HQL语法优化 ⭐️⭐️⭐️
重点掌握 ⭐️⭐️⭐️
列裁剪与分区裁剪
在生产环境中,当表中的列非常多或数据量巨大时,select * 全列扫描或不指定分区的全表扫描会导致查询效率极低。Hive 在这方面提供了两个基础且至关重要的优化机制:列裁剪和分区裁剪。
-
列裁剪 (Column Pruning):这是最直接的优化方式。在读取数据时,Hive 只会扫描查询中明确指定的列,而忽略所有其他列。这极大地减少了磁盘 I/O 开销、中间表存储开销和网络数据传输量。
-- 不推荐:读取所有列,即使你只需要两列SELECT * FROM sales WHERE dt = '2025-10-20';-- 推荐:只读取需要的列,大幅减少I/OSELECT product_id, amount FROM sales WHERE dt = '2025-10-20'; -
分区裁剪 (Partition Pruning):当表被分区后(例如按日期
dt分区),如果在WHERE子句中指定了分区过滤条件,Hive 会只扫描符合条件的特定分区目录下的数据,而完全跳过其他分区。这是 Hive 查询性能优化的第一道防线,效果立竿见影。-- sales 表以 dt (日期) 为分区键-- 不推荐:全表扫描,当数据量大时可能是灾难性的SELECT product_id, amount FROM sales WHERE year(order_date) = 2025;-- 推荐:明确指定分区键,Hive 只会扫描 '2025-10-20' 这个分区SELECT product_id, amount FROM sales WHERE dt = '2025-10-20';
核心原则:尽量少地读入数据,尽早地收敛数据!
提前数据收敛
在复杂的查询,尤其是包含子查询和 JOIN 的场景中,应尽可能早地过滤掉不需要的数据。如果一个过滤条件可以下推到子查询中,就不要留到主查询中处理。
-- 优化前
-- 问题:先将两个分区的大量数据进行 JOIN,然后再对 JOIN 后的结果进行过滤,
-- 导致 JOIN 阶段处理的数据量过大,Shuffle 开销高。
select
a.字段a, a.字段b, b.字段a, b.字段b
from
(
select 字段a, 字段b
from table_a
where dt = date_sub(current_date, 1)
) a
left join
(
select 字段a, 字段b
from table_b
where dt = date_sub(current_date, 1)
) b
on a.字段a = b.字段a
where a.字段b <> ''
and b.字段b <> 'xxx'
;
-- 优化后(数据收敛)
-- 优化:在子查询阶段就应用过滤条件,使得参与 JOIN 的数据量大幅减少,
-- 从而降低了网络 Shuffle 开销和内存压力,显著提升查询性能。
select
a.字段a, a.字段b, b.字段a, b.字段b
from
(
select 字段a, 字段b
from table_a
where dt = date_sub(current_date, 1)
and 字段b <> '' -- 过滤条件提前
) a
left join
(
select 字段a, 字段b
from table_b
where dt = date_sub(current_date, 1)
and 字段b <> 'xxx' -- 过滤条件提前
) b
on a.字段a = b.字段a
;
HQL语法优化之聚合优化
Map端聚合
在标准的 GROUP BY 聚合操作中,Map 任务仅负责读取数据并按分组键进行分区,然后通过 Shuffle 将数据发送到 Reduce 任务,最终在 Reduce 端完成聚合。当分组后的数据量依然很大时,Shuffle 会成为性能瓶颈。
Hive 提供了 Map 端聚合(map-side aggregation)的优化。通过开启此功能,Hive 会在 Map 任务阶段先进行一次预聚合,对本地数据进行初步的合并计算。这样一来,Shuffle 到 Reduce 端的数据量会大幅减少,从而提高整体运算效率。
1) 开启Map端聚合
-- 开启 Map 端预聚合功能
set hive.map.aggr=true;
-- 查看执行计划,会发现在 Map Stage 中出现了 GROUPBY 操作
explain
select t1.province_id, count(*) as cnt
from ds_hive.ch12_order_detail_orc t1
group by t1.province_id
;
具体原理参考: 聚合原理及优化思路
group by 代替 distinct
COUNT(DISTINCT column) 是一个常见的去重计数场景,但在 Hive 中性能较差。原因是它通常会将所有数据汇集到一个 Reducer 中进行去重和计数,当数据量大或存在数据倾斜时,这个单一的 Reducer 会成为严重的性能瓶颈。
为了解决这个问题,我们可以使用 GROUP BY 将其改写为两阶段聚合,从而利用 MapReduce 的分布式能力来并行去重。
实例说明 distinct 的问题:
-- 此查询可能因单一 Reducer 压力过大而运行缓慢或失败
select count(distinct province_id) from ds_hive.ch12_order_detail_orc ;
优化方案:
-- 优化后:分为两步
-- 1. 内层查询:使用 GROUP BY 在多个 Reducer 上并行计算出所有不重复的 province_id。
-- 2. 外层查询:对上一步产生的小得多的结果集进行一次简单的 COUNT,这个过程非常快。
select count(province_id)
from (
select province_id
from ds_hive.ch12_order_detail_orc
group by province_id
) t
;
这种 SUM + GROUP BY 或 COUNT + GROUP BY 的方案,将单一 Reducer 的压力分散到多个 Reducer,有效解决了数据倾斜和性能瓶颈问题。
HQL语法优化之Join优化
-
利用 Map Join 特性 当一个大表和一个或多个小表进行
JOIN时,应优先使用 Map Join。Hive 会将小表的数据完全加载到内存中,并分发到各个 Map 任务节点。这样,大表的每个分片在 Map 阶段就可以直接与内存中的小表数据进行JOIN,完全省去了 Reduce 阶段和昂贵的数据 Shuffle 过程,效率极高。-- 开启自动 Map Join 转换set hive.auto.convert.join=true;-- 设置小表的大小阈值 (默认为 25MB)set hive.mapjoin.smalltable.filesize=25000000;-- 或者使用 hint 手动指定SELECT /*+ MAPJOIN(small_table) */ a.id, b.nameFROM large_table aJOIN small_table b ON a.id = b.id; -
分桶表 Map Join 如果
JOIN的两个表都是分桶表,并且JOIN的 key 和分桶的 key 是同一个字段,Hive 可以进行更高效的JOIN。它只需要将一个表的桶文件与另一个表对应的桶文件进行JOIN,避免了全表数据的笛卡尔积比较,大大提高了效率。 -
多表 Join 时将 key 相同的写在一起 当一个查询需要
JOIN多个表,且其中一些表的JOINkey 相同时,应该将它们连续写在一起。这样 Hive 优化器更有可能将这些JOIN合并成一个 MapReduce 作业,而不是为每个JOIN单独启动一个作业,从而减少了 I/O 和计算开销。如果JOIN逻辑过于复杂,可以考虑将中间结果落成临时表。
谓词下推
谓词下推(Predicate Pushdown, PPD)是 Hive 一个非常重要的自动优化功能,它会尽可能地将 WHERE 子句中的过滤条件前移(下推)到数据扫描阶段,以减少后续计算步骤(如 JOIN)处理的数据量。
数仓实际开发中经常会涉及到多表关联,这个时候就会涉及到on与where的使用。一般在面试的时候会提问:条件写在where里和写在on里有什么区别?
这是一个非常经典的问题,因为它直接关系到 SQL 的执行结果和性能。我们可以从 INNER JOIN 和 OUTER JOIN 两种情况来回答:
面试官您好,关于这个问题,我的理解如下:
ON和WHERE的核心区别在于逻辑执行顺序。ON子句的条件是在生成临时表(即JOIN关联)时使用的,而WHERE子句的条件是在临时表生成之后,对最终结果进行过滤时使用的。这个顺序差异在INNER JOIN和OUTER JOIN中表现不同。1. 对于
INNER JOIN(内连接):
- 结果:没有区别。无论条件写在
ON还是WHERE中,最终返回的结果集都是一样的。因为INNER JOIN只返回两个表中都能匹配上的行,不满足任何一个条件的行都会被过滤掉。- 性能:理论上也没有区别。虽然逻辑上
ON先于WHERE执行,但现在绝�大多数数据库的优化器(包括 Hive)都足够智能,会自动进行谓词下推(Predicate Pushdown)。它会把WHERE子句中的过滤条件提前到数据扫描阶段,所以最终的执行计划通常是相同的。- 代码规范:从代码可读性和逻辑清晰度来说,推荐将用于表关联的条件写在
ON子句中,将用于结果集过滤的条件写在WHERE子句中。2. 对于
OUTER JOIN(外连接,以LEFT JOIN为例):
- 结果:有本质区别,这也是考察的重点。
条件写在
ON子句:ON条件是在JOIN发生时,用来**过滤右表(非保留表)**的。系统会先根据ON的条件对右表进行过滤,然后再用过滤后的右表与左表(保留表)进行JOIN。对于左表中不满足ON条件的行,它依然会被保留下来,只是右表对应的字段会显示为NULL。简单说,ON条件只影响右表,不影响左表的行数。条件写在
WHERE子句:WHERE条件是在LEFT JOIN生成结果集之后再进行过滤。LEFT JOIN会先把左表所有行都包含进来,然后WHERE子句开始工作。如果WHERE条件引用了右表的字段,并且该条件为FALSE或UNKNOWN(例如NULL = 'value'),那么即使是左表中本应保留的行也会被过滤掉。这会导致LEFT JOIN退化成INNER JOIN的效果。举个例子:
总结:
INNER JOIN中,ON和WHERE在结果和性能上基本无差别,但建议按逻辑功能区分使用。OUTER JOIN中,ON是“连接前”的过滤,WHERE是“连接后”的过滤。把对非保留表的过滤条件放在WHERE中,通常会得到非预期的结果,这是开发中需要特别注意的陷阱。
相关参数:
-- 开启谓词下推优化(默认为 true)
set hive.optimize.ppd = true;
1) 示例SQL语句
-- 内关联:
hive (default)>
explain
SELECT t1.id
,t2.province_name
from ds_hive.ch12_order_detail_orc t1
right join ds_hive.ch12_province_info_orc t2
on t1.province_id=t2.id
where t1.product_num=20 and t2.province_name='江苏'
;
-- 左外关联
explain
SELECT t1.id
,t2.province_name
from ds_hive.ch12_order_detail_orc t1
left join ds_hive.ch12_province_info_orc t2
on t1.province_id=t2.id and t2.province_name='江苏'
where t1.product_num=20
;
2) 关闭谓词下推优化
set hive.optimize.ppd = false;
-- 为了测试效果更加直观,关闭其他优化
set hive.cbo.enable=false;
set hive.auto.convert.join=false;
通过执行计划可以看到,关闭谓词下推后,Hive 会先执行 JOIN 操作,将两张表的所有数据关联起来,然后再对这个庞大的中间结果集进行 WHERE 过滤。如果两张表数据量都很大,执行效率会非常低下。
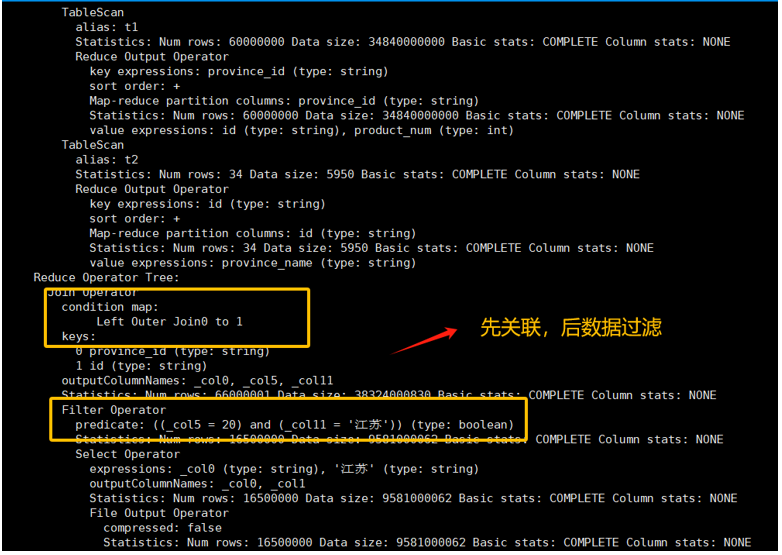
3) 开启谓词下推优化
set hive.optimize.ppd = true;
set hive.cbo.enable=false;
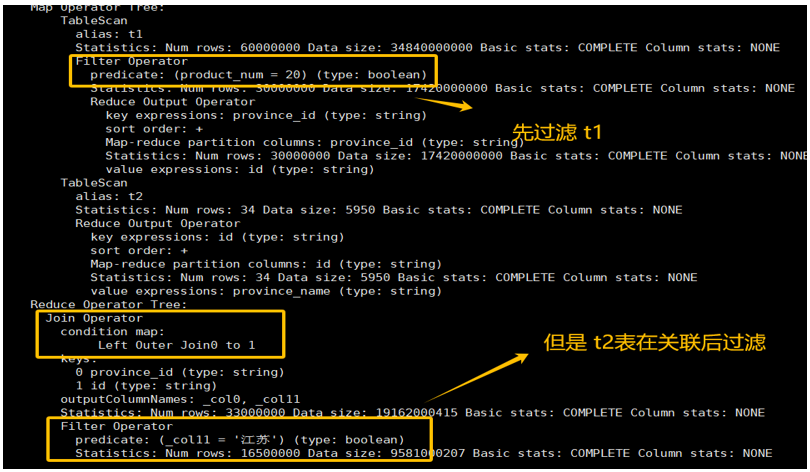
开启后,从执行计划中可以明显看出,过滤操作(Filter Operator)被移动到了 JOIN 操作之前。Hive 会先在各自的表上应用 WHERE 条件,用过滤后的小数据集去执行 JOIN,从而大大减少了关联的数据量,提升了整体执行效率。
4) 开启谓词下推并优化SQL
set hive.optimize.ppd = true;
set hive.cbo.enable=false;
explain
SELECT t1.id
,t2.province_name
from ds_hive.ch12_order_detail_orc t1
right join ds_hive.ch12_province_info_orc t2
on t1.province_id=t2.id and t2.province_name='江苏' ----t2条件改在on里
where t1.product_num=20
;
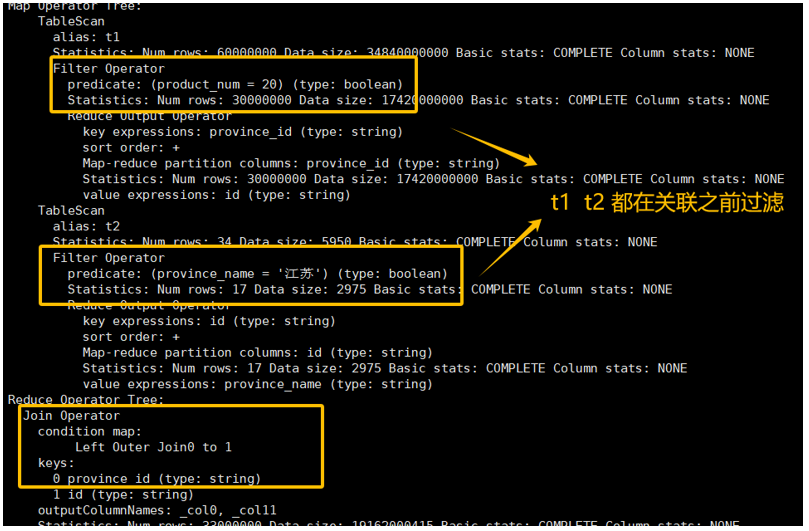
结论与最佳实践:
核心记忆法则:
- Inner Join: 条件写在
ON或WHERE效果相同,都会被下推。- Outer Join (Left/Right):
- 想过滤主表(保留行的一方,如 Left Join 的左表),条件必须写在
WHERE子句中。- 想过滤从表(可能出现 NULL 的一方,如 Left Join 的右表),条件必须写在
ON子句中。如果写在WHERE中,会使OUTER JOIN的效果退化成INNER JOIN。- Full Outer Join: 谓词下推通常不生效。
原始结论总结:
- 对于
Inner Join,条件写在on后面还是where后面,谓词下推都生效;对于Full outer Join,都不生效。 - 对于
Left outer Join,右侧的表(从表)条件写在on后面、左侧的表(主表)条件写在where后面,谓词下推生效。 - 对于
Right outer Join,左侧的表(从表)条件写在on后面、右侧的表(主表)条件写在where后面,谓词下推生效。
官网定义解释:https://cwiki.apache.org/confluence/display/Hive/OuterJoinBehavior 翻译如下图:

根据官网定义,上面的规则可以改写为:
- 保留表(主表)的谓词写在
ON中不能下推,需要用WHERE。 - 非保留表(从表)的谓词写在
WHERE之后会改变JOIN的语义,需要用ON。 - 在
INNER JOIN关联情况下,过滤条件无论在ON中还是WHERE中谓词下推都生效。 - 在
FULL JOIN关联情况下,过滤条件无论在ON中还是WHERE中谓词下推都不生效。
sort by 代替 order by
ORDER BY 在 Hive 中执行全局排序,这意味着所有数据都会被发送到一个 Reducer 任务中进行排序。当数据量巨大时,这个单一的 Reducer 会成为性能瓶颈,导致任务长时间无法完成甚至失败。
为了避免这种情况,我们可以使用局部排�序 SORT BY。
SORT BY: 在每个 Reducer 内部进行排序,保证每个 Reducer 的输出是局部有序的。它通常与DISTRIBUTE BY配合使用。DISTRIBUTE BY: 控制 Map 的输出如何分区到 Reducer。它根据指定的 key 将数据哈希到不同的 Reducer,确保相同 key 的数据进入同一个 Reducer。
场景1:获取全局Top N
如果需要获取全局排序后的前 N 条记录,直接使用 ORDER BY ... LIMIT N 在数据量大时效率低下。可以采用两阶段排序的优化方法:
-- 原脚本 (数据量大时性能差)
create table ds_hive.ch12_order_detail_orc_orderby as
select *
from ds_hive.ch6_t_goods
order by cast(price as int)
limit 10000;
-- 优化脚本 (分布式Top N)
-- 1. 内层查询:使用 DISTRIBUTE BY 和 SORT BY,在每个 Reducer 中进行局部排序,得到每个 category 下按 price 排序的结果。
-- 2. 外层查询:对这些已经局部有序的小数据集进行最终的全局排序。由于数据量和顺序性都已优化,此步非常快。
create table ds_hive.ch12_order_detail_orc_sortby as
select *
from (
select *
from ds_hive.ch6_t_goods
distribute by category -- 按 category 分发到不同 reducer
sort by cast(price as int) -- 在每个 reducer 内按 price 排序
) t1
order by cast(price as int)
limit 10000;
注意�:在严格模式下 (set hive.mapred.mode=strict),执行 ORDER BY 必须带上 LIMIT。如果业务场景不需要严格的全局有序,仅使用 SORT BY(局部有序)是更高效、更安全的选择。
-- 如果只需要局部有序的结果,或为后续窗口函数做准备,这样就足够了。
-- 新版本的 Hive 可能会将 sort by + limit 自动优化为更高效的执行计划。
create table ds_hive.ch12_order_detail_orc_sortby as
select *
from ds_hive.ch6_t_goods
distribute by category
sort by cast(price as int)
limit 10000;