分组聚合详解及优化 ⭐️⭐️⭐️
掌握 ⭐️⭐️⭐️
1 Group By 分组语句
Group By 语句通常会和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每个组执行聚合操作。
1) 案例实操:
(1)计算每个类别中的商品数。
hive (default)>
select
category,
count(id) as cnt
from ds_hive.ch6_t_goods
group by category;
(2)计算各个类别的价格总和和求每个类型中最高,最低的商品价格。
hive (default)>
select
category,
sum(price) as cnt,
max(price) as max,
min(price) as min_p
from ds_hive.ch6_t_goods
group by category;
思考: 当某一个分组键的值的数据量远远大于其他值时,会出现什么问题?怎么处理?(这个问题将在 4 节中详细解答)
2 Having 语句
Having 语句用于在 GROUP BY 分组之后对聚合结果进行过滤。
1) having与where不同点
- (1)
where在分组聚合前对原始数据进行过滤,其后不能使用聚合函数。 - (2)
having在分组聚合后对结果进行过滤,其后可以使用聚��合函数。 - (3)
having必须与group by配合使用。
2) 案例实操
① 求每个类别中商品的平均价格。
hive (default)>
select
category,
avg(price) as avg_p
from ds_hive.ch6_t_goods
group by category;
② 求每个类别中商品的平均价格大于100的类别。
hive (default)>
select
category,
avg(price) as avg_p
from ds_hive.ch6_t_goods
group by category
having avg_p >= 100;
3 多维分析场景
在数据分析中,我们常常需要从多个维度对数据进行聚合分析,例如同时计算“按天”、“按用户”、“按天+用户”以及总计的订单数。Hive 提供了 GROUPING SETS, CUBE, ROLLUP 等高级功能来简化这类多维分析查询。
3.1. grouping sets语句使用
grouping sets 是 GROUP BY 子句的一种扩展,它允许你在一个查询中定义多个分组集(grouping sets)。这等同于将多个��不同 GROUP BY 条件的查询结果 UNION ALL 起来,但语法更简洁,执行效率也更高。
示例1:
GROUP BY GROUPING SETS ((a,b)) 等价于 GROUP BY a, b
-- GROUPING SETS 是 GROUP BY 的一种扩展语法
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY GROUPING SETS ((order_date, user_id));
-- 上述语句等价于一个标准的多列 GROUP BY
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY order_date, user_id;
示例2:
GROUPING SETS ((order_date,user_id), user_id) 等于按 (order_date, user_id) 分组和按 user_id 分组的并集。
-- 按 (order_date, user_id) 和 (user_id) 两个维度聚合
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY GROUPING SETS ((order_date, user_id), user_id);
-- 等价于
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY order_date, user_id
UNION ALL
SELECT null, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY user_id;
示例3:
GROUPING SETS (order_date, user_id) 等于按 order_date 分组和按 user_id 分组的并集。
-- 按 (order_date) 和 (user_id) 两个维度聚合
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY GROUPING SETS (order_date, user_id);
-- 等价于
SELECT order_date, null, count(*)
FROM ds_hive.ch6_t_order
GROUP BY order_date
UNION ALL
SELECT null, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY user_id;
示例4:
GROUPING SETS ((order_date,user_id), order_date, user_id, ()) 等于按 (order_date, user_id) 分组、按 order_date 分组、按 user_id 分组和全表聚合(总计)的并集。空括号 () 代表对所有数据进行聚合。
-- 按 (order_date, user_id), (order_date), (user_id) 和 () 四个维度聚合
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY GROUPING SETS ((order_date, user_id), order_date, user_id, ());
-- 等价于
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY order_date, user_id
UNION ALL
SELECT order_date, null, count(*)
FROM ds_hive.ch6_t_order
GROUP BY order_date
UNION ALL
SELECT null, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY user_id
UNION ALL
SELECT null, null, count(*)
FROM ds_hive.ch6_t_order;
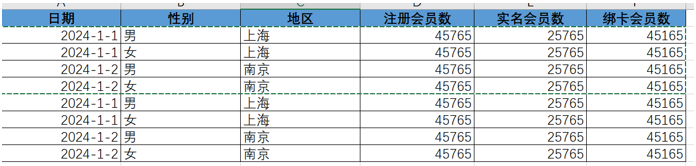
GROUPING SETS 常用于需要灵活组合维度的报表数据。例如:
- 无维度展现(总计):
- 选择性别维度展现:
- 选择性别和地区维度展现:


3.2. with cube�语句使用
WITH CUBE 是 GROUP BY 的一个修饰符,用于生成所有可能的分组组合的聚合结果。如果分组列为 (A, B, C),CUBE 会对 (A,B,C), (A,B), (A,C), (B,C), (A), (B), (C), () (总计) 所有 2^3=8 种组合进行分组。
group by a,b,c with cube 等效于 group by a,b,c grouping sets((a,b,c), (a,b), (a,c), (b,c), a, b, c, ())
-- 使用 with cube
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY order_date, user_id
WITH CUBE;
-- 等效于使用 GROUPING SETS
SELECT order_date, user_id, count(*)
FROM ds_hive.ch6_t_order
GROUP BY GROUPING SETS ((order_date, user_id), order_date, user_id, ());
3.3. with rollup语句使用
WITH ROLLUP 也是 GROUP BY 的一个修饰符,它会根据分组列的顺序,生成层级递进的聚合结果。它假设维度之间存在层级关系。
例如,GROUP BY a, b, c WITH ROLLUP 会对 (a,b,c), (a,b), (a), () 这几种组合进行分组,相当于从最细粒度逐级向上汇总。
GROUP BY a, b, c with rollup 等效于 GROUP BY a,b,c GROUPING SETS((a,b,c), (a,b), (a), ())
-- 使用 with rollup
SELECT
user_id,
product_id,
order_date,
count(id)
FROM ds_hive.ch6_t_order
GROUP BY
user_id,
product_id,
order_date
WITH ROLLUP;
-- 等价于使用 GROUPING SETS
SELECT
user_id,
product_id,
order_date,
count(id)
FROM ds_hive.ch6_t_order
GROUP BY
user_id,
product_id,
order_date
GROUPING SETS ((user_id, product_id, order_date), (user_id, product_id), (user_id), ());
3.4. GROUPING__ID使用
GROUPING__ID 函数可以用来识别结果集中的每一行是属于哪个分组集(grouping set)的。grouping sets 中的每一种粒度,都对应唯一的 grouping__id 值。
它的主要作用是:帮助我们区分聚合结果的层级。例如,我们可以用它来过滤出特定维度的数据,或者在报表中清晰地标识出小计(subtotal)和总计(grand total)行。ID 值为 0 通常表示最细粒度的聚合。
SELECT
grouping__id,
order_date,
user_id,
count(*)
FROM ds_hive.ch6_t_order
GROUP BY order_date, user_id
GROUPING SETS ((order_date, user_id), order_date, user_id, ());
3.5 grouping sets 执行过程及原理
结论先行:在绝大多数情况下,尤其是在处理大数据集时,GROUPING SETS 的性能会显著优于 UNION ALL。
下面从 SQL 执行的层面,特别是 MapReduce 的工作原理,来详细解释为什么。
假设有一张销售记录表 sales:
| region | product | amount |
|---|---|---|
| North | CPU | 100 |
| North | Memory | 50 |
| South | CPU | 200 |
| South | Disk | 80 |
| ... | ... | ... |
我们的目标是计算三个维度的聚合结果:
- 按
(region, product)聚合 - 按
(region)聚合(区域小计) - 总计(Grand Total)
方案一:使用 UNION ALL 的执行分析
如果我们使用 UNION ALL,SQL 会是这样:
-- 查询1: 按 (region, product) 聚合
SELECT region, product, SUM(amount) AS total_amount
FROM sales
GROUP BY region, product
UNION ALL
-- 查询2: 按 (region) 聚合
SELECT region, NULL AS product, SUM(amount) AS total_amount
FROM sales
GROUP BY region
UNION ALL
-- 查询3: 总计
SELECT NULL AS region, NULL AS product, SUM(amount) AS total_amount
FROM sales;
在 MapReduce 层面的执行流程:
Hive 会将这个 UNION ALL 查询分解成 3个独立 的 MapReduce 作业(Job)。
作业 1: GROUP BY region, product
- Map 阶段:
- 启动 Map Task,扫描整个
sales表。 - 对于每一行数据,生成一个键值对(Key-Value Pair)。Key 是
(region, product),Value 是amount。 - 例如,对于行
('North', 'CPU', 100),Mapper 会输出( ('North', 'CPU'), 100 )。
- 启动 Map Task,扫描整个
- Shuffle 阶段:
- 将 Map 输出的键值对按照 Key(即
(region, product))进行哈希分区,发送到不同的 Reducer。
- 将 Map 输出的键值对按照 Key(即
- Reduce 阶段:
- Reducer 接收到相同 Key 的所有 Value,进行聚合计算(
SUM)。 - 例如,Reducer 收到
( ('North', 'CPU'), [100, ...]),计算总和并输出最终结果。
- Reducer 接收到相同 Key 的所有 Value,进行聚合计算(
作业 2: GROUP BY region
- Map 阶段:
- 再次启动一个全新的 MapReduce 作业。
- Map Task 重新从头到尾扫描一遍
sales表。这是性能瓶颈的关键! - 这次,Key 是
(region),Value 是amount。 - 例如,对于行
('North', 'CPU', 100),Mapper 会输出( ('North'), 100 )。
- Shuffle & Reduce 阶段:
- 与作业1类似,只是聚合的粒度不同。
作业 3: 总计
- Map 阶段:
- 第三次启动 MapReduce 作业。
- Map Task 第三次完整扫描
sales表。 - 所有行的 Key 都是一个常量(例如
NULL或1),Value 是amount。
- Shuffle & Reduce 阶段:
- 由于所有 Key 都相同,所有数据都会被发送到一个 Reducer(可能导致数据倾斜),该 Reducer 计算全局总和。
UNION ALL 的核心问题:
- 多次数据扫描:源数据表
sales被完整地读取了3次。如果sales表有 1TB,那么总的磁盘 I/O 读取量就是 3TB。这是巨大的资源浪费。 - 多个 MapReduce 作业:启动和调度多个作业本身就有额外的开销(YARN 资源申请、任务初始化等)。
- 网络开销:数据被多次通过网络进行 Shuffle。
方案二:使用 GROUPING SETS 的执行分析
如果我们使用 GROUPING SETS,SQL 会简洁得多:
SELECT
region,
product,
SUM(amount) AS total_amount,
GROUPING__ID -- 可选,用于区分聚合级别
FROM sales
GROUP BY region, product
GROUPING SETS (
(region, product),
(region),
() -- 空括号代表总计
);
在 MapReduce 层面的执行流程:
Hive 的查询优化器(Optimizer)会将 GROUPING SETS 转换成 一个单独的、更智能 的 MapReduce 作业。
-
Map 阶段 (只扫描一次!):
- 启动 Map Task,只对
sales表进行一次完整的扫描。 - 对于输入的每一行数据,Mapper 会根据
GROUPING SETS中定义的每个聚合级别,生成多条 输出记录。为了区分这些记录,Hive 会引入一个额外的虚拟列,通常叫做GROUPING__ID。 - 例如,对于输入行
('North', 'CPU', 100),Mapper 会输出:- 为
(region, product)级别:- Key:
('North', 'CPU', GROUPING__ID=0) - Value:
100
- Key:
- 为
(region)级别:- Key:
('North', NULL, GROUPING__ID=1)(用 NULL 占位) - Value:
100
- Key:
- 为
()级别 (总计):- Key:
(NULL, NULL, GROUPING__ID=3)(用 NULL 占位) - Value:
100
- Key:
- 为
- 可以看到,Mapper 在一次读取中就准备好了所有聚合级别所需的数据。
- 启动 Map Task,只对
-
Shuffle 阶段:
- 将 Mapper 生成的所有键值对,按照组合后的 Key(包含
GROUPING__ID)进行 Shuffle。
- 将 Mapper 生成的所有键值对,按照组合后的 Key(包含
-
Reduce 阶段 (一次聚合):
- Reducer 会接收到来自不同聚合级别的数据。
- 例如,一个 Reducer 可能同时收到:
(('North', 'CPU', 0), [100, ...])(('North', NULL, 1), [100, 50, ...])
- Reducer 会根据 Key 中的
GROUPING__ID分别对它们进行SUM聚合,然后生成最终的输出行。
GROUPING SETS 的核心优势:
- 一次数据扫描:源数据表只被读取一次。I/O 开销大大降低,这是最关键的性能提升点。
- 一个 MapReduce 作业:避免了多次作业调度的开销,整个计算流程更加紧凑高效。
- 优化的 Shuffle:虽然 Mapper 输出的数据量可能会膨胀,但所有数据在一次 Shuffle 中完成,减少了网络传输的启动和关闭次数。
总结对比
| 特性 | GROUPING SETS | UNION ALL | 性能影响 |
|---|---|---|---|
| 数据扫描次数 | 1 次 | N 次 (N = UNION ALL 的子查询数量) | 巨大,I/O 是主要瓶颈 |
| MapReduce 作业数 | 1 个 | N 个 | 显著,减少了作业调度和初始化开销 |
| 磁盘 I/O | 低 | 非常高 | GROUPING SETS 完胜 |
| 网络 Shuffle | 一次性、更高效 | 多次独立的 Shuffle | GROUPING SETS 资源利用率更高 |
| SQL 简洁性 | 非常简洁,易于维护 | 冗长,容易出错 | GROUPING SETS 代码可读性更好 |
| 优化器友好度 | 非常友好,给优化器最大空间 | 较差,优化器只能分别优化子查询 | GROUPING SETS 能实现全局最优计划 |
4 聚合原理及优化思路
还记得我们在 1 节提出的思考题吗?当分组的键中,某一个值的数据量远大于其他值时,就会在 MapReduce 阶段发生数据倾斜(Data Skew)。这会导致单个 Reduce Task 任务处理的数据量过大,成为整个作业的瓶颈。本节将深入探讨聚合的原理,并针对数据倾斜等问题提供优化思路。
4.1. 聚合原理
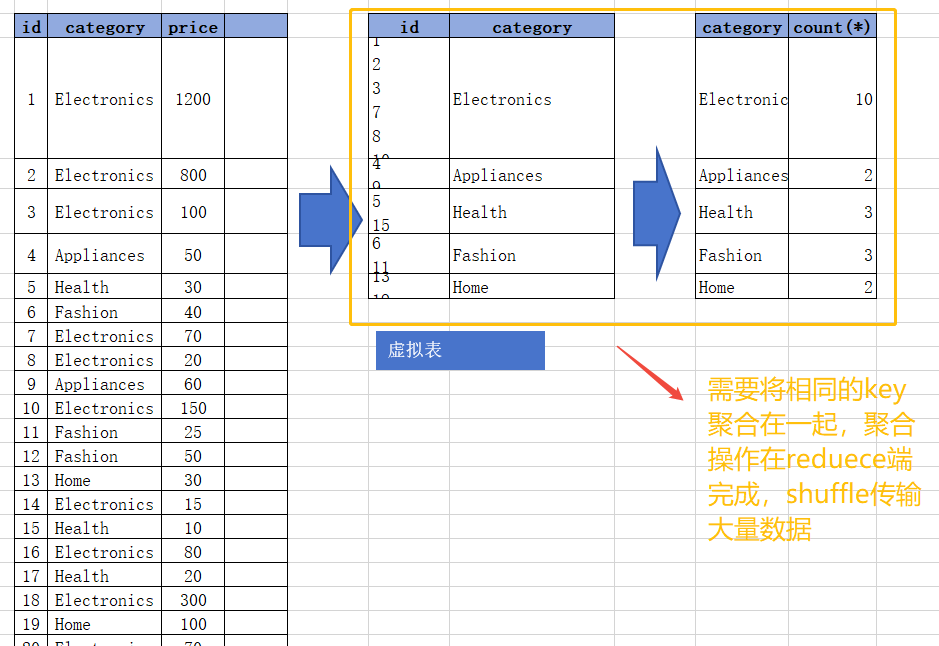
Hive HQL执行过程:
FROM ds_hive.ch6_t_goods:该句执行后,结果和下图表 1 一样,就是原来的表。Group BY category:该句执行后,会生成一个虚拟表。处理过程是:找到category列,将具有相同category值的行合并成一行,并将这些行的其他列(下图中为id)的值集合到一个单元格里面。SELECT聚合:如果执行select category的话,那么返回的结果应该是虚拟表3的category。但关系数据库的单元格不允许有多个值,此时就需要聚合函数(如count(id),sum(price))来处理这些集合,输入多个数据,输出一个数据。
其基本实现原理如下图:
4.2. Map端聚合
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通��过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是 map-side聚合。所谓map-side聚合,是在Hive的Map阶段开启预聚合,先在Map阶段对部分数据进行聚合,然后在Reduce阶段进行全局的最终聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
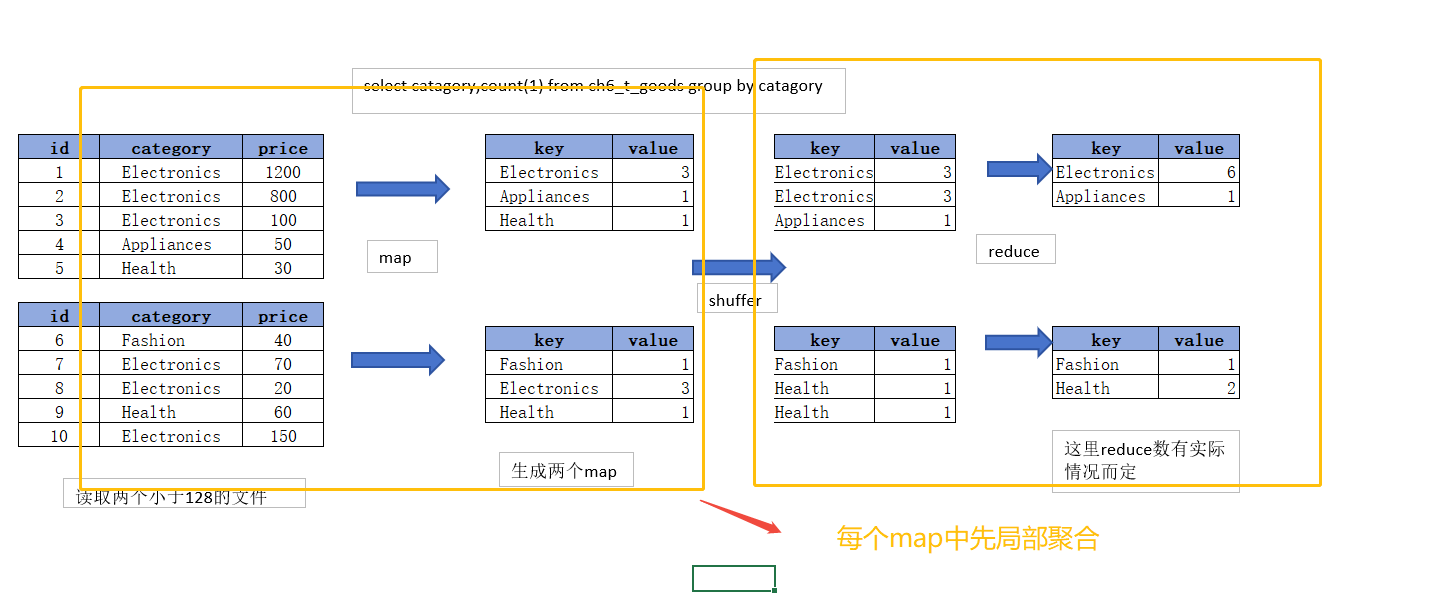
map-side 聚合相关的参数如下:
-- 启用map-side聚合,一般默认开启
set hive.map.aggr=true;
-- 用于检测源表数据是否适合进行map-side聚合。
-- 检测方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;
-- 否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
-- 用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
-- map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
优化案例
1)示例SQL
hive (default)> set hive.map.aggr=true;
explain
select
t1.province_id,
count(*) as cnt
from ds_hive.ch6_order_detail_orc t1
group by t1.province_id;
4.3. Count Distinct 的优化
在Hive中,DISTINCT 关键字用于对查询结果进行去重,以返回唯一的值。尽管 DISTINCT 非常有用,但在大数据场景下,尤其是 COUNT(DISTINCT ...),可能会引发严重的性能问题。(性能开销、数据倾斜、内存需求等)
问题根源:
COUNT(DISTINCT col) 操作会将所有数据发送到一个 Reducer 上进行去重和计数。这唯一的Reduce Task需要Shuffle大量的数据,并进行排序聚合等处理,成为整个作业的IO和运算瓶颈。
全局 COUNT(DISTINCT) 的瓶颈
当执行一个不带 GROUP BY 的全局 COUNT(DISTINCT) 时,例如:
select count(distinct id) from ds_hive.ch6_order_detail_orc;
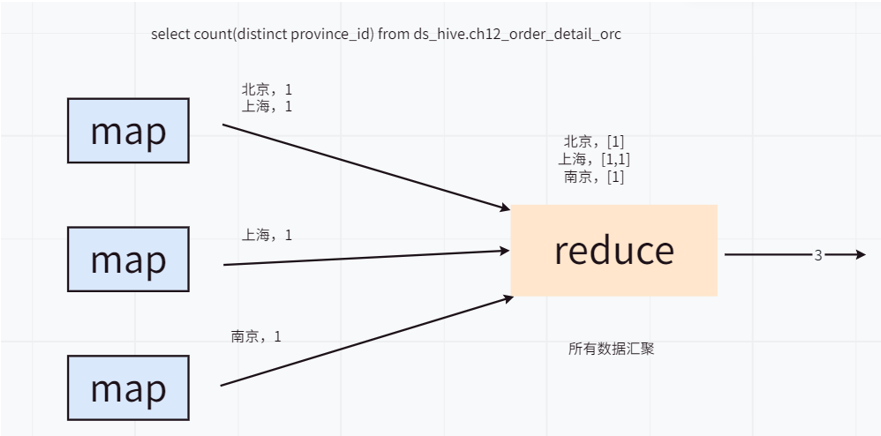
我们总结 distinct 之前,我们不得不先来看一下 group by 操作的具体实现原理。
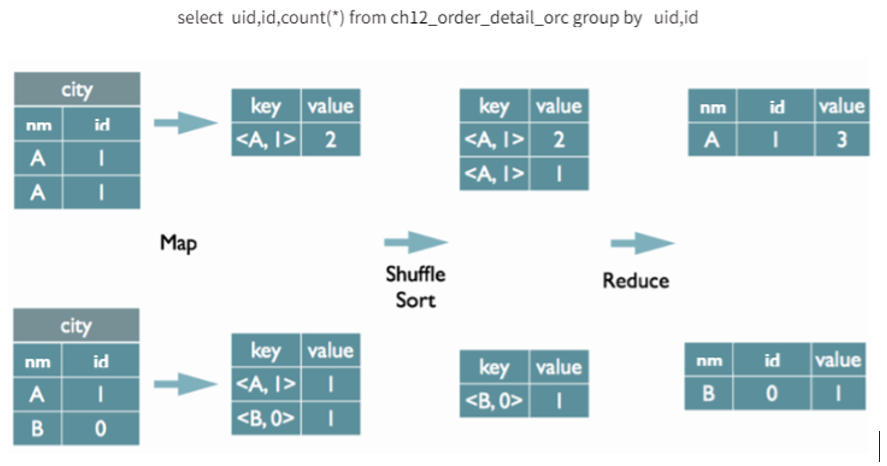
- Map阶段:将
group by后的字段组合作为一个key。将聚合操作的字段作为value(若进行count,则value为1;若进行sum,则 value 为该字段的实际值)。 - Shuffle阶段:按照key的不同分发到不同的reducer。此时可能因为key分布不均匀而出现数据倾斜。这个问题是我们处理数据倾斜比较常规的查找原因的方法之一,也是我们解决数据倾斜的处理阶段。
- Reduce阶段:对相同key的value进行累加(
count)或其他聚合操作。
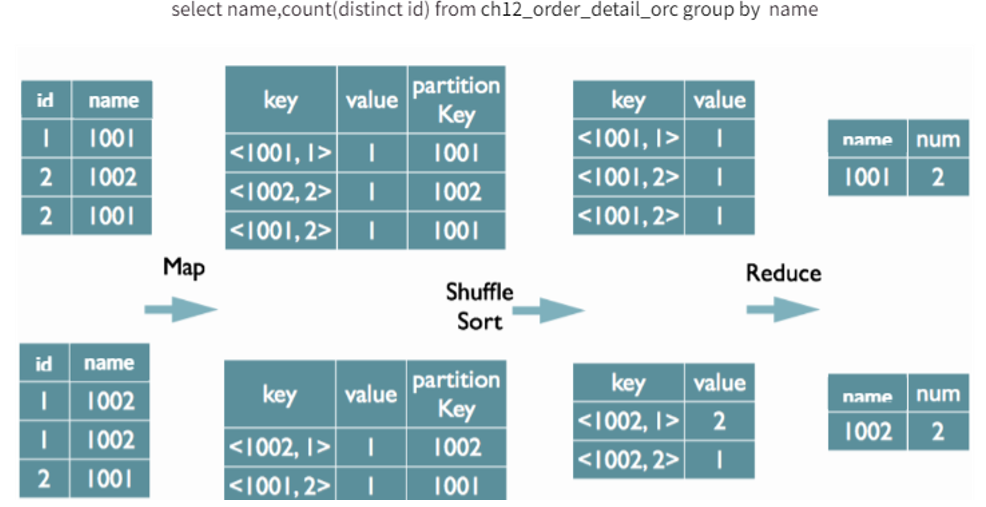
当执行 count(distinct) 操作时,Hive会将操作转化为一个MapReduce作业。它会将 group by 的字段和 distinct 的字段组合在一起作为map输出的key。这会导致 count(distinct) 全局聚合操作时,即使我们设定了reduce task的具体个数,Hive最终也只会启动一个reducer。这唯一的Reduce Task需要Shuffle大量的数据,并进行排序聚合等处理,成为整个作业的IO和运算瓶颈。
针对上述问题,我们可以修改对应的SQL来进行优化,采用 count + groupby 或者 sum + groupby 的方案来优化。在第一阶段选出全部的非重复的字段id,在第二阶段再对这些已消重的id进行计数。
优化原理:
优化的核心思想是分两步走,把压力分散开。我们采用 GROUP BY + COUNT 的方案来替代 COUNT(DISTINCT)。
- 第一步 (内层查询
GROUP BY id): 利用多个 Reducer 并行处理,对id进行去重。每个 Reducer 只处理一部分数据,完成后输出的是不重复的id。 - 第二步 (外层查询
COUNT(id)): 对已经去重的结果进行计数。此时数据量已经大大减少,即使只有一个 Reducer,也能很快完成。
优化示例:
-- 原始查询(性能较差)
select
count(distinct id) as cnt
from ds_hive.ch6_order_detail_orc;
-------------------优化,数据量越大越能体现效果-------------------
-- 优化后查询(性能更优)
select count(id)
from
(
select
id
from ds_hive.ch6_order_detail_orc
group by id
) t1;
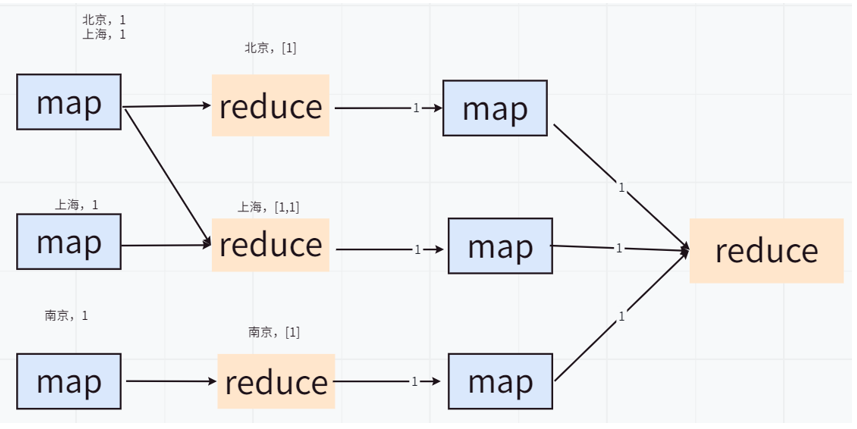
第一阶段我们可以通过增大Reduce的并发数,并发处理Map输出。在第二阶段,由于id已经消重,因此 COUNT(*) 操作在Map阶段不需要输出原id数据,只输出一个合并后的计数即可。这样即使第二阶段Hive强制指定一个Reduce Task,极少量的Map输出数据也不会使其成为瓶颈。
其实在实际运行时,Hive还对这两阶段的作业做了额外的优化。它将第二个MapReduce作业Map中的Count过程移到了第一个作业的Reduce阶段。这样在第一阶Reduce就可以输出计数值,而不是消重的全部id。这一优化大幅地减少了第一个作业的Reduce输出IO以及第二个作业Map的输入数据量。最终在同样的运行环境下优化后的语句可以说是大大提升了执行效率。
4.4. 多字段 COUNT(DISTINCT) 的原理及优化策略
一、多字段 COUNT(DISTINCT) 的默认执行原理
首先,我们需要理解Hive处理单个 COUNT(DISTINCT) 的方式。
例如:
SELECT pro, COUNT(DISTINCT userid) FROM tmp1 GROUP BY pro;
Hive通常会将 GROUP BY 字段(pro)和 DISTINCT 字段(userid)组合成MapReduce的Key进行排序。在Reduce阶段,数据会根据这个Key有序排列,此时只需通过比较相邻记录(LastKey)是否相同,就能高效地完成去重,这种方法效率高且节省内存。
对于上述SQL,Map阶段会将 pro 和 userid 组合成Key(例如 <a, 张三>),以便在Reduce阶段进行排序去重。
然而,当一个查询中包含多个 COUNT(DISTINCT) 表达式时,例如:
SELECT pro, COUNT(DISTINCT userid), COUNT(DISTINCT city) FROM tmp1 GROUP BY pro
Hive无法同时根据 (pro, userid) 和 (pro, city) 进行排序,因此无法再使用上述简单的 LastKey 方法来去重。
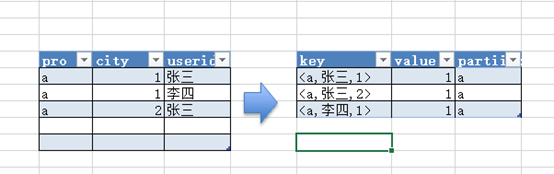
为了解决这个问题,Hive采用了一种特殊的处理方式:
- 数据复制与分发:在Map阶段,Hive会将同一条输入记录,根据
DISTINCT表达式的数量,生成多条记录进行Shuffle。 - 数据膨胀:假设有 N 个
COUNT(DISTINCT)表达式,输入数据有 M 条,那么经过Map阶段处理后,将输出 N * M 条数据。这就是所谓的“数据膨胀”,它会导致Shuffle阶段的数据量急剧增加,是导致性能瓶颈和数据倾斜的常见原因。 - 排序与去重:为了在Reduce阶段能够有效去重,Hive会对所有
DISTINCT字段进行编号。例如,将(pro, userid)标记为一组,(pro, city)标记为另一组。这样,在Reduce阶段就可以根据分组键(pro)和这个编号进行排序,然后通过记录每个编号分组内的LastKey来完成去重。
如下图所示,对于 COUNT(DISTINCT city) 和 COUNT(DISTINCT userid),每一条原始数据都被复制成了两条,并用编号(0和1)来区分,这直观地展示了数据膨胀的过程。

- 优缺点:这种方式巧妙地利用了MapReduce的排序能力,避免了在Reduce阶段因内存Hash去重而导致的内存溢出问题,但代价是牺牲了网络I/O(增加了Shuffle数据量)。
一个细节:在生成Reduce的Value时,通常只有第一个
DISTINCT字段所在的行需�要保留其原始值,其余行的Value字段可以为空,以减少数据传输量。
二、多字段 COUNT(DISTINCT) 的优化策略
针对上述默认实现方式带来的性能问题,我们可以采用一种更高效的优化方法,其核心思想是将一个多 COUNT(DISTINCT) 查询拆分为多个单 COUNT(DISTINCT) 查询,然后通过 SUM 合并结果。
这种优化可以分为以下三个步骤:
第一步:预处理与过滤
在进行任何复杂计算之前,应尽可能地收敛数据。通过 WHERE 子句或其他方式提前过滤掉不需要的数据,可以有效减少后续所有步骤的计算量,这是一个通用的优化原则。
第二步:拆分计算 - 使用 UNION ALL 分别处理每个 DISTINCT
这是优化的核心。我们将原始的单一查询,拆分成多个子查�询。每个子查询只负责计算一个 COUNT(DISTINCT),并将其他 DISTINCT 指标的位置用 0 占位。
优化前SQL:
SELECT
province_id,
COUNT(DISTINCT user_id) AS user_cnt,
COUNT(DISTINCT product_id) AS product_cnt
FROM
ds_hive.ch6_order_detail_orc
GROUP BY
province_id;
优化思路:
使用 UNION ALL 将其改写为两个独立的、只包含单个 COUNT(DISTINCT) 的子查询。
-- 子查询1:只计算 user_cnt
SELECT
province_id,
COUNT(DISTINCT user_id) AS user_cnt,
0 AS product_cnt
FROM
ds_hive.ch6_order_detail_orc
GROUP BY
province_id
UNION ALL
-- 子查询2:只计算 product_cnt
SELECT
province_id,
0 AS user_cnt,
COUNT(DISTINCT product_id) AS product_cnt
FROM
ds_hive.ch6_order_detail_orc
GROUP BY
province_id;
这样做的好处是,每个子查询都是一个简单的单 COUNT(DISTINCT) 聚合,其执行效率远高于多 COUNT(DISTINCT),并且避免了数据膨胀。
第三步:合并结果 - 使用外层 GROUP BY 和 SUM
将 UNION ALL 合并后的结果集作为一个临时表(或子查询),在外层通过一次 GROUP BY 和 SUM 聚合,得到最终结果。
最终优化后的完整SQL:
SELECT
province_id,
SUM(user_cnt) AS user_cnt,
SUM(product_cnt) AS product_cnt
FROM
(
-- 子查询1:只计算 user_cnt
SELECT
province_id,
COUNT(DISTINCT user_id) AS user_cnt,
0 AS product_cnt
FROM
ds_hive.ch6_order_detail_orc
GROUP BY
province_id
UNION ALL
-- 子查询2:只计算 product_cnt
SELECT
province_id,
0 AS user_cnt,
COUNT(DISTINCT product_id) AS product_cnt
FROM
ds_hive.ch6_order_detail_orc
GROUP BY
province_id
) AS T1
GROUP BY
province_id;
三、优化总结
这种“拆分-合并”的优化策略具有以下显著优势:
- 避免数据膨胀:从根本上避免了Hive默认策略导致的 N*M 数据膨胀,极大地减少了Shuffle的数据量。
- 提升执行效率:将复杂的、低效的多
COUNT(DISTINCT)操作转换为了多个高效的单COUNT(DISTINCT)和一次最终的SUM聚合。SUM聚合可以在Map端进行预聚合(Combine),进一步减少了需要传输到Reduce端的数据量。 - 降低数据倾斜风险:由于��避免了数据膨胀,数据分布更均匀,从而降低了数据倾斜的风险。
因此,在实际工作中,当遇到多字段 COUNT(DISTINCT) 的性能问题时,采用 GROUP BY + UNION ALL + SUM 的方式进行改写,通常会带来非常显著的性能提升。