Hive底层执行原理 ⭐️⭐️
重点记忆 ⭐️⭐️
0. 面试回答版 ⭐️⭐️
好的,面试官。
很高兴能有机会向您阐述一下我对 Hive 执行基本流程的理解。我会从一个 SQL 查询的提交开始,到最终结果的返回,分步骤地进行说明。
总的来说,Hive 的执行流程本质上是一个 翻译 过程:它将我们写的、类似 SQL 的 HiveQL 语言,翻译成底层的计算引擎(如 MapReduce、Tez 或 Spark)可以执行的、分布式的计算任务。
这个“翻译”和执行的过程,可以分为以下几个核心阶段:
Hive 执行流程详解 (Step-by-Step)
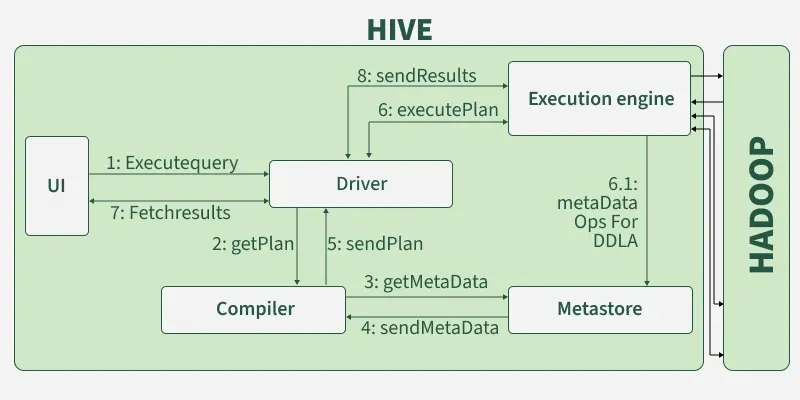
第 1 步:UI 层 - 提交查询 (Query Submission)
用户通过客户端(如 Hive CLI、Beeline、Hue、JDBC/ODBC 接口等)提交一条 HiveQL 查询语句。
第 2 步:Driver - 驱动和管理 (Orchestration)
查询语句会首先被发送到 Driver 模块。Driver 是整个流程的“总指挥”,它负责接收查询,并调用后续的组件来完成整个执行过程。
第 3 步:Compiler - 编译和优化 (Compilation & Optimization)
这是整个流程中最核心、最复杂的部分。Driver 会将查询语句交给 Compiler(编译器)处理。编译过程又可以细分为以下几个子步骤:
-
Parser (解析器)
- 作用:进行词法和语法分析。
- 输入:HiveQL 查询字符串。
- 输出:抽象语法树 (Abstract Syntax Tree, AST)。
- 说明:这个阶段会检查 SQL 的语法是否正确,比如
SELECT、FROM、WHERE等关键字是否拼写正确,语句结构是否符合规范。然后将 SQL 语句转换成一个树形结构,方便后续处理。
-
Semantic Analyzer (语义分析器)
- 作用:进行语义校验和元数据绑定。
- 输入:AST。
- 输出:查询块 (Query Block, QB)。
- 说明:这是非常关键的一步。语义分析器会访问 Metastore,获取表、分区、列名、列类型等元数据信息。然后用这些信息来验证 AST:
- 检查表和视图是否存在。
- 检查列名是否正确。
- 检查数据类型是否匹配(例如,WHERE 子句中的比较)。
- 将表达式中的
*替换为所有具体的列名。
-
Logical Plan Generator (逻辑计划生成器)
- 作用:将查询块转换为�逻辑计划。
- 输入:查询块 (QB)。
- 输出:逻辑计划 (Logical Plan)。
- 说明:逻辑计划是一个由逻辑操作符(如 Scan, Filter, Join, GroupBy, Limit)组成的树状结构。它描述了需要“做什么”,但还不关心“怎么做”。例如,它只定义了“需要对 A 表和 B 表进行连接”,但没有决定是使用 Map Join 还是 Shuffle Join。
-
Optimizer (优化器)
- 作用:对逻辑计划进行优化。
- 输入:逻辑计划。
- 输出:优化后的逻辑计划。
- 说明:优化器会应用一系列优化规则,对逻辑计划进行重写,目的是减少数据量、降低计算复杂度,提升执行效率。常见的优化规则包括:
- 列剪裁 (Column Pruning):只读取查询中真正需要的列,丢弃不需要的列。
- 分区剪裁 (Partition Pruning):如果表是分区的,根据 WHERE 条件只扫描相关的分区,避免全表扫描。
- 谓词下推 (Predicate Pushdown):将
WHERE或ON中的过滤条件尽可能早地执行,在数据读取阶段就进行过滤,从而减少后续处理的数据量。 - Join 优化:比如自动选择更高效的 Map Join 来替代 Shuffle Join。
第 4 步:Physical Plan Generator - 生成物理计划 (Physical Plan Generation)
- 作用:将优化后的逻辑计划翻译成具体的、可执行的物理计划。
- 输入:优化后的逻辑计划。
- 输出:物理计划 (Physical Plan)。
- 说明:物理计划是一个由一系列物理操作符组成的有向无环图 (DAG)。这个计划是与具体的计算引擎强相关的。
- 如果引擎是 MapReduce,物理计划会被翻译成一系列相互依赖的 MapReduce Job。
- 如果引擎是 Tez 或 Spark,物理计划会被翻译成一个更灵活的、由 Vertex (顶点) 和 Edge (边) 组成的 DAG 任务。这通常比 MapReduce 的多阶段 Job 模式效率更高。
第 5 步:Execution Engine - 执行任务 (Task Execution)
- 作用:将物理计划提交到集群中执行。
- 输入:物理计划 (DAG of tasks)。
- 输出:计算结果。
- 说明:
- Driver 将物理计划提交给选定的执行引擎(如 MapReduce, Tez, Spark)。
- 执行引擎与 YARN (集群资源管理器) 交互,申请计算资源(Container)。
- YARN 分配资源后,执行引擎会在集群的各个节点上启动计算任务(如 Map Task, Reduce Task)。
- 任务在执行过程中,会从 HDFS 或其他存储系统上读取数据,进行计算,并将中间结果和最终结果写回 HDFS。
第 6 步:Fetch Results - 获取并返回结果
- 当所有任务执行完毕后,结果会临时存储在 HDFS 的指定位置。
- Driver 会从 HDFS 上获取这些结果。
- 最后,通过 UI 层将查询结果返回给用户。
总结与核心组件
总结一下这个流程中的几个核心组件:
- Driver:整个流程的协调者和控制器。
- Metastore:元数据中心。存储了所有表、分区、列的结构信息和数据存储位置。Compiler 阶段严重依赖它。
- Compiler:Hive 的“大脑”,负责将 HiveQL 翻译和优化成可执行的计划。
- Execution Engine:Hive 的“四肢”,负责在集群上实际执行计算任务。Hive 本身不进行计算,而是委托给这些引擎。
1. HiveHQL编译过程(⭐️了解即可)
编译HQL 的任务是在上节中介绍的 COMPILER(编译器组件)中完成的。Hive将SQL转化为MapReduce任务,整个编译过程分为六个阶段:
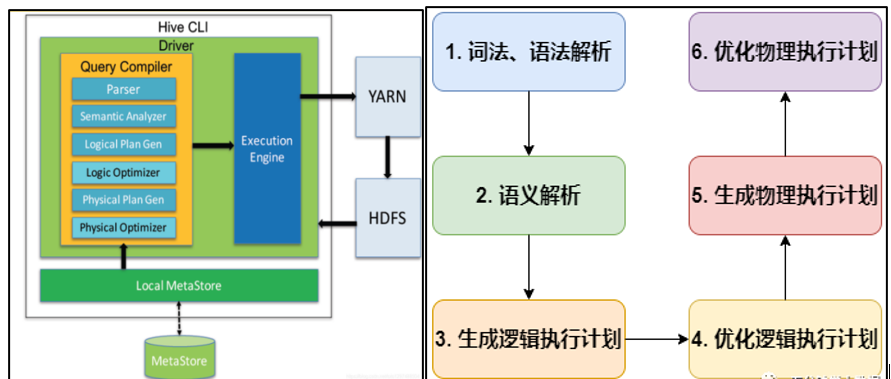
【阶段1】词法、语法解析: Antlr 定义HQL 的语法规则,完成HQL 词法,语法解析,将HQL 转化为抽象语法树 AST Tree;
【阶段2】语义解析: 遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
【阶段3】生成逻辑执行计划: 遍历 QueryBlock,翻译为执行操作树OperatorTree;
【阶段4】优化逻辑执行计划: 逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少MapReduce Job,减少数据传输及 shuffle 数据量;
【阶段5】生成物理执行计划: 遍历 OperatorTree,翻译为 MapReduce 任务;
【阶段6】优化物理执行计划: 物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
2. Hive SQL编译举例(了解即可)
下面对这六个阶段详细解析:
为便于理解,我们拿一个简单的查询语句进行展示,对5月23号的员工维表(该表包括员工号id、部门名称dept、薪水salary等字段)进行查询:
select * from dim.dim_emp where dt = '2021-05-23';
阶段一:词法、语法解析:根据Antlr定义的sql语法规则,将相关sql进行词法、语法解析,转化为抽象语法树AST Tree:
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
dim
dim_emp
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_ALLCOLREF
TOK_WHERE
=
TOK_TABLE_OR_COL
dt
'2021-05-23'
更具体地讲,SQL输入是个字符串,Hive需要先把字符串分解成自己能明白的结构,用到的工具就是解析器生成器Antlr,该工具产生解析代码、生成AST抽象语法树。
补充说明:AST的好处是,你不再纠结于Token的解析和排列问题,你只需要在一个固定结构的树上抽取信息,比如SELECT根节点下你必然能找到SELECT_EXPR子节点(就是Projection部分的信息)。
阶段二:语义解析:遍历AST Tree,抽象出查询的基本组成单元QueryBlock:
遍历完整个AST,Hive把它关心的信息分类组织排列到一个结构中,但是还没有进行元信息绑定和检查整理,而这个绑定整理的过程叫Semantics Analyze(语义分析)。
这里首先需要从Hive元数据库中查询到相关的元信息。对上面的查询,Hive知道了用户希望从emp表中查询数据,那么Hive调用MetastoreClient接口,从Metadata Service中抽取了emp表的元信息,所谓元信息最基本地包含了表的schema,比如id是Integer类型,dept是string类型,这些信息都会注入本次之行Hive的符号解析空间,同时被注入的�符号还有内建函数(比如我们用的sum)和UDF等等。
AST Tree生成后由于其复杂度依旧较高,不便于翻译为mapreduce程序,需要进行进一步抽象和结构化,形成QueryBlock。QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个QueryBlock就是一个子查询。
阶段三:生成逻辑执行计划:遍历QueryBlock,翻译为执行操作树OperatorTree:
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。基本的操作符包括:
TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator
ReduceSinkOperator。
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。
由于Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce Key/value, Partition Key。
逻辑执行计划可以简单地认为就是,按照顺序在单机上跑是能跑出结果的一个计算计划。
阶段四:优化逻辑执行计划
Hive中的逻辑查询优化可以大致分为以下几类:
投影修剪;推导传递谓词;谓词下推;将Select-Select,Filter-Filter合并为单个操作;多路 Join;查询重写以适应某些列值的Join倾斜。
阶段五:生成物理执行计划
生成物理执行计划即是将逻辑执行计划生成的OperatorTree转化为MapReduce Job的过程,主要分为下面几个阶段:
1.对输出表生成MoveTask,它的作用是将运行SQL生成的MapReduce任务结果文件放到SQL中指定的存储查询结果的路径中
2.从OperatorTree的其中一个根节点向下深度优先遍历
3.ReduceSinkOperator标示Map/Reduce的界限,多个Job间的界限
4.遍历其他根节点,遇过碰到JoinOperator合并MapReduceTask
5.生成StatTask更新元数据
6.剪断Map与Reduce间的Operator的关系
阶段六:优化物理执行计划
Hive中的物理优化可以大致分为以下几类:
1.分区修剪(Partition Pruning)
2.基于分区和桶的扫描修剪(Scan pruning)
3.如果查询基于抽样,则扫描修剪
4.在某些情况下,在map端应用 Group By
5.在 mapper上执行Join
6.优化Union,使Union只在map端执行
7.在多路 Join 中,根据用户提示决定最后留哪个表
8.删除不必要的ReduceSinkOperators
9.对于带有Limit子句的查询,减少需要为该表扫描的文件数
10.对于带有Limit子句的查询,通过限制 ReduceSinkOperator 生成的内容来限制来自mapper的输出
11.减少用户提交的SQL查询所需的Tez作业数量
12.如果是简单的提取查询,避免使用MapReduce作业
经过以上六个阶段,SQL 就被解析映射成了集群上的 MapReduce 任务。
第一章节我们介绍了hive整体架构,这整个架构之间也有一些列的工作流程。hive通过给用户提供的一系列交互接口,接收到的用户的指令(SQl),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口中。
3. 执行基本流程(⭐️⭐️重点记忆)
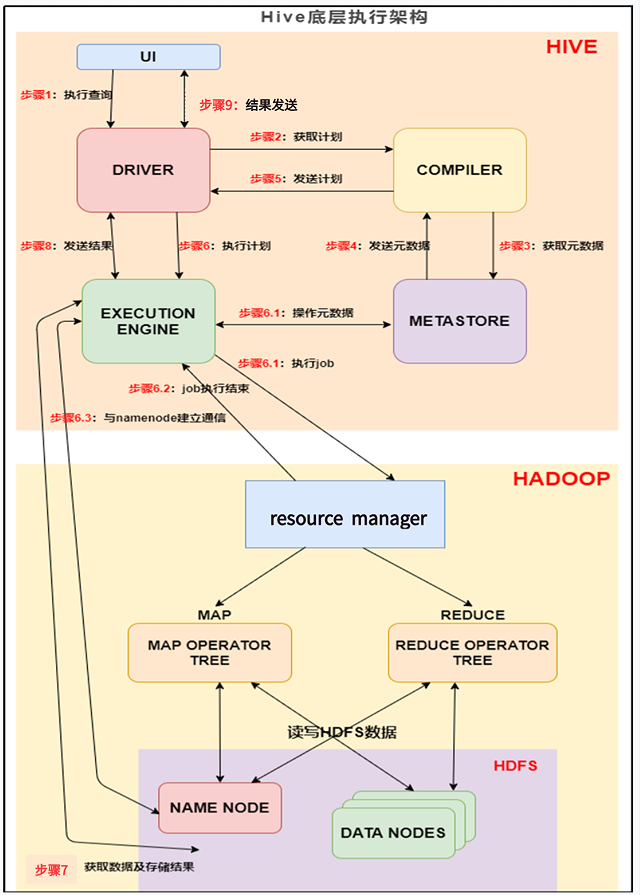
上图的基本流程是:
步骤1:界面如命令行或Web UI将查询发送到Driver(任何数据库驱动程序如JDBC、ODBC,等等)来执行。
步骤2:DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER(编译器)生成执行计划;
步骤3和4:编译器从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
步骤5:编译器生成的计划是分阶段的DAG,每个阶段要么是 map/reduce 作业,要么是一个元数据或者HDFS上的操作。将生成的计划发给 DRIVER。
如果是map/reduce作业,该计划包括map operator trees和一个reduce operator tree,执行引擎将会把这些作业发送给 MapReduce。
步骤6、6.1、6.2和6.3:执行引擎将这些阶段提交给适当的组件。在每个 task(mapper/reducer) 中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时HDFS文件中(如果不需要 reduce 阶段,则在 map 中操作)。临时文件用于向计划中后面的 map/reduce 阶段提供数据。
步骤7:执行引擎接收数据节点(data node)的结果
步骤8:执行引擎发送这些合成值到Driver
步骤9:Driver将结果发送到hive接口
最终的临时文件将移动到表的位置,对于用户的查询,临时文件的内容由执行引擎直接从HDFS读取,然后通过Driver发送到UI。