Hive参数调优 ⭐️⭐️⭐️
重点掌握 ⭐️⭐️⭐️
本文将从 Map/Reduce 数量控制、任务并行度、Join 优化、数据抓取策略等多个核心方面,结合实际案例,深入探讨如何优化 Hive 任务的执行效率。
Map & Reduce 数量调优
合理控制 Map 和 Reduce 任务的数量是 Hive 调优中最基本也是最重要的一环。合适的任务数可以使集群资源得到充分且均衡的利用,从而显著提升作业的执行速度。
Map 数量的控制:合并与切分
Hive 中 Map 任务的数量并非由用户直接设定,而是由输入数据的大小和格式决定的。其主要取决于以下几个因素:
- 输入文件的总大小:所有输入文件的大小总和。
- 输入文件的数量:每个文件至少会产生一个 Map。
- HDFS 块大小(Block Size):Hadoop 集群的
dfs.block.size配置,这是数据存储的最小单元。
Hive 会为输入数据创建逻辑上的“分片”(Input Split),每个分片由一个 Map 任务处理。默认情况下,分片大小与 HDFS 块大小一致。
场景一:输入端小文件合并,减少 Map 数
当输入目录中存在大量小文件时,默认情况下,每个小文件都会启动一个 Map 任务。频繁地创建和销毁 Map 任务会带来巨大的额外开销,浪费集群资源。为了解决这个问题,Hive 默认使用 CombineHiveInputFormat,它可以在 Map 任务执行前将多个小文件合并成一个更大的分片,由一个 Map 任务处理,从而减少 Map 的总数。
-- 开启小文件合并(默认值,推荐)
-- CombineHiveInputFormat 会将多个小文件打包成一个分片,减少 Map 数量
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
-- 关闭小文件合并(不推荐调整,仅作演示)
-- HiveInputFormat 每个文件至少产生一个 Map
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
案例实操:
假设 ch4_t_par_emp 表的输入目录有3个文件。
-
默认开启合并(或文件本身较大),产生2个 Map
hive (default)>selectname,count(*) as cntfrom ds_hive.ch4_t_par_empgroup by name;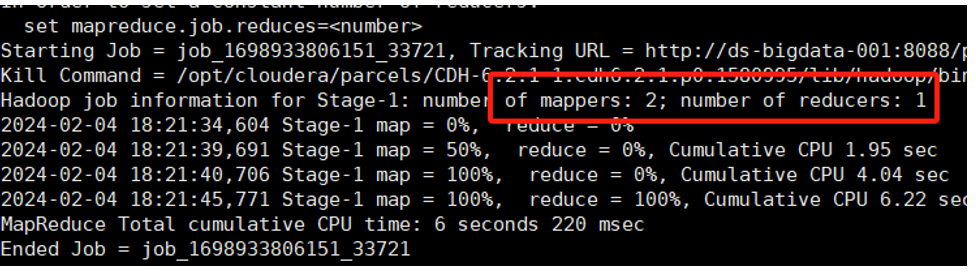
-
关闭合并,3个文件产生3个 Map
hive (default)>-- 关闭小文件合并大文件(仅作演示,不推荐调整)set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;selectname,count(*) as cntfrom ds_hive.ch4_t_par_empgroup by name;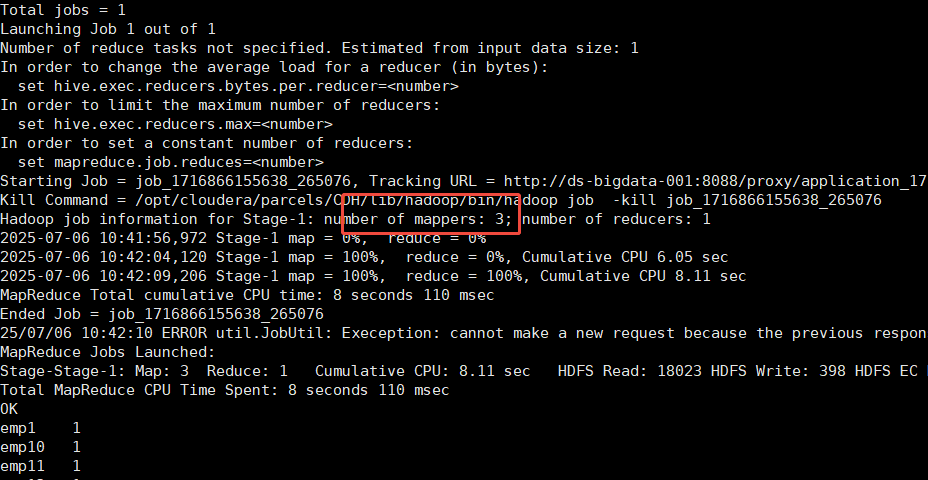
场景二:输出端小文件合并
如果 Map 或 Reduce 任务的输出结果也是大量小文件,这会对下游任务或 HDFS 造成压力。Hive 提供了在任务结束时自动合并输出小文件的功能。
-- 在 map-only 任务结束时合并小文件,默认 true
set hive.merge.mapfiles = true;
-- 在 map-reduce 任务结束时合并小文件,默认 false,建议设置为 true
set hive.merge.mapredfiles = true;
-- 每个合并任务最终生成的文件大小,默认 256MB
set hive.merge.size.per.task = 268435456;
-- 当输出文件的平均大小小于该值时,启动一个独立的 MapReduce Job 来合并文件
set hive.merge.smallfiles.avgsize = 16777216;
场景三:增加 Map 数,处理大文件
当输入文件巨大且 Map 任务的计算逻辑非常复杂时,单个 Map 任务可能会运行很长时间,成为性能瓶颈。此时,我们可以通过调整参数来增加 Map 数量,让每个 Map 处理更少的数据。
其原理是调整每个分片的最大尺寸(maxSize)。根据公式 splitSize = max(minSize, min(maxSize, blockSize)),当我们将 maxSize 设置得比 blockSize 还小时,一个大的数据块就会被切分成多个分片,从而产生更多的 Map 任务。
案例实操:
-
默认情况下,一个大文件块对应一个 Map(图中有两个块)
hive (default)>selectname,count(*) as cntfrom ds_hive.ch4_t_par_empgroup by name;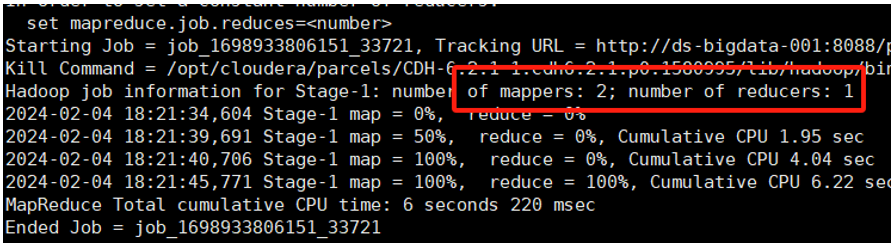
-
设置最大切片值为 200 字节,强制增加 Map 数
hive (default)>-- 将最大分片大小设为一个极小值,强制切分set mapreduce.input.fileinputformat.split.maxsize=200;selectname,count(*) as cntfrom ds_hive.ch4_t_par_empgroup by name;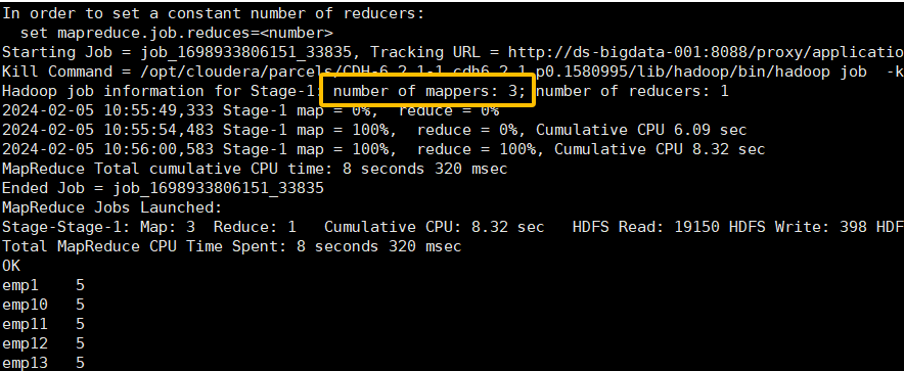
2. Reduce 数量的控制
Reduce 任务的数量直接影响作业的并发度和最终输出文件的数量。设置不当是导致性能问题的常见原因。
- Reduce 数太少:单个 Reduce 需要处理大量数据,可能导致任务运行缓慢、内存溢出,无法充分利用集群资源�。
- Reduce 数太多:大量 Reduce 任务的启动和初始化会消耗额外时间,并且会产生大量小文件,给 HDFS 带来压力。
Hive 提供了两种方式控制 Reduce 数量:
a) 自动计算(默认方式)
如果不手动指定 Reduce 数量,Hive 会根据以下参数自动估算:
hive.exec.reducers.bytes.per.reducer:每个 Reduce 任务处理的数据量,默认为 256MB。hive.exec.reducers.max:每个作业最多可以有多少个 Reduce 任务,默认为 1009。
计算公式为:Reducer数量 = min(最大Reduce数, 总输入数据量 / 每个Reduce处理的数据量)
即 N = min(hive.exec.reducers.max, totalInputBytes / hive.exec.reducers.bytes.per.reducer)
b) 手动指定
我们可以通过 mapreduce.job.reduces (在旧版本中为 mapred.reduce.tasks) 参数来直接设定 Reduce 的数量。该参数默认值为 -1,代表由 Hive 自动根据输入数据设置 Reduce 个数。
-- 手动设置 Reduce 任务的数量为 5
set mapreduce.job.reduces=5;
一般在生产中对 Reduce 的个数也不做太多调整,但是有时候自动计算出的 Reduce 个数太多,导致 HDFS 上的小文件泛滥。此时就可以通过调小 mapreduce.job.reduces 的个数,来减少 HDFS 上输出文件的个数。
Reduce 个数并不是越多越好。启动和初始化过多的 Reduce 会消耗时间和资源;另外,有多少个 Reduce,就会有多少个输出文件。如果生成了很多个小文件,而这些小文件又作为下一个任务的输入,则也会出现小文件过多的问题。
任务并行执行
对于一个复杂的 HiveQL 查询,Hive 会将其转化为一个由多个阶段(Stage)组成的有向无环图(DAG)。默认情况下,这些阶段是串行执行的。如果某些阶段之间没有依赖关系,就可以让它们并行执行,从而缩短总的查询时间。
hive.exec.parallel:是否开启任务并行执行。默认为false,设置为true开启。hive.exec.parallel.thread.number:最多可以并行执行的作业数,默认为 8。
案例实操:
以下查询包含两个没有相互依赖的子查询 t1 和 t2。
-
关闭并行运行(默认) 观察
EXPLAIN执行计划,可以看到 Stage-3 和 Stage-4 是串行执行的。-- 关闭并行运行, 默认是falseset hive.exec.parallel=false;explainSELECT t1.province_id,t1.cnt_1,t2.cnt_2from(select province_id,count(*) as cnt_1 from ds_hive.ch12_order_detail_orc group by province_id)t1left join(select province_id,count(*) as cnt_2 from ds_hive.ch12_order_detail_orc group by province_id) t2on t1.province_id=t2.province_idlimit 10;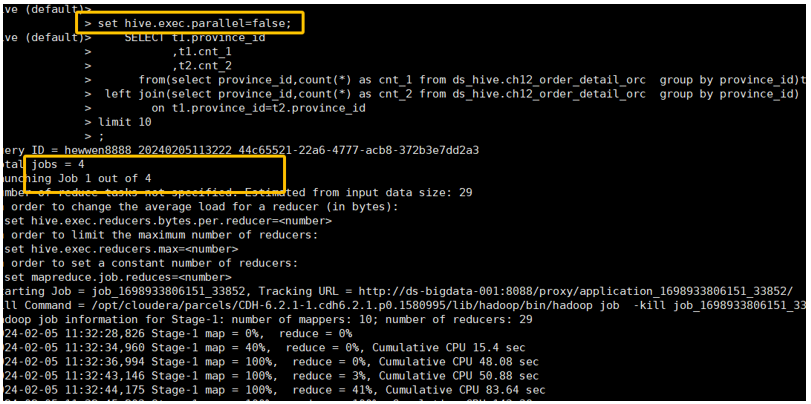
2. 开启并行运行
再次运行查询,观察任务的执行日志。可以看到 Hive 为这个查询启动了多个作业(Jobs),并且并行地提交了它们,这证明了没有依赖关系的子查询 t1 和 t2 正在同步执行。
-- 开启并行运行
set hive.exec.parallel=true;
SELECT t1.province_id
,t1.cnt_1
,t2.cnt_2
from(select province_id,count(*) as cnt_1 from ds_hive.ch12_order_detail_orc group by province_id)t1
left join(select province_id,count(*) as cnt_2 from ds_hive.ch12_order_detail_orc group by province_id) t2
on t1.province_id=t2.province_id
limit 10
;
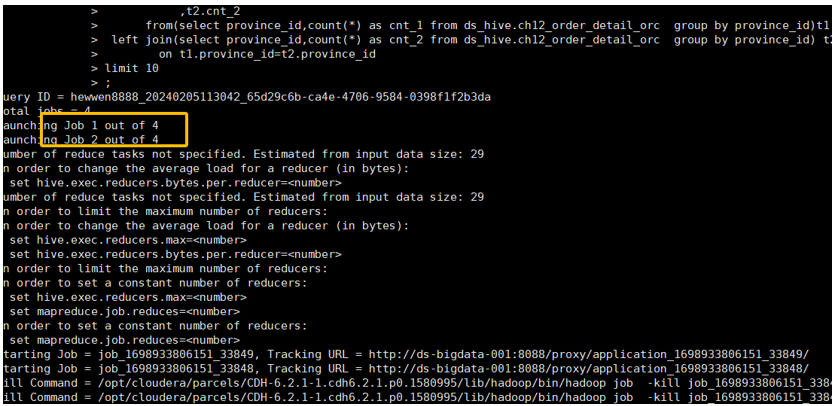
从上图的运行日志中,Launching Job 1 out of 4 和 Launching Job 2 out of 4 等信息清晰地表明,Hive 将查询拆分成了多个独立的作业,并同时提交执行,从而达到了并行的目的,有效缩短了整体查询时间。
Fetch 抓取:免 MapReduce 的快速通道
对于一些简单的查询,例如 SELECT * FROM table LIMIT 100,完全没有必要启动一个重量级的 MapReduce 任务。Hive 的 Fetch 抓取功能可以在这种场景下,直接从 HDFS 读取文件并返回结果,跳过 MapReduce 阶段,极大地提升查询速度。
-- 控制 Fetch 抓取的级别(是否在特定场景转换为 Fetch 任务)
-- none: 禁用 Fetch 抓取(不转换为 Fetch 任务)
-- minimal: 支持 SELECT *, 分区字段过滤, LIMIT
-- more: 支持 SELECT 任意字段, 函数, 过滤, LIMIT (默认值)
set hive.fetch.task.conversion=more;
需要注意的是,如果查询包含 GROUP BY、JOIN 等聚合或复杂操作,Hive 必须启动 MapReduce 任务,此时 Fetch 抓取不会生效。
本地模式:加速小数据量任务
当处理的数据量非常小时,启动分布式 MapReduce 任务的准备时间(资源申请、任务调度等)可能比实际计算时间还要长。在这种情况下,Hive 可以切换到本地模式,在单个节点上(通常是客户端或 HiveServer2 所在节点)直接执行任务,避免了与 YARN 的交互,从而加快小数据量任务的执行速度。
-- 开启自动转换为本地模式
set hive.exec.mode.local.auto=true;
-- 当输入数据量小于此值时,自动采用本地模式,默认为 128MB
set hive.exec.mode.local.auto.inputbytes.max=134217728;
-- 当输入文件个数小于此值时,自动采用本地模式,默认为 4
set hive.exec.mode.local.auto.input.files.max=4;
严格模式:规避高风险查询
为了防止用户执行一些可能导致性能问题或意外消耗大量资源的“危险”查询,Hive 提供了严格模式。开启严格模式后,以下几类查询将被禁止执行:
-
分区表查询不带分区过滤
- 参数:
hive.strict.checks.no.partition.filter=true - 原因:对分区表进行全表扫描通常会处理海量数据,消耗巨大资源。此设置强制用户在
WHERE子句中必须指定分区条件。
- 参数:
-
ORDER BY查询不带LIMIT- 参数:
hive.strict.checks.orderby.no.limit=true - 原因:
ORDER BY会将所有数据发送到单个 Reduce 任务进行全局排序。如果数据量巨大,这个 Reduce 会成为性能瓶颈并可能导致内存溢出。强制要求使用LIMIT可以有效减少进入 Reduce 的数据量。
- 参数:
-
笛卡尔积查询
- 参数:
hive.strict.checks.cartesian.product=true - 原因:当
JOIN查询缺少ON条件或使用了不恰当的WHERE条件时,会产生笛卡尔积,结果集的大小是两张表行数的乘积,极易导致任务失败。此设置会禁止此类查询。
- 参数:
CBO 优化:基于成本的智能决策
CBO (Cost-Based Optimizer) 是指基于成本的优化器。它会分析表和列的统计信息(如行数、数据分布等),估算一个 SQL 查询的多种可能执行计划的“成本”(综合考虑 CPU、IO、网络等),并选择成本最低的一个来执行。
在 Hive 中,CBO 最典型的应用场景是多表 Join 顺序的智能调整。
-- 开启 CBO 优化
set hive.cbo.enable=true;
-- 开启 CBO 后,还需要运行 ANALYZE TABLE 命令收集统计信息
ANALYZE TABLE table_name COMPUTE STATISTICS;
ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS;
总结
CBO 优化的核心价值在于智能调整 Join 顺序。例如,对于 SELECT ... FROM large_table l JOIN small_table s ON l.id = s.id 这个查询,如果没有 CBO,Hive 可能会按照 SQL 书写的顺序执行 Join。而开启 CBO 后,优化器会根据统计信息识别出 small_table 是小表,从而智能地将它放在 Join 的前面(例如,在 MapJoin 中作为广播表),这能极大地减少中间过程需要处理和 Shuffle 的数据量,从而提升查询性能。
Join 优化:MapJoin 的威力
在所有 Hive 优化技巧中,Join 优化,特别是 MapJoin 的使用,带来的性能提升最为显著。
优化说明
标准的 Join(Shuffle Join)需要将两张表的数据根据 Join Key 进行 Shuffle,分发到不同的 Reduce 任务中进行匹配。这个 Shuffle 过程涉及大量的磁盘 IO 和网络传输,开销巨大。
MapJoin 的原理则完全不同:它将其中一张小表完整地加载到所有 Map 任务的内存中。然后,在 Map 阶段,大表的每一行数据直接与内存中的小表数据进行 Join。这个过程完全避免了 Reduce 阶段和数据 Shuffle,性能通常能提升数倍甚至数十倍。
相关参数与使用
-- 开启 Hive 自动将普通 Join 转换为 MapJoin 的功能
set hive.auto.convert.join=true;
-- 定义多大的表可以被认为是“小表”并加载到内存中,默认 25MB
set hive.mapjoin.smalltable.filesize=25000000;
当 Hive 发现一个 Join 操作中,有一张表的大小小于 hive.mapjoin.smalltable.filesize 时,就会自动启用 MapJoin。
如果 Hive 没能自动转换,或者你想强制指定某张表为小表,可以使用 MAPJOIN Hint:
SELECT /*+ MAPJOIN(s) */
l.order_id,
l.amount,
s.store_name
FROM large_order_table l
JOIN small_store_table s ON l.store_id = s.id;
总结
Hive 性能调优是一个系统性工程,需要综合考虑数据、SQL 逻辑和集群资源。本文介绍的 Map/Reduce 数量控制、任务并行、Join 优化、本地模式、严格模式和 CBO 优化等都是日常工作中非常实用的调优手段。
在实践中,我们应遵循 “先优化数据(如存储格式、分区)和 SQL 逻辑,再调整系统参数” 的原则,并善用 EXPLAIN 命令分析执行计划,找到性能瓶颈,从而进行针对性优化。