窗口函数 ⭐️⭐️⭐️
重中之重 ⭐️⭐️⭐️
在日常数据分析中,我们经常遇到这样的需求:计算每个用户截至当前日期的累计消费总额、找出每个部门工资排名前三的员工、分析用户连续登录天数等等。
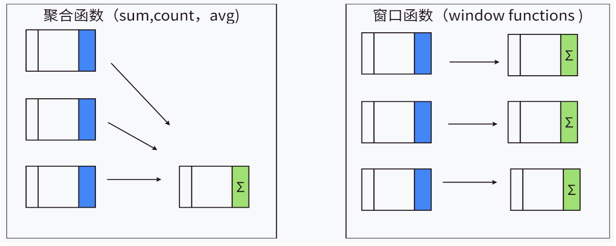
如果使用传统的 GROUP BY 聚合函数,虽然可以进行分组统计,但它会将多行数据压缩为一行,我们无法在保留原始行细节的同时进行计算。而SQL窗口函数,正是解决这类问题的“神器”。它能在保留原始数据行的基础上,为每一行计算出一个与“窗口”(即一组相关行)相关的聚合或排序值,极大地增强了SQL的分析能力。
本文将从窗口函数的基本概念和语法入手,通过丰富的实例,逐步深入到各类函数的具体应用和经典实战场景。
一、 窗口函数的核心语法
【函数定义】:如果一个函数具有OVER()子句,那么它就是窗口函数。窗口函数,又名开窗函数,属于分析函数的一种,它在指定的数据“窗口”内执行计算,用于解决复杂的报表统计需求。
它与普通聚合函数的最大不同在于:聚合函数对每个组只返回一行,而窗口函数为每个组返回多行(通常是保留原始行数)。
窗口函数的基本语法结构如下:
分析函数/专用窗口函数 OVER (
[PARTITION BY 列名, ...]
[ORDER BY 列名, ...]
[ROWS|RANGE BETWEEN 开始位置 AND 结束位置]
)
OVER()子句的三个组成部分(PARTITION BY, ORDER BY, ROWS|RANGE BETWEEN)可以单独使用,也可以组合使用,甚至可以全部省略。下面我们来详细解析这三个部分。
1. PARTITION BY:划分数据“窗口”
PARTITION BY 用于将数据划分为不同的组或分区,后续的计算将在每个分区内独立进行。这个划分的范围就被称为“窗口”,这也是窗口函数名称的由来。如果省略 PARTITION BY,则整个结果集将被视为一个单一的大窗口。
2. ORDER BY:窗口内排序与“累积”魔法
ORDER BY 用于在每个分区(窗口)内部对数据进行排序。它在窗口函数中的作用非常关键,有两个核心情景:
-
情景一(用于排序):当与
PARTITION BY连用时,它会对各个分区内的数据按指定字段排序。如果省略PARTITION BY,则会对全局数据进行排序。这主要用于ROW_NUMBER()、RANK()等排序函数。 -
情景二(定义累积计算范围):当用于聚合函数(如
SUM,AVG,COUNT)时,ORDER BY不仅起到排序作用,更重要的是它隐式地定义了一个从分区开始到当前行的累��积计算范围。这是实现累积求和、累积平均等功能的关键。
(这里多说一句,四个 by的区别理解了吗?
group by,order by,partition by,distribute by)
3. ROWS|RANGE BETWEEN ... AND ...:定义“窗口帧”
窗口帧(Window Frame)用于从分区中更精确地选择一个子集(多条记录),供窗口函数处理。Hive 提供了 ROWS(基于物理行数)和 RANGE(基于逻辑值)两种定义形式。
常用的边界参数如下:
n PRECEDING:往前 n 行。n FOLLOWING:往后 n 行。CURRENT ROW:当前行。UNBOUNDED PRECEDING:分区的起点(第一行)。UNBOUNDED FOLLOWING:分区的终点(最后一行)。
常用组合示例(好好记忆):
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:从分区起点到当前行。ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING:从当前行到分区终点。ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING:整个分区,从起点到终点。
窗口帧示例 (以SUM为例)
为了更直观地理解窗口帧,我们来看一个例子。假设我们想计算每个用户不同窗口范围内的订单金额总和。
【执行脚本】:
SELECT
user_id,
order_date,
order_amount,
-- 1. 累积求和 (从分区起点到当前行)
SUM(order_amount) OVER(PARTITION BY user_id ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sum_cumulative,
-- 2. 滑动求和 (当前行 + 前后各一行)
SUM(order_amount) OVER(PARTITION BY user_id ORDER BY order_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS sum_sliding,
-- 3. 分区总和 (整个分区)
SUM(order_amount) OVER(PARTITION BY user_id ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS sum_partition
FROM ds_hive.ch8_t_order
WHERE user_id = 'user2'; -- 以user2为例
【执行结果与解释】:
假设 user2 的订单数据如下:
| order_date | order_amount |
|---|---|
| 2025-10-01 | 100 |
| 2025-10-02 | 150 |
| 2025-10-03 | 200 |
| 2025-10-04 | 120 |
执行上述查询后,结果如下:
| user_id | order_date | order_amount | sum_cumulative | sum_sliding | sum_partition |
|---|---|---|---|---|---|
| user2 | 2025-10-01 | 100 | 100 | 250 (100+150) | 570 |
| user2 | 2025-10-02 | 150 | 250 (100+150) | 450 (100+150+200) | 570 |
| user2 | 2025-10-03 | 200 | 450 (250+200) | 470 (150+200+120) | 570 |
| user2 | 2025-10-04 | 120 | 570 (450+120) | 320 (200+120) | 570 |
sum_cumulative:标准的累积求和,计算从分区第一行到当前行的总和。sum_sliding:计算一个滑动窗口(当前行、前一��行、后一行)的总和。注意边界情况,第一行没有前一行,最后一行没有后一行。sum_partition:计算整个分区的总和,所以每一行的值都是相同的。
必须知道:窗口帧的默认值规则
- 如果
OVER()子句中只指定了PARTITION BY而没有ORDER BY,则默认窗口帧是ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING(即整个分区)。- 如果
OVER()子句中同时指定了ORDER BY,则默认窗口帧是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(即从分区起点到当前行)。这个默认行为是实现累积计算的基础。
二、 窗口函数的分类与应用
下面我们将通过具体的例子来学习不同类型的窗口函数。
准备工作:创建示例表与数据
1)建表语句
hive (default)>
create table ds_hive.ch8_t_order
(
order_id string, --订单id
user_id string, -- 用户id
user_name string, -- 用户姓名
order_date string, -- 下单日期
order_amount int -- 订单金额
)
row format delimited fields terminated by '\t'
stored as textfile
;
2)装载语句
load data local inpath "/home/hewwen8888/data/ch8_t_order.txt" overwrite into table ds_hive.ch8_t_order;
1. 排序窗口函数
这类函数用于在窗口内为每一行生成一个排名或序号。
ROW_NUMBER(): 连续排名,即使值相同,排名也不同 (1, 2, 3, 4)。RANK(): 并列排名,排名相等时会跳过后续名次 (1, 2, 2, 4)。DENSE_RANK(): 并列连续排名,排名相等时不会跳过后续名次 (1, 2, 2, 3)。
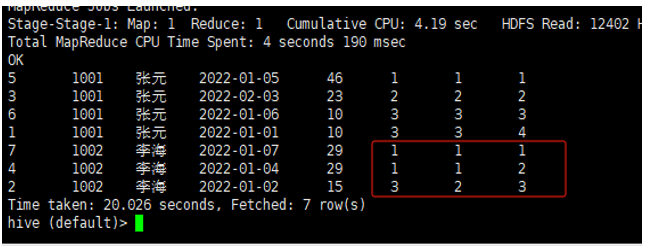
案例:统计每个用户的订单金额排序。
【执行脚本】:
------ 比较三种排序函数的区别
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_amount DESC) AS rnk_row_number,
RANK() OVER(PARTITION BY user_id ORDER BY order_amount DESC) AS rnk_rank,
DENSE_RANK() OVER(PARTITION BY user_id ORDER BY order_amount DESC) AS rnk_dense_rank
FROM ds_hive.ch8_t_order;
【执行结果】:
2. 聚合窗口函数
常见的聚合函数如 SUM(), AVG(), COUNT(), MAX(), MIN() 都可以用作窗口函数。当与 ORDER BY 结合使用时,它们默认计算从分区起点到当前行的累积值。
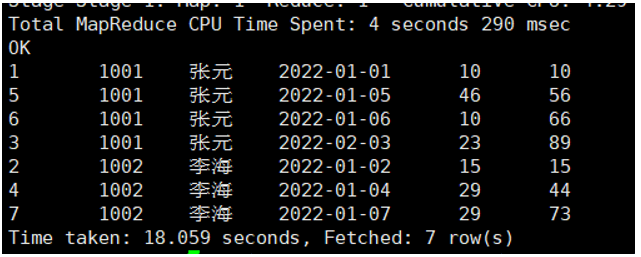
案例1:统计每个用户截至每次下单的累积下单总额。
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
-- 因为有ORDER BY,默认窗口帧就是从起点到当前行,所以 "ROWS BETWEEN..." 可以省略
SUM(order_amount) OVER(PARTITION BY user_id ORDER BY order_date) AS sum_so_far
FROM ds_hive.ch8_t_order;
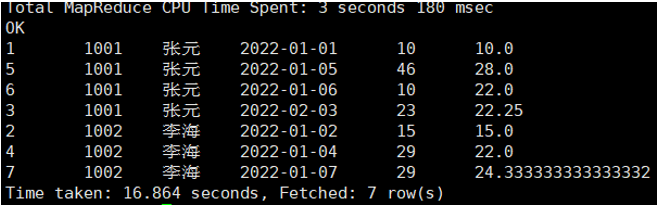
案例2:统计每个用户截至每次下单的平均下单金额。
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
AVG(order_amount) OVER(PARTITION BY user_id ORDER BY order_date) AS avg_so_far
FROM ds_hive.ch8_t_order;
【执行结果】:
案例3:统计每个用户截至每次下单的最大/最小单额。
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
MIN(order_amount) OVER(PARTITION BY user_id ORDER BY order_date) AS min_so_far,
MAX(order_amount) OVER(PARTITION BY user_id ORDER BY order_date) AS max_so_far
FROM ds_hive.ch8_t_order;
【执行结果】:
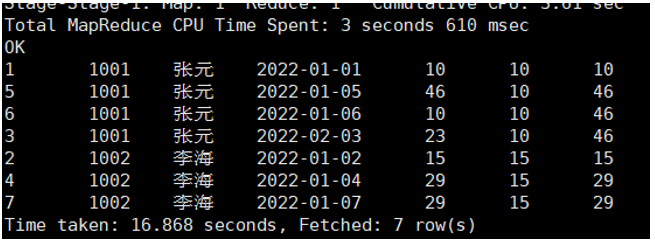
案例4:统计每个用户截至每次下单的订单数。
SELECT
user_id,
user_name,
order_date,
order_amount,
COUNT(order_id) OVER(PARTITION BY user_id ORDER BY order_date) AS count_so_far
FROM ds_hive.ch8_t_order;
【执行结果】:
3. 位移窗口函数
这类函数用于访问窗口内当前行之前或之后的行的值,常用于计算同比、环比等指标。
LAG(col, n, default): 获取当前行向上第 n 行的col列值。LEAD(col, n, default): 获取当前行向下第 n 行的col列值。
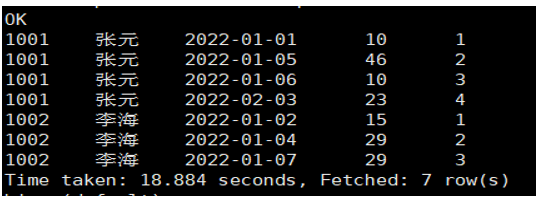
案例:统计每个用户每次下单距离上次下单相隔的天数(首次下单按0天算)。
【执行脚本】:
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
NVL(DATEDIFF(order_date, last_order_date), 0) AS diff_days
FROM (
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
-- 获取上一次的下单日期
LAG(order_date, 1, NULL) OVER(PARTITION BY user_id ORDER BY order_date) AS last_order_date
FROM ds_hive.ch8_t_order
) t1;
【执行结果】:
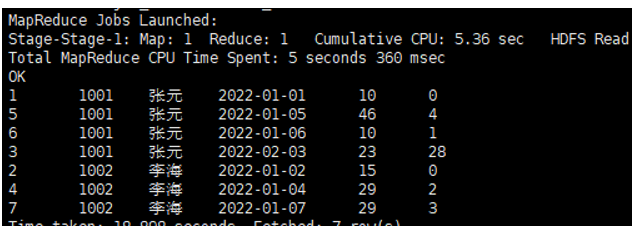
LEAD函数示例:
LEAD 与 LAG 相反,用于获取后续行的值,例如可用于分析用户下一次购买行为。
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
LAG(order_amount, 1, 0) OVER(PARTITION BY user_id ORDER BY order_date) AS last_amount,
LEAD(order_amount, 1, 0) OVER(PARTITION BY user_id ORDER BY order_date) AS next_amount
FROM ds_hive.ch8_t_order;
【执行结果】:
4. 极值窗口函数
FIRST_VALUE(col): 取分区内排序后,窗口帧中的第一个值。LAST_VALUE(col): 取分区内排序后,窗口帧中的最后一个值。
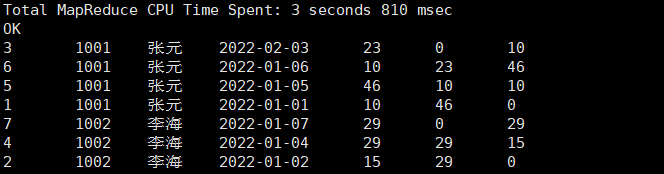
案例:查询所有下单记录以及每个用户在当月的首次和末次下单日期。
【执行脚本】:
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
FIRST_VALUE(order_date) OVER(PARTITION BY user_id, SUBSTR(order_date, 1, 7) ORDER BY order_date) AS first_date_in_month,
-- 注意:要获取整个分区的最后一个值,必须将窗口帧定义为整个分区
LAST_VALUE(order_date) OVER(PARTITION BY user_id, SUBSTR(order_date, 1, 7) ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_date_in_month
FROM ds_hive.ch8_t_order;
【执行结果】:
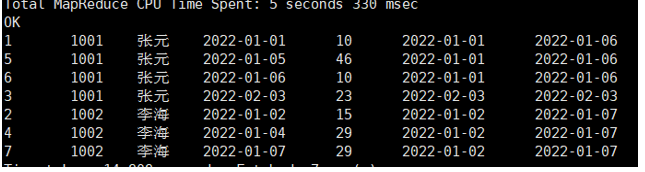
特别注意:
LAST_VALUE函数有一个常见陷阱。由于带ORDER BY的默认窗口帧是到CURRENT ROW,如果不显式指定ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING,LAST_VALUE的结果将永远是当前行的值,失去了其应有的意义。
5. 分箱窗口函数
NTILE(n): 将分区内的数据按序切分成 n 个桶(分箱),并返回当前行所在的桶编号。
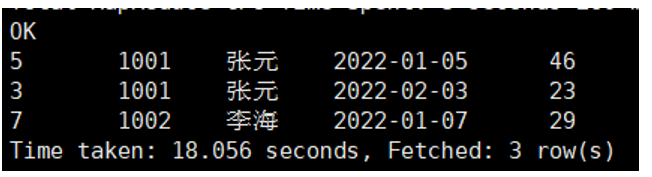
案例:统计每个用户订单金额最多的前1/3的订单。
【执行脚本】:
SELECT
t1.order_id,
t1.user_id,
t1.user_name,
t1.order_date,
t1.order_amount
FROM (
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
-- 按金额降序,切成3个桶
NTILE(3) OVER(PARTITION BY user_id ORDER BY order_amount DESC) AS rnk
FROM ds_hive.ch8_t_order
) t1
WHERE t1.rnk = 1; -- 编号为1的桶即为前1/3
【执行结果】:
三、 三大经典实战场景
掌握了基础函数后,我们来看几个在大厂面试和实际工作中频出的经典问题。
1. TopN 问题
TopN问题在中大厂的笔试面试中出现频率非常高,要求所有人都要掌握!
TopN问题是指从数据表中查询出前N个最大或最小的数据记录,这种问题在大数据业务分析中非常常见,例如查询热门商品Top10、热门话题Top20、热门搜索Top10等。
一旦题目中出现:按照指标X取前10名、前50%、后25%、第1名等等字眼,基本可以定位该问题为TopN问题。
此外,TopN问题可以分为两类:全局TopN问题 和 分组TopN问题。
TopN问题是指从数据表中查询出每个分组内前N个最大或最小的数据记录。一旦题目中出现“前10名”、“前25%”、“第1名”等字眼,基本都可以用窗口函数解决。
案例1:求每个用户,金额排名前2的订单信息。
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount
FROM (
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_amount DESC) AS rn
FROM ds_hive.ch8_t_order
) t1
WHERE t1.rn <= 2;
案例2:求每个用户,金额排名前25%的订单信息。
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount
FROM (
SELECT
order_id,
user_id,
user_name,
order_date,
order_amount,
-- 使用NTILE(4)将数据分为4个桶,第1个桶就是前25%
NTILE(4) OVER(PARTITION BY user_id ORDER BY order_amount DESC) AS rn
FROM ds_hive.ch8_t_order
) t1
WHERE t1.rn = 1;
2. 累加问题
需求:列出每月的订单总额以及截至到当前月的累计订单总额。
SELECT
t1.mon,
t1.monthly_amount,
-- 对聚合后的月度数据,按月份排序进行累加
SUM(t1.monthly_amount) OVER(ORDER BY t1.mon) AS cumulative_amount
FROM (
SELECT
SUBSTR(order_date, 1, 7) AS mon,
SUM(order_amount) AS monthly_amount
FROM ds_hive.ch8_t_order
GROUP BY SUBSTR(order_date, 1, 7)
) t1;
3. 连续性问题
连续登录/下单问题是SQL面试中的高频考点,核心在于如何识别“连续”的日期。
解决思路:关键在于构造一个在连续周期内保持不变的分组标识。我们可以通过 日期 - 排名 的方式来实现。对于连续的日期,它们的日期和排名(ROW_NUMBER)同步增长,相减后会得到一个固定的差值。
步骤拆解:
-
排序:使用
ROW_NUMBER()为每个用户的下单日期进行排序,得到排名rn。 -
构造分组标识:用下单日期
order_date减去排名rn(DATE_SUB(order_date, rn))。连续日期的这个差值是相同的。可视化理解:
user_id order_date rn date_sub(order_date, rn)分组标识 user1 2025-10-01 1 2025-09-30 组A user1 2025-10-02 2 2025-09-30 组A user1 2025-10-04 3 2025-10-01 组B user1 2025-10-05 4 2025-10-01 组B -
分组聚合:按用户和我们构造的分组标识进行分组,统计每个组内的记录数,筛选出满足连续天数条件的记录。
案例:求连续2天下单的用户。
【完整代码】:
SELECT
user_id,
date_group,
COUNT(*) AS continuous_days
FROM (
SELECT
user_id,
-- 构造分组标识,注意别名不要与rn冲突
DATE_SUB(order_date, ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY order_date)) AS date_group
FROM ds_hive.ch8_t_order
-- 如果一个用户一天可能有多条记录,需要先去重
-- GROUP BY user_id, order_date
) t1
GROUP BY user_id, date_group
HAVING COUNT(*) = 2;