排序与分区详解 ⭐️⭐️⭐️
掌握 ⭐️⭐️⭐️
在处理海量数据时,排序是最高频的操作之一。Hive 提供了多种排序和分区的方式,如 ORDER BY, SORT BY, DISTRIBUTE BY 和 CLUSTER BY。它们看似功能相似,但在底层实现原理和性能上却有天壤之别。
本文将深入阐述 Hive 的排序与分区机制,并讲解如何根据不同场景选择最合适的策略,写出高效的排序查询。
1 全局排序(Order By):精确但昂贵
ORDER BY 是最直观的排序方式,它能保证输出结果是全局有序的。但为了实现这一目标,Hive会采取一个“简单粗暴”的策略:将所有数据强制发送到同一个Reducer任务中进行处理。
这意味着,即使通过 set mapreduce.job.reduces=N; 设置了多个 Reducer,ORDER BY 也会忽略该参数,最终只启动一个 Reducer。这也是为什么在数据量大时,ORDER BY 效率极低的核心原因——单点瓶颈。
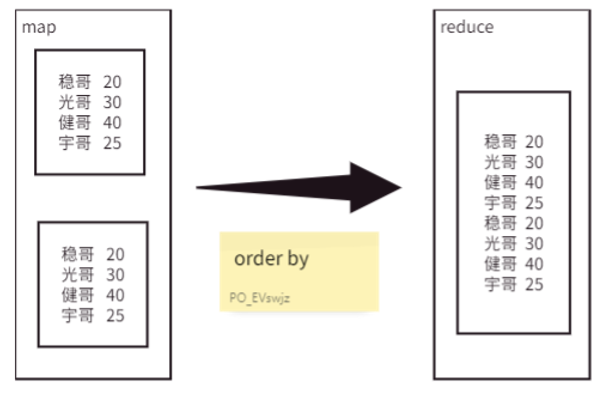
缺点:当数据量特别大时,单一Reducer的处理能力有限,会导致查询极其缓慢或因内存溢出而失败。
注意:在Hive的严格模式 (
set hive.mapred.mode = strict)下,使用ORDER BY必须配合LIMIT子句,否则会报错。这是为了防止用户无意中触发大规模数据的全局排序,导致集群资源被耗尽。
语法:ORDER BY 子句位于 SELECT 语句的末尾。默认按升序(ASC)排列,可通过 DESC 关键字指定为降序。
基础案例实操
(1)按类别名称升序(默认)
查询每个类别中的商品数,并按类别名称的字典序升序排列。
hive (default)>
set mapreduce.job.reduces=3; -- 该设置对 ORDER BY 无效
select
category,
count(*) as order_cnt
from ds_hive.ch6_t_goods
group by category
order by category
LIMIT 10;
(2)按类别名称降序
使用 DESC 关键字实现降序排列。
hive (default)>
select
category,
count(*) as order_cnt
from ds_hive.ch6_t_goods
group by category
order by category desc;
(3)按聚合结果(别名)排序
你也可以根据聚合函数计算出的结果列(如此处的 order_cnt)进行排序。
hive (default)>
select
category,
count(*) as order_cnt
from ds_hive.ch6_t_goods
group by category
order by order_cnt;
(4)多字段组合排序
支持按多个字段排序,排序优先级从左到右。下例中,先按类别降序,类别相同时再按商品数量升序。
hive (default)>
select
category,
count(*) as order_cnt
from ds_hive.ch6_t_goods
group by category
order by category DESC, order_cnt ASC;
2 Reducer内部排序(Sort By):局部有序,全局无序
当全局排序的性能瓶颈无法接受时,SORT BY 便登场了。它执行的是局部排序,即在每个 Reducer 内部对数据进行排序。
SORT BY 会尊重你设置的 Reducer 数量。最终的输出结果在整体上是无序的,但如果你查看每个 Reducer 的输出文件,会发现文件内部的数据是有序的。这是一种局部有序,全局无序的状态,非常适合作为后续处理的中间步骤。
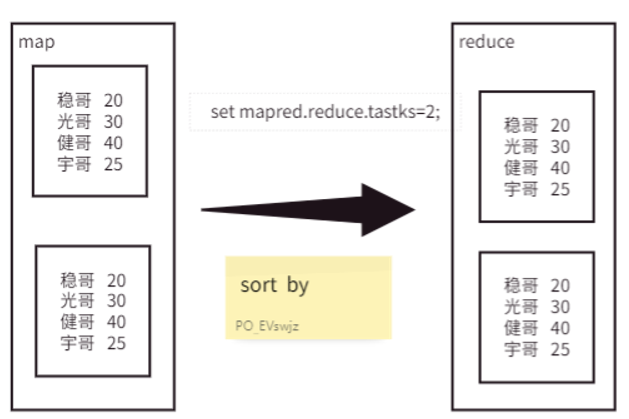
案例实操
为了对比 ORDER BY 和 SORT BY 的差异,我们可以创建两张表�来观察结果。
-
设置 Reducer 数量
hive (default)> set mapreduce.job.reduces=3; -
查看 Reducer 数量
hive (default)> set mapreduce.job.reduces;-- mapreduce.job.reduces=3 -
分别使用 ORDER BY 和 SORT BY 创建表
-- 使用 ORDER BY,所有数据进入一个Reducer,结果全局有序CREATE TABLE if not exists ds_hive.ch6_t_emp_orderasselectId, category, pricefrom ds_hive.ch6_t_goodsorder by cast(price as int);-- 使用 SORT BY,数据进入3个Reducer,每个Reducer内部有序CREATE TABLE if not exists ds_hive.ch6_t_emp_sortasselect *from ds_hive.ch6_t_goodssort by cast(price as int);执行后,你可以去HDFS上查看这两张表对应的文件。
ch6_t_emp_order目录下通常只有一个文件,其内容是全局按价格排序的。而ch6_t_emp_sort目录下会有3个文件,每个文件内部按价格排序,但文件之间的数据范围可能会重叠。
3 分区(Distribute By):数据路由的指挥官
DISTRIBUTE BY 并不进行排序,它的核心功能是控制 Map 阶段的输出数据如何分区(Partition)并发送到 Reducer 节点。它就像一个交通指挥员,决定了数据流向。
默认情况下,Hive 使用哈希函数对数据进行随机分发,但使用 DISTRIBUTE BY 可以保证相同 KEY 的记录会被发送到同一个 Reducer 中。这对于需要按特定字段进行后续聚合或排序的场景至关重要。
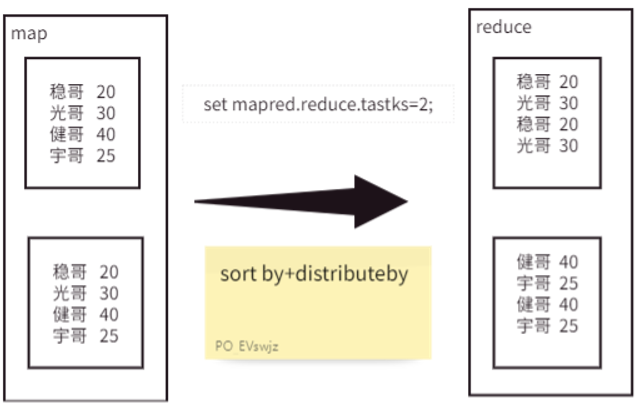
重要:要观察
DISTRIBUTE BY的效果,必须设置多个 Reducer (set mapreduce.job.reduces > 1;)。
案例实操:分区后局部排序
这是一个非常经典的组合:先按类别分区,再在每个分区(Reducer)内部按价格排序。
hive (default)> set mapreduce.job.reduces=3;
select *
from ds_hive.ch6_t_goods
distribute by category
sort by cast(price as int);
执行效果分析:
-
distribute by 前:数据可能被随机分配到不同的Reducer,导致同一个Reducer可能处理来自不同
category的数据。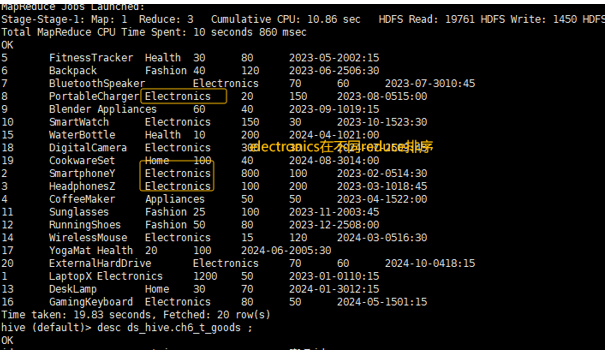
-
distribute by 后:通过
distribute by category,所有相同category的数据都被精准地发送到了同一个Reducer中。结合sort by price,最终的输出文件中,每个文件只包含特定几个类别的数据,并且文件内部是按价格排序的。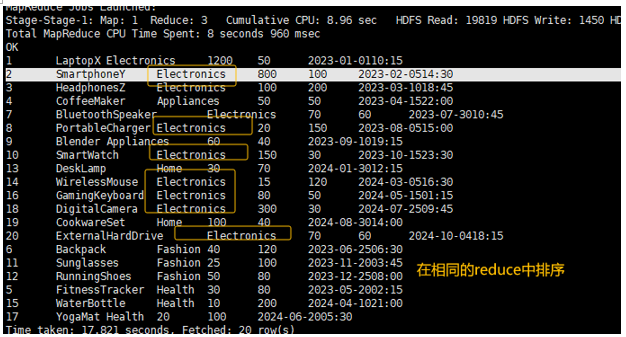
注意:
DISTRIBUTE BY的分区规则是根据分区字段的哈希值对 Reducer 数量取模,余数相同的记录会被分到同一个 Reducer。- Hive 语法要求
DISTRIBUTE BY子句必须写��在SORT BY子句之前。
4 分区排序(Cluster By):DISTRIBUTE BY + SORT BY 的简写
CLUSTER BY 可以看作是 DISTRIBUTE BY 和 SORT BY 的一个便捷组合,但它有一个限制:分区字段和排序字段必须是同一个,并且只能是升序排序。
换句话说,cluster by column 等价于 distribute by column sort by column。
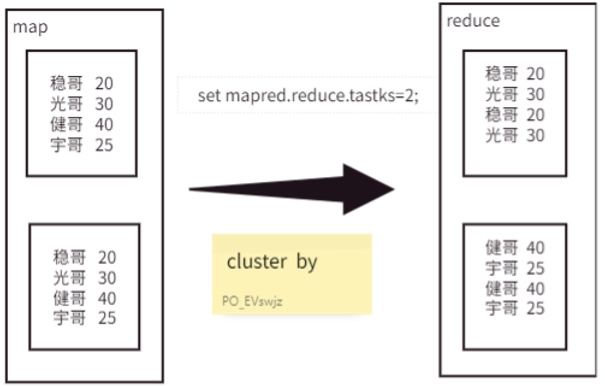
以下两种写法是完全等价的:
hive (default)>
select *
from ds_hive.ch6_t_goods
cluster by category;
等价于:
hive (default)>
select *
from ds_hive.ch6_t_goods
distribute by category
sort by category;
由于不能指定排序规则(ASC/DESC),CLUSTER BY 的使用场景相对有限。
终极优化:用 DISTRIBUTE BY + SORT BY 高效实现全局排序
现在,让我们运用所学知识来优化一个常见的性能问题:对大数据集进行全局排序取 Top-N。
场景:获取价格最高的前10000个商品
常规但低效的方法:直接使用 ORDER BY
-- 这个查询会将所有数据发送到一个Reducer,当数据量巨大时,会非常缓慢甚至失败。
select *
from ds_hive.ch6_t_goods
order by cast(price as int) desc
limit 10000;
优化版本:采用“分而治之”的策略
我们可以利用 DISTRIBUTE BY 和 SORT BY �先在每个 Reducer 中进行局部排序,然后再对这些已经部分有序的结果进行最终的全局排序。
-- 优化版本
set mapreduce.job.reduces=10; -- 假设我们启动10个Reducer
select
*
from
(
-- 内层查询:在每个Reducer内部进行局部排序
select *
from ds_hive.ch6_t_goods
-- distribute by rand() 可以将数据随机均匀地分发到Reducer,避免数据倾斜
distribute by cast(rand() * 10 as int)
sort by cast(price as int) desc
) t1
-- 外层查询:对局部排序的结果进行最终的全局排序
order by cast(price as int) desc
limit 10000;
注:这里的 distribute by 使用了一个随机函数,目的是将数据均匀打散到各个Reducer,以实现并行处理。如果按 category 分区,可能会导致某些商品类别多的Reducer负载过重。
优化原理:
- 内层查询:将排序任务分散到多个 Reducer 上并行执行,每个 Reducer 只需处理一部分数据并对其进行排序。
- 外层查询:接收来自内层查询的、已经局部有序的数据流。此时,最终排序的Reducer节点的工作量大大减少,因为它处理的是“部分有序”的数据,而不是杂乱无章的原始数据。
通过这种方式,我们将一个巨大的单点排序任务,分解成了多个并行的局部排序任务和一个轻量级的最终合并排序任务,极大地提升了查询性能和稳定性。
总结
为了方便回顾和比较,下表总结了这四个关键字的核心区别:
| 特性 | ORDER BY | SORT BY | DISTRIBUTE BY | CLUSTER BY |
|---|---|---|---|---|
| 作用范围 | 全局排序 | Reducer 内部排序 | 数据分区 | 分区 + Reducer 内部排序 |
| Reducer 数量 | 强制为 1 | 可指定多个 | 可指定多个 | 可指定多个 |
| 性能 | 数据量大时极慢 | 较快 | - | 较快 |
| 排序规则 | 可指定 ASC/DESC | 可指定 ASC/DESC | 无排序功能 | 只能升序 |
| 典型用途 | 对最终结果全局排序 | 结合 DISTRIBUTE BY | 控制数据流向,保证相同Key进入同一Reducer | DISTRIBUTE BY 和 SORT BY 字段相同时的简写 |