行列互转 ⭐️⭐️⭐️
掌握 ⭐️⭐️⭐️
在数据处理和分析中,我们经常需要对数据的结构进行重塑,以满足不同的计算和展示需求。其中,“行转列” 与 “列转行” 是两种最常见且重要的数据转换操作。
- 列转行 (Column-to-Row):指将一行数据中的某个字段(通常是数组或Map类型)展开,生成多行数据。这在处理嵌套结构数据时非常有用。
- 行转列 (Row-to-Column):指将多行数据聚合到一行中,通常是将某个分类字段的不同值作为新的列。这常用于生成报表或数据透视表。
本文将通过具体的 Hive SQL 示例,深入讲解这两种操作的实现方法。
一、列转行:将一行数据拆分为多行
列转行,顾名思义,就是将一行数据拆分成多行。这种操作的核心是将一个包含多个值的单元格(如数组)“炸开”,并让其他列的数据与之对应重复。我们通常称这类函数为“炸裂函数”。
1.1 准备数据
首先,我们创建一张学生成绩表,其中科目和分数分别用数组(array)类型存储。
建表语句:
-----------建表
create table ds_hive.ch8_stu_score(
stu_id string
,sub_ids array<string>
,scores array<string>
)
stored as orc
;
-----插入数据
insert overwrite table ds_hive.ch8_stu_score
select 1001,array('语文', '数学', '英语'),array('90','88','79')
union all
select 1002,array('语文', '地理'),array('54','97')
union all
select 1003,array(null,null),array(null,null)
;
1.2 核心函数:explode 与 posexplode
Hive 提供了两个强大的函数来处理这类需求:explode 和 posexplode。
explode(array|map):该函数接收一个数组或Map作为输入,并为数组中的每个元素或Map中的每个键值对输出一行。posexplode(array):功能与explode类似,但它会额外输出元素在数组中的位置(索引),从0开始。
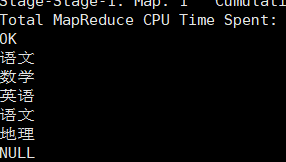
我们先用 explode 函数对学生科目列(sub_ids)进行展开:
select explode(sub_ids) as sub_id from ds_hive.ch8_stu_score;
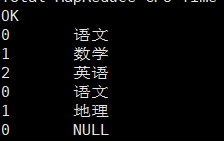
接着,我们使用 posexplode,可以看到它同时返回了元素的位置(itemIndex)和元素本身(item):
select posexplode(sub_ids) as (itemIndex, item) from ds_hive.ch8_stu_score;
运行结果:
注意: explode 这类表生成函数(UDTF)有一个重要的使用限制:不能与同一 SELECT 子句中的其他列一起使用。例如,以下查询会报错:
-- 这条SQL会执行失败
select stu_id, explode(sub_ids) as sub_id from ds_hive.ch8_stu_score;

为了解决这个问题,我们需要引入它的黄金搭档——Lateral View。
1.3 黄金搭档:Lateral View
Lateral View 用于配合表生成函数(如 explode),将函数生成的虚拟表与原始表的每一行进行连接(JOIN)。这样,我们就可以同时访问原始表的列和炸裂后产生的新列了。
语法: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias ...)
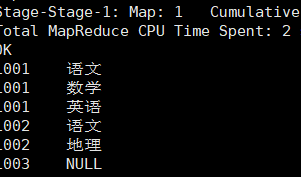
现在,我们结合 Lateral View 来获取学生ID和其对应的每一门科目:
select
stu_id
,tmp_table.sub_id
from ds_hive.ch8_stu_score
lateral view explode(sub_ids) tmp_table as sub_id;
1.4 综合实战:关联展开多个数组
需求: 将每个学生的科目和成绩一一对应,按行展示。
一个常见的错误是使用两次 lateral view explode,但这会产生笛卡尔积,而不是我们想要的一一对应关系。
-- 错误示例:产生笛卡尔积
select
stu_id
,tmp_table.sub_id
,tmp_score_table.score -- 增加了 score 列
from ds_hive.ch8_stu_score
lateral view explode(sub_ids) tmp_table as sub_id
lateral view explode(scores) tmp_score_table as score
;
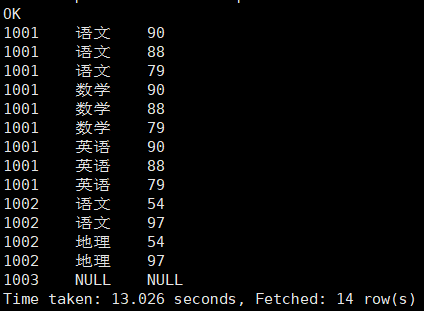 从结果可以看出,
从结果可以看出,sub_id 和 score 两列进行了笛卡尔积计算,这显然不是我们期望的结果。
正确思路: 我们需要利用数组中元素的位置来建立科目和成绩的对应关系。这正是 posexplode 的用武之地。我们可以分别对 sub_ids 和 scores 使用 posexplode,然后通过限定它们的索引相等,来确保数据的一一对应。
正确实现:
select
stu_id
,sub_id
,score
from ds_hive.ch8_stu_score
lateral view posexplode(sub_ids) tmp_sub as sub_idx,sub_id
lateral view posexplode(scores) tmp_sc as sc_idx,score
where sub_idx=sc_idx
;
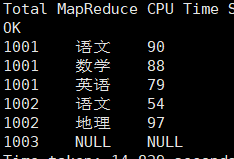 这样,我们就完美地实现了需求。
这样,我们就完美地实现了需求。
二、行转列:将多行数据聚合为一行
行转列是列转行的逆操作,它将多行数据聚合到一行中,通常用于数据汇总和透视。
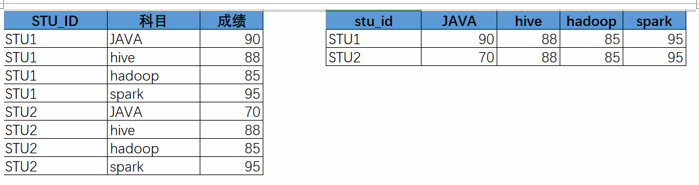
2.1 准备数据
为了演示行转列,我们先使用上一节得到的结果创建一张新的明细表。
建表语句:
create table ds_hive.ch8_stu_score_01
as
select
stu_id
,sub_id
,score
from ds_hive.ch8_stu_score
lateral view posexplode(sub_ids) tmp_sub as sub_idx,sub_id
lateral view posexplode(scores) tmp_sc as sc_idx,score
where sub_idx=sc_idx
;
为了更好地展示去重效果,我们向表中插入一份重复数据。
insert into table ds_hive.ch8_stu_score_01
select
stu_id
,sub_id
,score
from ds_hive.ch8_stu_score
lateral view posexplode(sub_ids) tmp_sub as sub_idx,sub_id
lateral view posexplode(scores) tmp_sc as sc_idx,score
where sub_idx=sc_idx
;
2.2 方法一:使用聚合函数
Hive 提供了几个强大的聚合函数来实现行转列,常用于将分组后的多行数据合并到一个字段中。
collect_list(col):将分组内的某列值收集起来,返回一个包含重复元素的数组。collect_set(col):将分组内的某列值收集起来,返回一个包含唯一元素的数组(自动去重)。concat_ws(sep, array|str1, str2, ...):使用指定的分隔符将数组或多个字符串连接成一个单一的字符串。sort_array(array):对数组进行排序。根据数组元素的自然顺序,将输入数组排序为升序或降序。对于double/float类型,NaN值大于任何非NaN元素。在升序排序中,空元素将被放置在返回数组的开头;在降序排序中,空元素将被放置在返回数组的末尾。
注意:**
collect_list(col)和collect_set(col)**函数是非确定性的,因为收集结果的顺序取决于行的顺序,这在经过shuffle之后可能是不确定的。
示例: 按学生ID分组,收集其所有科目。
select
stu_id
,collect_list(sub_id) as sub_ids1 -- 收集所有科目(含重复)
,collect_set(sub_id) as sub_ids2 -- 收集所有科目(去重)
,sort_array(collect_set(sub_id)) as sub_ids3 -- 去重后排序
,concat_ws(',',collect_set(sub_id)) as sub_ids4 -- 去重后用逗号拼接成字符串
from ds_hive.ch8_stu_score_01
group by stu_id
;
结果:

2.3 方法二:使用 CASE WHEN 实现数据透视
当我们需要将某个分类字段的不同值作为新表的列名时(即数据透视),CASE WHEN 结合聚合函数(如 SUM 或 MAX)是最佳选择。
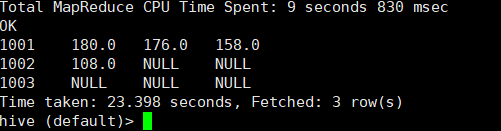
需求: 将学生成绩的竖表(每个学生每科成绩占一行)转换为横表,每个学生占一行,列为语文、数学、英语等科目分数。
select
stu_id,
max(case when sub_id = '语文' then score end) as yuwen,
max(case when sub_id = '数学' then score end) as shuxue,
max(case when sub_id = '英语' then score end) as yingyu
from ds_hive.ch8_stu_score_01
group by stu_id
;
提示:这里使用
SUM或MAX都可以,因为在GROUP BY stu_id后,每个学生对应的每个科目只有一行数据,聚合函数只作用于单个值。
三、总结
本文详细探讨了 Hive SQL 中两种关键的数据重塑技术:
- 列转行:核心是使用
explode或posexplode函数,并通常需要配合Lateral View来将数组或Map字段展开为多行,同时保留原始行的其他字段信息。 - 行转列:主要有两种方法。一是使用
collect_list/collect_set等聚合函数将多行信息合并到数组或字符串中;二是利用CASE WHEN结合GROUP BY实现经典的数据透视表功能。
熟练掌握这两种操作,将极大提升数据清洗、特征工程和报表制作等场景下的数据处理能力。