结果。
错误的计算方式(直接 JOIN 后聚合)
一个初学者可能会想:我需要用户信息和商品信息,所以我先把两张表 JOIN 起来,然后再按用户ID分组计算总金额。
SELECT
o.user_id,
SUM(o.order_amount) AS total_amount -- 对订单金额求和
FROM
orders o
JOIN
order_items oi ON o.order_id = oi.order_id
GROUP BY
o.user_id;
让我们看看这个查询的执行过程:
第一步:JOIN 操作
JOIN 会根据 order_id 将两张表连接起来。
orders表中的order_id = 101在order_items表中匹配到了 2 条记录。orders表中的order_id = 102在order_items表中匹配到了 1 条记录。
JOIN 后的中间结果如下:
| o.order_id | o.user_id | o.order_amount | oi.item_id | oi.product_name |
|---|---|---|---|---|
| 101 | u01 | 150.00 | 1 | '牛奶' |
| 101 | u01 | 150.00 | 2 | '面包' |
| 102 | u02 | 200.00 | 3 | '咖啡' |
这就是“数据放大”! 注意看 o.order_amount 列,150.00 这个值出现了两次,因为它所属的订单 101 有两个商品。orders 表中 user_id = u01 的那一行被复制了。
第二步:GROUP BY 和 SUM 聚合
现在,查询会对这个放大了的中间结果进行聚合。
- 对于
user_id = u01:SUM(o.order_amount)=150.00 + 150.00=300.00(错误!) - 对于
user_id = u02:SUM(o.order_amount)=200.00=200.00(因为只匹配到一条,所以结果碰巧是正确的)
最终的错误结果:
| user_id | total_amount |
|---|---|
| u01 | 300.00 |
| u02 | 200.00 |
用户 u01 的总金额被错误地计算为 300,而正确值应该是 150。
正确的计算方式:预聚合
为了避免数据放大带来的计算错误,我们需要遵循“先聚合,再关联”的原则。
在 JOIN 之前,先在各自的表中进行聚合,将数据处理成相同的粒度(比如,用户粒度),然后再将聚合后的结果关联起来。
如果我们想计算每个用户的总订单金额和购买的商品总数,可以这样做:
-- 使用 WITH 子句 (CTE) 使逻辑更清晰
WITH user_total_amount AS (
-- 步骤1: 先计算每个用户的总订单金额
-- 这一步只在 orders 表操作,没有数据放大的问题
SELECT
user_id,
SUM(order_amount) AS total_amount
FROM
orders
GROUP BY
user_id
),
user_item_count AS (
-- 步骤2: 计算每个用户购买的商品数量
-- 这一步需要 JOIN,但我们只对 item 计数,不涉及 order_amount
SELECT
o.user_id,
COUNT(oi.item_id) AS item_count
FROM
orders o
JOIN
order_items oi ON o.order_id = oi.order_id
GROUP BY
o.user_id
)
-- 步骤3: 将两个预聚合好的结果,按 user_id 关联起来
SELECT
uta.user_id,
uta.total_amount,
uic.item_count
FROM
user_total_amount uta
JOIN
user_item_count uic ON uta.user_id = uic.user_id;
这个查询的正确结果:
| user_id | total_amount | item_count |
|---|---|---|
| u01 | 150.00 | 2 |
| u02 | 200.00 | 1 |
总结
下表总结了各种 JOIN 类型的核心用途,帮助你快速选择合适的工具。
| Join 类型 | 核心用途 | 关键点 |
|---|---|---|
| INNER JOIN | 获取两个表的交集数据。 | 只保留能完全匹配的行。 |
| LEFT JOIN | 以左表为基准,补充右表信息。 | 保留所有左表行,右表不匹配处为 NULL。 |
| RIGHT JOIN | 以右表为基准,补充左表信息。 | 保留所有右表行,左表不匹配处为 NULL。 |
| FULL OUTER JOIN | 获取两个表的并集数据。 | 保留所有行,不匹配处用 NULL 填充。 |
| LEFT SEMI JOIN | 高效判断“是否存在”,用于过滤左表。 | 相当于 IN 子查询,不返回右表列,不数据放大。 |
| Anti-Join 模式 | 查找一个表有,另一个表没有的差异数据。 | LEFT JOIN + WHERE key IS NULL。 |
| UNION ALL / UNION | 垂直合并两个结果集。 | UNION ALL 不去重,UNION 去重。 |
Join底层原理
Hive Join优化的核心思想是 “尽可能避免或减少Shuffle”。为了实现这一目标,Hive提供了多种Join算法。本文将深入剖析Hive中最经典的四种Join算法:从最基础的 Common Join 开始,了解其工作原理和性能瓶颈;然后学习如何通过 Map Join 彻底消除Shuffle;最后探索在特定场景下处理大表对大表的利器——Bucket Map Join 和 Sort Merge Bucket (SMB) Join。
1. Common Join (Reduce Side Join): 万物的基础
Common Join 是Hive中最基础、最稳定的Join算法。如果不指定MapJoin或者不满足MapJoin的条件,Hive解析器默认会将Join操作转换为Common Join。它通过一个完整的MapReduce Job来完成,核心的Join逻辑发生在Reduce阶段。
1.1 工作原理
整个过程包含Map、Shuffle、Reduce三个阶段。
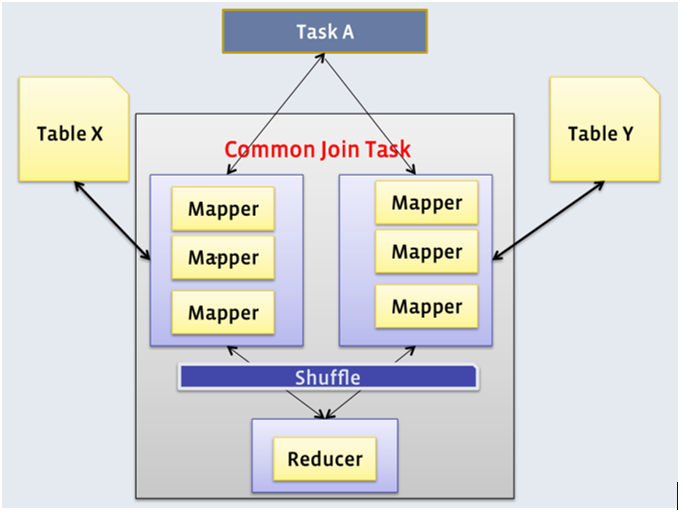
Map阶段
- Step1: 读取源表的数据,Map输出时以 Join on条件中的列为key。如果Join有多个关联键,则以这些关联键的组合作为key。
- Step2: Map输出的value为Join之后所关心的列(
SELECT或WHERE中需要用到的);同时在value中还会包含一个表的Tag信息,用于在Reduce阶段标明此value来自哪个表。 - Step3: 按照key进行分区和排序,为Shuffle做准备。
Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的Reduce Task中,这样可以确保两个表中拥有相同key的数据会到达同一个Reduce Task。
Reduce阶段
Reduce Task根据key的值完成最终的Join操作。在此期间,通过value中的Tag信息来识别来自不同表的数据,然后进行合并。
1.2 性能瓶颈
Common Join虽然通用且稳定,但其性能瓶颈也非常明显,主要源于其对Shuffle的重度依赖:
- 性能开销: JOIN操作涉及将分布在�不同节点上的数据进行合并。在MapReduce模型中,这意味着需要进行数据的分发、排序和聚合,这些操作都会带来较大的性能开销。
- Shuffle开销: Shuffle阶段是Common Join中最昂贵的部分,涉及大量的网络I/O和磁盘I/O。当数据量巨大或数据分布不均(数据倾斜)时,Shuffle会成为严重的性能瓶颈。
- 内存消耗: Reduce阶段需要缓存来自多个表的数据来进行Join,当某个key的数据量特别大时,可能导致内存不足的问题,影响性能。
- 复杂度: 涉及完整的MapReduce流程,增加了查询的复杂性和执行时间。
1.3 示例
SELECT t1.stu_id
,t1.score
,t2.sex
from ds_hive.ch7_score_info t1
join ds_hive.ch7_stu_info t2
on t1.stu_id=t2.stu_id
;
其执行过程示意图如下:
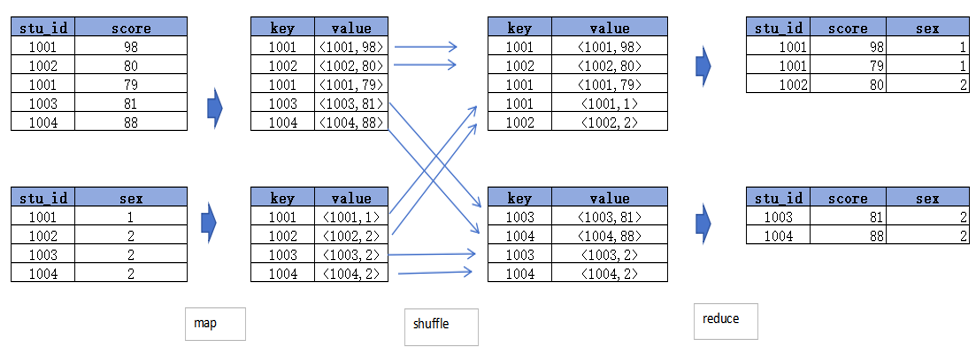
小结:Common Join的瓶颈在于Shuffle。那么,有没有办法绕过昂贵的Shuffle和Reduce阶段呢?答案就是Map Join。
2. Map Join: 避免Shuffle的利器
Map Join 是一种高效的Join算法,其核心适用场景为“大表Join小表”。它通过将小表数据完全加载到内存中,在Map阶段直接完成Join,从而彻底避免了Shuffle和Reduce阶段,极大提升了查询性能。
2.1 核心思想与工作原理
Map Join通过两个Job完成。
- 第一个Job (Local Task):读取小表的数据,将其制作成一个内存中的哈希表(Hash Table),然后将这个哈希表文件上传至Hadoop分布式缓存(Distributed Cache)(本质上是上传至每个执行任务的NodeManager节点本地磁盘)。
- 第二个Job (MapReduce Task):启动一个只有Map阶段的作业。每个Map Task在启动时,会从分布式缓存中读取小表的哈希表文件,并将其加载到自己的内存中。接着,Map Task扫描大表的数据,每读取一行,就用Join Key去内存中的哈希表查找匹配项,匹配成功则直接输出结果。
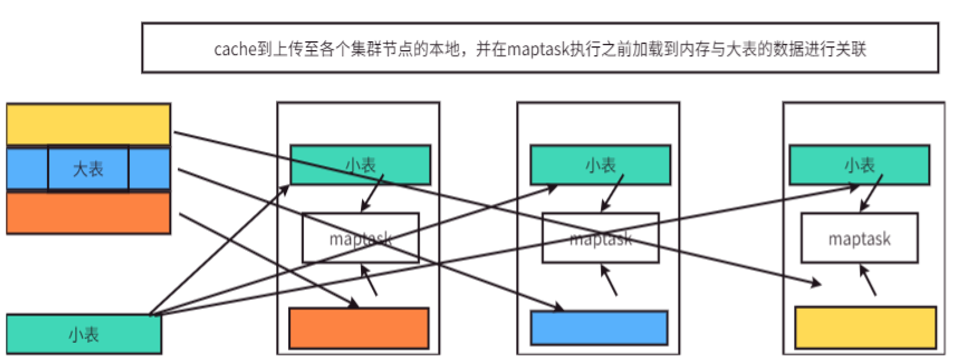
2.2 触发方式
Map Join有两种触发方式:通过Hint提示手动指定,或由Hive优化器自动触发。
1) Hint提示 (已过时)
用户可以在SQL语句中通过/*+ mapjoin(table_name) */的语法,强制指定某张表为小表,使用Map Join。这种方式已经不推荐使用。
select /*+ mapjoin(ta) */
ta.id,
tb.id
from table_a ta
join table_b tb
on ta.id=tb.id
;
2) 自动触发 (推荐)
这是目前最常用、最智能的方式。Hive优化器在编译SQL时,会根据表的大小自动判断是否可以将一个Common Join转换为Map Join。
大致转换逻辑: 当Hive看到一个Join查询时,它首先会制定一个保底的、通用的执行方案,也就是Common Join。但在真正执行之前,Hive会进入一个“智能优化”环节。在这个环节里,它会检查参与Join的所有表的大小。如果发现这些表中,除了一个大表外,其余所有表的体积加起来都特别小(比如小于25MB),Hive就认为这是一个“一大带多小”的理想场景。于是,它就会放弃原来的通用方案,转而生成一个更高效的Map Join方案来执行。
有时候,Hive在分析SQL语句时,会遇到一些“未知数”,比如一个子查询的结果。在SQL运行之前,Hive无法预测这个子查询会产生一个大表还是小表。面对这种不确定性,Hive不会只押宝在一个方案上。它会创建一个“条件任务(Conditional Task)”,相当于准备了A、B两套计划:计划A是为“小表”情况准备的高效Map Join��方案,计划B是为“大表”情况准备的稳妥Common Join方案。等到SQL真正开始运行时,Hive会先计算出那个子查询的实际大小,然后根据这个大小临场做出最佳选择,决定到底执行A计划还是B计划。
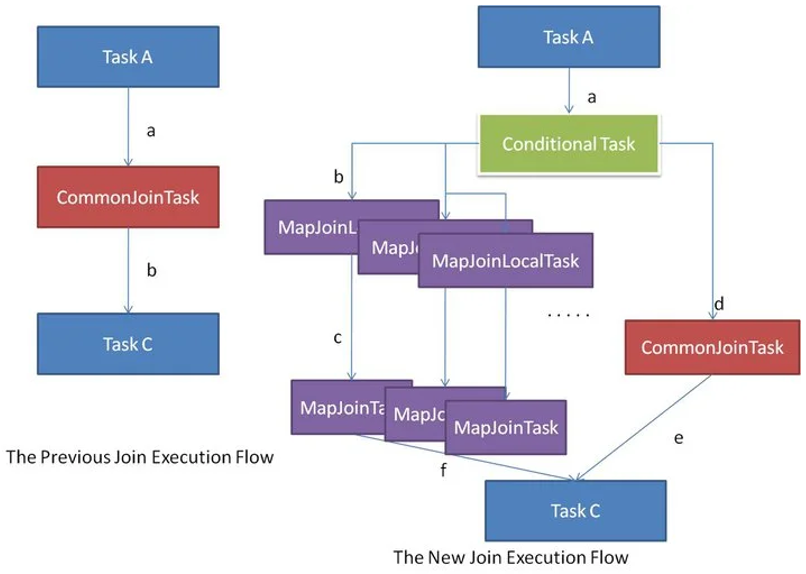
Map Join自动转换的判断逻辑细节如下图所示:
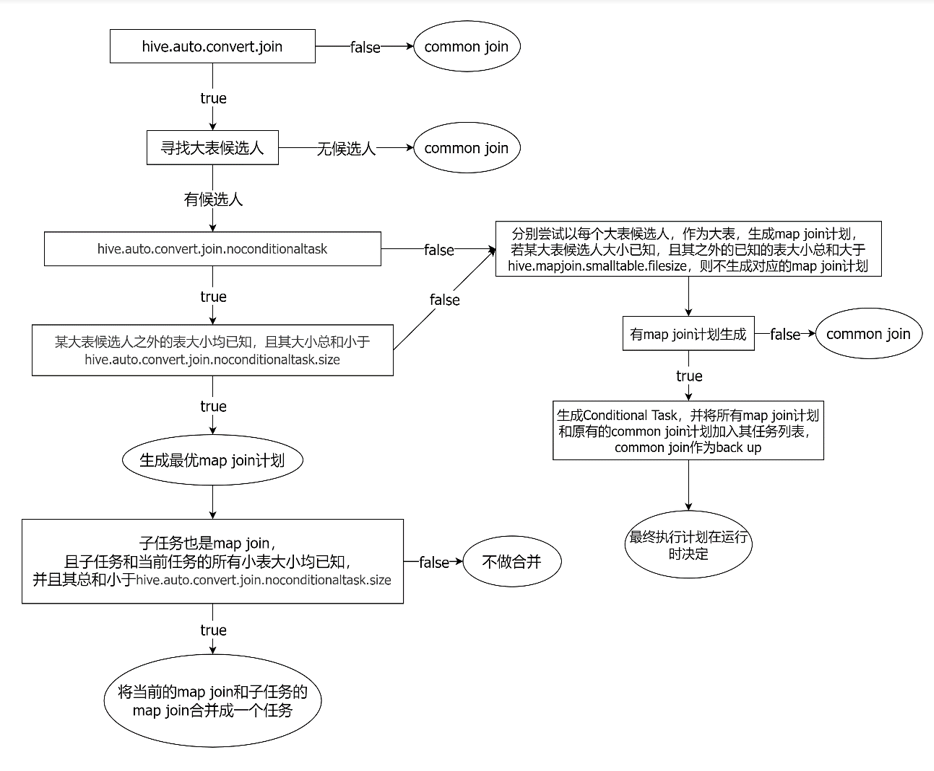
相关核心参数:
-
set hive.auto.convert.join=true;-- 开启Map Join自动转换功能(默认即为true)。 -
set hive.mapjoin.smalltable.filesize=25000000;-- 定义了多大的表可以被打包成“小表组合”(默认25MB)。当Hive分析一个多表Join时,它会找出所有可能的“一个大表 + 多个小表”的组合。 如果找到了多种符合条件的组合,Hive会为每一种都创建一个高效的Map Join执行计划。不仅如此,为了确保任务万无一失,它还会保留一个最基础的Common Join计划作为“备用轮胎”。在实际运行时,Hive会优先尝试使用最高效的Map Join计划。如果这个计划因为内存不足等原因意外失败,系统不会崩溃,而是会自动切换到那个“备用轮胎”(Common Join计划),确保任务最终能够跑完。 -
set hive.auto.convert.join.noconditionaltask=true;-- 默认为false。设为true后,会开启更激进的无条件转换模式。 -
set hive.auto.convert.join.noconditionaltask.size=10000000;-- 在无条件转换模式下的小表阈��值(默认为10MB)。如果n-1张表的总大小小于此值,Hive会直接生成一个最优的Map Join计划,不再保留Common Join作为备用计划。
2.3 示例与性能对比
示例SQL 1:观察执行计划
我们通过EXPLAIN来观察开启Map Join前后的执行计划变化。
优化前 (关闭自动转换):
set hive.auto.convert.join=false;
explain
SELECT t1.stu_id, t1.score, t2.sex
FROM ds_hive.ch7_score_info t1
JOIN ds_hive.ch7_stu_info t2 ON t1.stu_id = t2.stu_id;
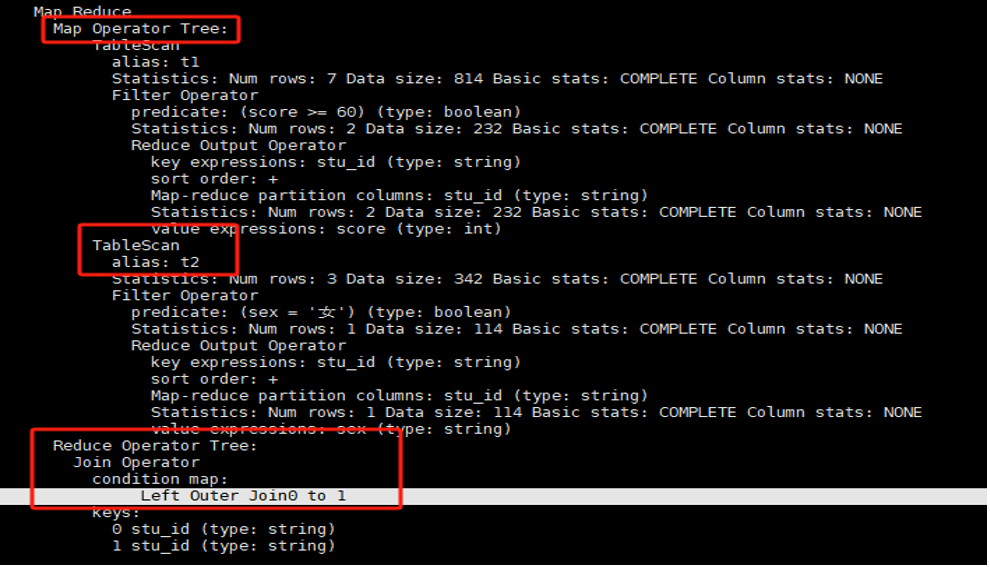 可以看到,执行计划中有Map和Reduce两个阶段 (Stage-1, Stage-2)。
可以看到,执行计划中有Map和Reduce两个阶段 (Stage-1, Stage-2)。
优化后 (开启自动转换):
set hive.auto.convert.join=true;
explain
SELECT t1.stu_id, t1.score, t2.sex
FROM ds_hive.ch7_score_info t1
LEFT JOIN ds_hive.ch7_stu_info t2 ON t1.stu_id = t2.stu_id;
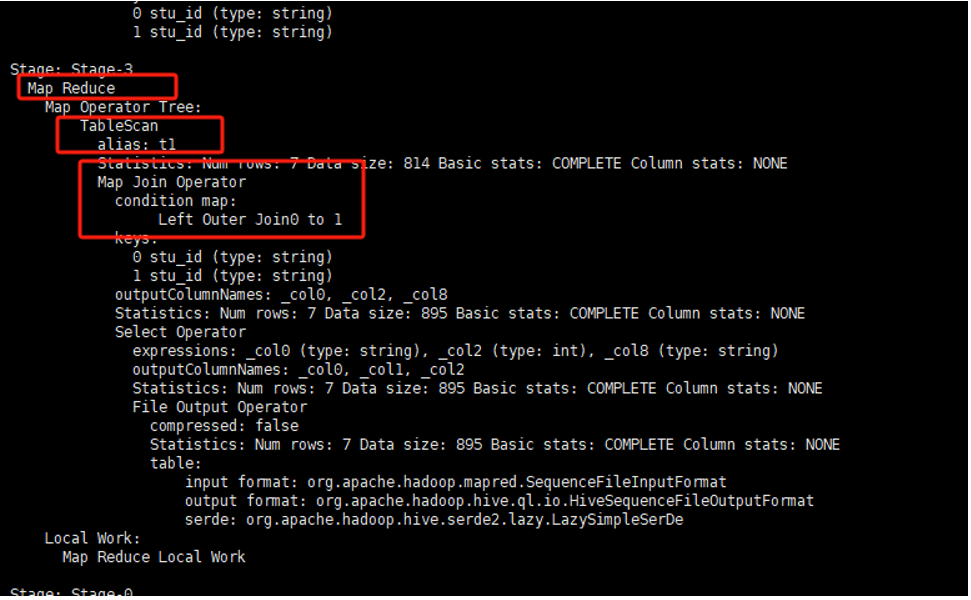 可以看到,执行计划中出现了 Map Join Operator,并且整个过程只有一个Stage,没有Reduce阶段,证明Map Join优化已生效。
可以看到,执行计划中出现了 Map Join Operator,并且整个过程只有一个Stage,没有Reduce阶段,证明Map Join优化已生效。
示例SQL 2:对比执行时间
在小数据量下性能差异�不明显,我们使用大数据量的表来测试。
-- 先关闭mapjoin执行
set hive.auto.convert.join=false;
SELECT t1.province_id, count(*) as cnt
FROM ds_hive.ch12_order_detail_orc t1
JOIN ds_hive.ch12_product_info_orc t3 ON t1.province_id=t3.id
GROUP BY t1.province_id;
-- 再打开mapjoin执行
set hive.auto.convert.join=true;
SELECT t1.province_id, count(*) as cnt
FROM ds_hive.ch12_order_detail_orc t1
JOIN ds_hive.ch12_product_info_orc t3 ON t1.province_id=t3.id
GROUP BY t1.province_id;
在大数据量下,两者的运行时间差距可达近100秒,Map Join的性能优势尽显。
小结:Map Join完美解决了“一大一小”的场景,但如果两张都是无法加载进内存的大表呢?这时就需要基于“分桶”思想的Bucket Map Join。
3. Bucket Map Join: “大表对大表”的初次尝试
Bucket Map Join 是对Map Join的一种改进,它打破了Map Join只能用于“大表Join小表”的限制,可用于两张大表之间的Join。但它的使用条件非常苛刻,在实际生产中用得较少,因为维护分桶表的成本较高。
3.1 核心思想
其核心思想是:如果参与Join的两张表都是分桶表,并且满足特定条件,那么就可以将大表的Join拆解成小单元的Join。具体来说,Hive可以明确知道一张表的某个Bucket只会和另一张表的特定几个Bucket关联,因此在Map端,一个Task不再需要加载另一张表的全部数据,而只需加载其关联的Bucket数据即可。这大大降低了Map端的内存压力。
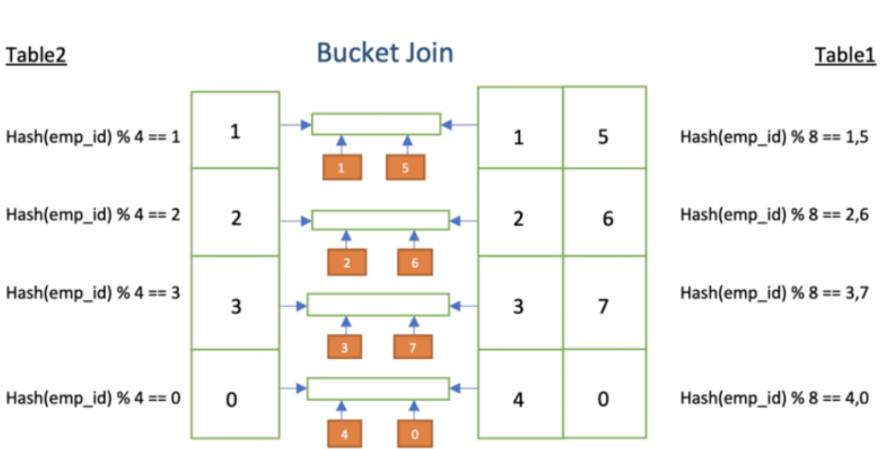
3.2 使用前提与配置
Bucket Map Join不支持自动转换,必须满足以下所有条件:
- 两张表都是分桶表。
ON的关联字段 必须是 两张表的分桶字段。- 其中一张表的分桶数必须是另一张表分桶数的整数倍。
- 必须开启相关优化参数,并使用Hint提示。
相关参数与Hint:
-- 关闭CBO优化,CBO可能会导致Hint信息被忽略
set hive.cbo.enable=false;
-- Map Join Hint默认会被忽略,需设置为false
set hive.ignore.mapjoin.hint=false;
-- 启用Bucket Map Join优化功能
set hive.optimize.bucketmapjoin = true;
SQL Hint:
select /*+ mapjoin(table_name) */ ...
3.3 示例SQL
1. 数据准备:创建分桶表
创建两个分桶表,注意分桶字段为id,且分桶数成倍数关系(18是9的2倍)。
CREATE TABLE if not exists ds_hive.ch12_order_detail_bucket(
`id` string, `user_id` string, `product_id` string, `province_id` string,
`create_time` string, `product_num` int, `total_amount` decimal(16,2)
)
comment '订单详情分桶表'
clustered by (id) into 18 buckets;
INSERT OVERWRITE TABLE ds_hive.ch12_order_detail_bucket
select * from ds_hive.ch10_order_detail_txtfile;
CREATE TABLE if not exists ds_hive.ch12_order_detail_bucket_sm(
`id` string, `user_id` string, `product_id` string, `province_id` string, `create_time` string
)
comment '订单详情分桶表(小)'
clustered by (id) into 9 buckets;
INSERT OVERWRITE TABLE ds_hive.ch12_order_detail_bucket_sm
select id, user_id, product_id, province_id, create_time
from ds_hive.ch10_order_detail_txtfile limit 3000000;
2. 执行查询 设置参数并编写带Hint的SQL。
set hive.cbo.enable=false;
set hive.ignore.mapjoin.hint=false;
set hive.optimize.bucketmapjoin=true;
explain extended
select /*+ mapjoin(t1) */
*
from ds_hive.ch12_order_detail_bucket t1
join ds_hive.ch12_order_detail_bucket_sm t2
on t1.id=t2.id
;
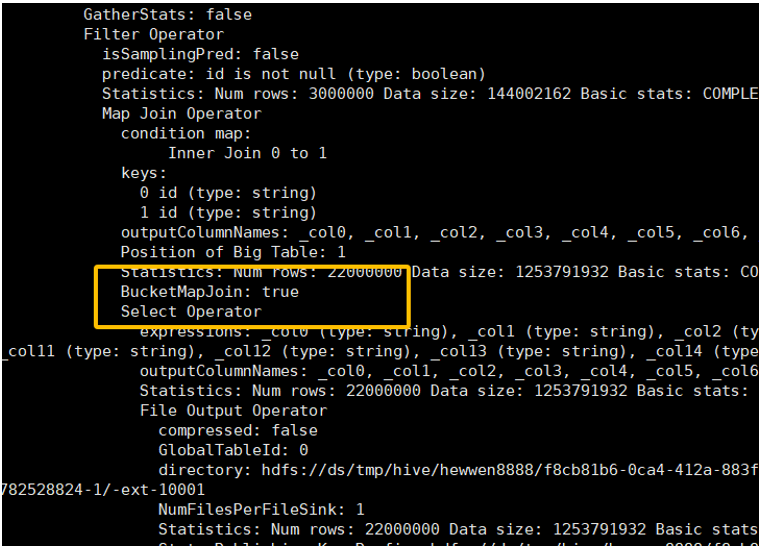
要确认是否成功使用了Bucket Map Join,需要查看详细的执行计划 (explain extended)。如果在Map Join Operator中看到 “BucketMapJoin: true”,则表明优化成功。
4. Sort Merge Bucket (SMB) Join: Bucket Join的终极形态
Sort Merge Bucket (SMB) Join 是在Bucket Map Join基础上的进一步优化,同样用于处理两个大表的Join,且使用场景更为有限。
4.1 核心思想
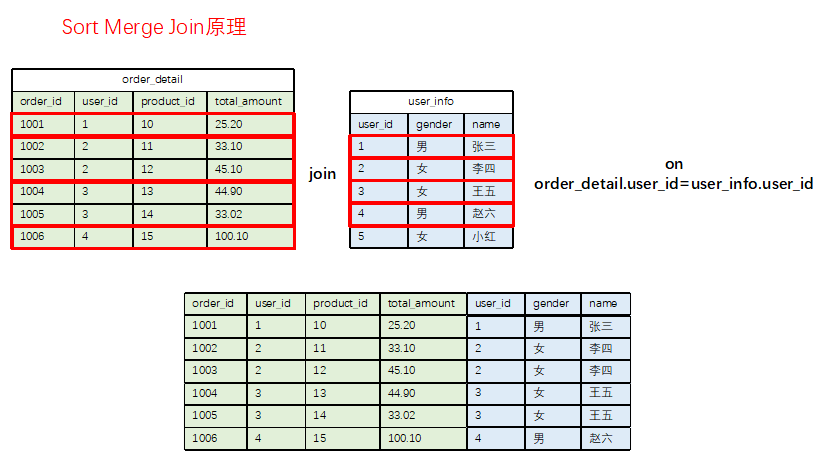
SMB Join要求参与Join的表不仅是分桶的,而且桶内数据必须是按Join Key有序的。
- Bucket Map Join 在两个Bucket之间进行Join时,采用的是Hash Join算法(将一个Bucket加载到内存哈希表中,扫描另一个Bucket)。
- SMB Join 在两个Bucket之间进行Join时,采用的是Sort Merge Join算法。由于两个Bucket内部都已有序,它可以像拉链一样,用两个指针同步扫描两个Bucket,逐行进行匹配和Join,无需将任何一个Bucket完整加载到内存中。这使得SMB Join对内存的消耗极低。
Sort Merge Join算法原理示意图:
4.2 使用前提与配置
SMB Join的条件比Bucket Map Join更苛刻:
- 两张表都是分桶表,且桶内已排序 (
SORTED BY)。 ON的关联字段 == 分桶字段 == 排序字段。(这三者为相同字段)- 其中一张表的分桶数是另一张表分桶数的整数倍。
- 开启相关优化参数。
相关参数:
-- 开启SMB Join自动转换
set hive.auto.convert.sortmerge.join=true;
-- 启用SMB Join优化
set hive.optimize.bucketmapjoin.sortedmerge = true;
-- (依赖于Bucket Map Join)
set hive.optimize.bucketmapjoin = true;
4.3 示例SQL
1. 数据准备:创建有序分桶表
创建表时使用 CLUSTERED BY (id) SORTED BY (id) INTO ... BUCKETS。
CREATE TABLE if not exists ds_hive.ch12_order_detail_bucket_sort(
`id` string, `user_id` string, `product_id` string, `province_id` string,
`create_time` string, `product_num` int, `total_amount` decimal(16,2)
)
comment '订单详情有序分桶表'
clustered by (id) sorted by(id) into 20 buckets;
INSERT OVERWRITE TABLE ds_hive.ch12_order_detail_bucket_sort
select * from ds_hive.ch10_order_detail_txtfile;
CREATE TABLE if not exists ds_hive.ch12_order_detail_bucket_sm_sort(
`ids` string, `user_id` string, `product_id` string, `province_id` string, `create_time` string
)
comment '订单详情有序分桶表(小)'
clustered by (ids) sorted by(ids) into 10 buckets;
INSERT OVERWRITE TABLE ds_hive.ch12_order_detail_bucket_sm_sort
select id, user_id, product_id, province_id, create_time
from ds_hive.ch10_order_detail_txtfile limit 3000000;
2. 执行查询 设置参数并执行查询。SMB Join可以被自动识别,无需Hint。
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.optimize.bucketmapjoin = true;
explain
select
t1.user_id
from ds_hive.ch12_order_detail_bucket_sort t1
join ds_hive.ch12_order_detail_bucket_sm_sort t2
on t1.id=t2.ids;
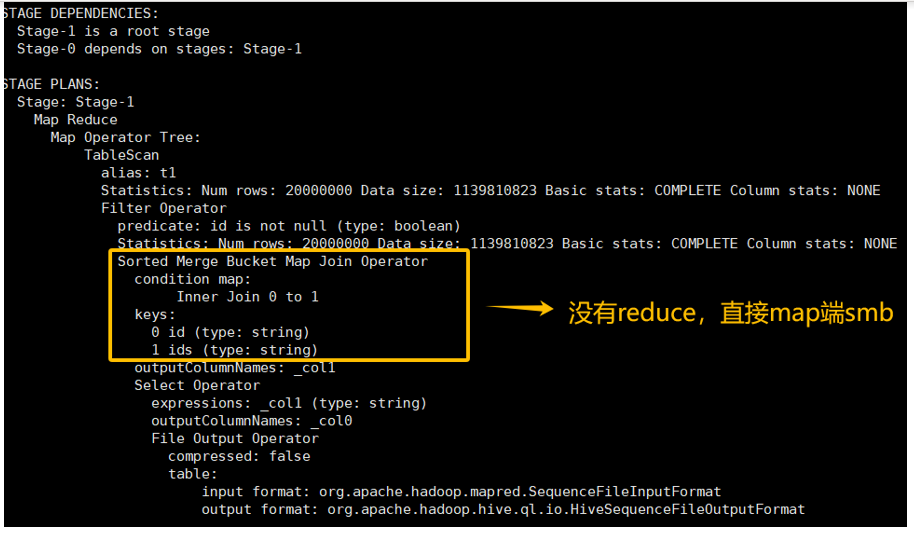
优化后的执行计划中会看到 Sort-Merge Join Operator。
性能对比:
select
t1.province_id,count(*)
from ds_hive.ch12_order_detail_bucket_sort t1
join ds_hive.ch12_order_detail_bucket_sm_sort t2
on t1.id=t2.ids
group by t1.province_id
;
实验表明,未启动SMB Join时查询耗时60多秒,启动后则缩短至20多秒,性能提升显著。
总结与技术选型
为了方便理解和选择,我们将四种Join算法的核心特点总结如下:
| Join类型 | 核心思想 | 适用场景 | 优点 | 缺点/限制 |
|---|---|---|---|---|
| Common Join | Map-Shuffle-Reduce | 通用,任何场景 | 稳定,无数据结构限制 | 性能差,Shuffle开销大,易数据倾斜 |
| Map Join | 小表广播,Map端内存Join | 一大一小 | 性能极高,无Shuffle | 小表大小受内存限制 |
| Bucket Map Join | 分桶Join,桶间Hash Join | 两大表,且已分桶 | 降低Map端内存压力 | 表结构要求苛刻,维护成本高 |
| SMB Join | 分桶Join,桶间Sort-Merge Join | 两大表,且已分桶并有序 | 内存消耗极低 | 表结构要求最苛刻,使用场景极少 |
技术选型建议
在实际工作中,可以遵循以下决策路径:
- 首选Map Join:评估你的Join场景,只要满足“一大一小”的条件(小表大小在
hive.mapjoin.smalltable.filesize阈值内),就应该毫不犹豫地让Hive自动转换为Map Join。这是最常用、最有效的优化手段。 - 默认使用Common Join:如果参与Join的表都很大,无法使用Map Join,那么默认的Common Join就是你的选择。此时,优化的重点应转向解决Common Join中可能出现的数据倾斜问题。
- 谨慎考虑Bucket类Join:只有当数据仓库的ETL流程已经规划并维护了分桶表和有序分桶表时,才考虑使用Bucket Map Join或SMB Join。不要为了一个临时的Join查询而去特意创建分桶表,其维护成本通常得不偿失。