Hive 执行计划 ⭐️⭐️⭐️
重中之重 ⭐️⭐️⭐️
在数据处理领域,性能优化是一个永恒的话题。每个人或许都有自己的方法论,但归根结底,常见的优化可以归纳为四个层面:存储、模型、SQL 和集群资源。
这里给大家提供一种系统性的优化思路:
- 发现问题:从定位性能瓶颈开始,例如识别数据倾斜、数据扫描量过大等问题。
- SQL 优化:在 SQL 层面进行逻辑改写、调整算子顺序等,这是最直接有效的优化手段。
- 资源优化:调整集群资源配置或相关参数,为查询提供合适的运行环境。
- 模型优化:最后,如果上述优化仍无法满足要求,再考虑对数据模型或业务逻辑进行重构。
要有效落地这套方法论,尤其是前两步——“发现问题”和“SQL 优化”,我们必须学会使用一个强大的诊断工具:EXPLAIN 执行计划。本文将深入探讨如何通过解读 EXPLAIN 来洞察 Hive 查询的内部机制,从而找到性能瓶颈,指导我们进行精准优化。
什么是执行计划
所谓执行计划(Execution Plan),顾名思义,就是 Hive 对一个查询任务(SQL),制定出的一份如何完成任务的详细方案。
举个生活中的例子:我从上海要去新疆,可以选择坐飞机、高铁、火车,甚至自驾。具体到线路更是五花八门。现在我准备选择自驾,那么具体走什么路线才能最划算(时间 & 费用),这是一件值得考究的事情。
在这个比喻中,Hive 就是我们的自驾工具,而 EXPLAIN 命令则能展示出 Hive 为我们规划好的“行车路线”。这份执行计划对于我们了解底层原理、进行 Hive 调优、排查数据倾斜等问题至关重要。
执行计划的核心构成:Stage 与 Operator
EXPLAIN 呈现的执行计划,由一系列具有依赖关系的 Stage 组成。这些 Stage 可以并行执行(如果没有依赖关系),也可以串行执行。
- Stage�:代表查询执行过程中的一个阶段。每个
Stage通常对应一个 MapReduce Job,或者一个文件系统操作(如数据移动),或是一个抽样、Limit 等本地任务。 - Operator:
Stage内部的计算逻辑由一个Operator Tree(算子树)来描述。一个Operator代表 Map 或 Reduce 阶段的一个单一逻辑操作,例如表扫描(TableScan)、过滤(Filter)、连接(Join)等。数据的处理流程就是数据在算子树中从一个节点流向另一个节点的过程。
Stage 的理解与划分
在一个查询任务中,根据 SQL 的复杂程度,会有一个或多个 Stage。理解 Stage 的划分机制是读懂执行计划的关键。
何时划分 Stage?
简单来说,Hive 划分 Stage 的核心原则是数据重分区(Shuffle)。每当遇到需要进行大规模数据混洗的操作时,比如 GROUP BY、JOIN(非 MapJoin)、DISTINCT、ORDER BY 等,Hive 就会插入一个 ReduceSinkOperator。这标志着一个 Map 阶段的结束和下一个 Reduce 阶段的开始,从而形成一个新的 Stage。没有 Shuffle 的操作链(如 TableScan -> Filter -> Select)通常可以在一个 Stage 内完成。
详细划分规则 (以 MR 引擎为例):
以下是 Hive 编译器根据算子树生成物理计划(TaskTree)时划分 Stage 的一些内部规则,供进阶用户参考:
- R1:
TS%----> 生成 MapRedTask 对象,确定 MapWork。 - R2:
TS%.*RS—> 遇到第一个ReduceSinkOperator,划分 Map 阶段,确定 ReduceWork。 - R3:
RS%.*RS%----> 遇到后续的ReduceSinkOperator,生成新的 MapRedTask,切分出新的 Job。 - R4:
FS%----> 连接 MapRedTask 和 MoveTask。 - R5:
UNION%----> 如果所有子查询都是 map-only,则把所有的 MapWork 进行合并连接。 - R6:
UNION%.*RS%—> 遇到ReduceSinkOperator,则合并 Stage。 - R7:
MAPJOIN%----> MapJoin 通常在一个 Stage 内完成,不产生新的 Stage。
常见 Operator
理解了 Stage,我们再来看看构成 Stage 的基本单元——Operator。
- TableScan:表扫描操作。
alias:表名称。
- Select Operator:列选择操作。
expressions:需要的字段名称及字段类型。outputColumnNames:输出的列名称。
- Filter Operator:行过滤操作。
predicate:过滤条件,如 SQL 语句中的where id>=1,则此处显示(id >= 1)。
- Group By Operator:分组聚合操作。
aggregations:显示聚合函数信息。mode:有hash(Map 端的局部聚合�)、partial(同 hash)、final(Reduce 端的最终聚合)。outputColumnNames:聚合之后输出列名。Statistics:表统计信息,包含分组聚合之后的数据条数、数据大小等。
- Reduce Output Operator (ReduceSink):输出到 Reduce 的操作,负责 Shuffle 阶段的数据分区和排序。
sort order:排序规则。值为空不排序;值为+正序排序,值为-倒序排序。
- Map Join Operator:Map 端 Join 操作。
condition map:Join 方式 ,如Inner Join 0 to 1。keys:Join 的条件字段。outputColumnNames:Join 完成之后输出的字段。Statistics:Join 完成之后生成的数据条数、大小等。
- File Output Operator:文件输出操作。
compressed:是否压缩。
- Fetch Operator:客户端获取数据操作。
limit:值为-1表示不限制条数,其他值为限制的条数。
语法
EXPLAIN 命令的基本语法如下,通过添加不同参数可以获取不同维度的信息。
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
| 参数 | 描述 |
|---|---|
EXPLAIN | 查看执行计划的基本信息(Stage Plan 和 Stage Dependencies)。 |
FORMATTED | 以 JSON 格式输出执行计划,便于程序解析。用法:EXPLAIN FORMATTED query。 |
DEPENDENCY | 以 JSON 格式输出查询依赖的表和分区信息。 |
EXTENDED | 查看执行计划的扩展信息,包含更详细的算子树和文件系统操作。 |
CBO | 输出由 Calcite 优化器(Cost-Based Optimization)生成的计划。CBO 从 Hive 4.0.0 版本开始支持。 |
AST | 输出查询的抽象语法树(Abstract Syntax Tree)。该功能在 Hive 2.1.0 中因 Bug 被移除,在 4.0.0 版本修复。 |
AUTHORIZATION | 查看 SQL 操作所需权限的信息,有助于排查权限问题。 |
LOCKS | 查看运行该查询需要获取的锁信息。从 Hive 3.2.0 开始支持。 |
VECTORIZATION | 查看查询的向量化执行描述信息。从 Hive 2.3.0 开始支持。 |
ANALYZE | 在执行查询后,用实际的行数来注解计划。从 Hive 2.2.0 开始支持。 |
案例实操
理论知识准备完毕,让我们通过几个案例来实践如何解读和利用执行计划。
案例1:简单的 SELECT 查询
EXPLAIN
SELECT
id,
user_id,
product_id
FROM ds_hive.ch12_order_detail_orc t1
WHERE substr(create_time, 1, 10) >= '2023-01-01';
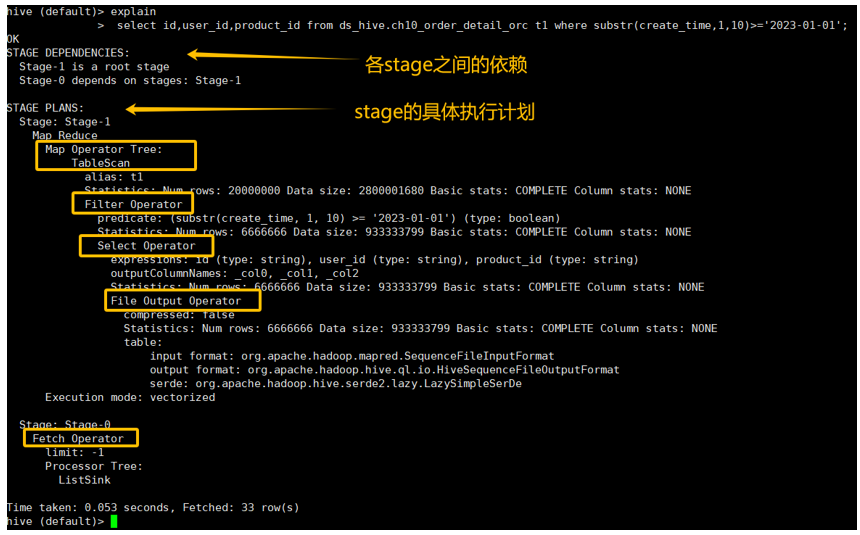
这个执行计划分为 Stage Dependencies 和 Stage Plan 两部分。从中大概能得到如下信息:
Stage Plan:
-
Stage-1 (Map-Only Stage)
- Map Operator Tree: 要理解算子树的执行顺序,一个有效的方法是从最内层的缩进开始,向上回溯,这代表了数据的处理流向。
- TableScan: 首先进行表扫描,
alias: t1。预估扫描20,000,000行,数据大小约2.8 GB。 - Filter Operator: 接着对扫描出的数据进行行过滤,
predicate: substr(create_time, 1, 10) >= '2023-01-01'。预估过滤后剩下6,666,666行。 - Select Operator: 此算子负责列选择,并准备数据输出。计划中展示了其详细的输出属性:
- Input/Output Format: 处理的输入格式(
input format)是org.apache.hadoop.mapred.SequenceFileInputFormat,输出格式(output format)是org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat,文件的序列化格式(serde)为org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe。 - Output Statistics: 输出的文件预计是
6,666,666行,数据大小是933,333,799字节。 - Compression: 输出没有压缩。
- Output Columns: 输出的列由占位符表示(如
_col0,_col1...),这是 MapReduce 内部阶段的常见表示法。 - Expressions: 计划中还列出了
expressions,定义了每个输出列(如_col0)是如何从输入列生成的。
- Input/Output Format: 处理的输入格式(
- TableScan: 首先进行表扫描,
- Map Operator Tree: 要理解算子树的执行顺序,一个有效的方法是从最内层的缩进开始,向上回溯,这代表了数据的处理流向。
-
Stage-0 (Fetch Stage)
- Fetch Operator: 这表示客户端从
Stage-1的最终结果中直接拉取数据的操作。
- Fetch Operator: 这表示客户端从
需要注意的是,执行计划是 Hive 根据统计信息所进行的简单描述,并非完全精确的物理执行过程,但它对于理解 SQL 执行细节、发现潜在问题非常有帮助。
深入思考与解答:
-
问题1:本表是 ORC 格式,为什么执行计划中 Input Format 显示为
SequenceFileInputFormat? 解答:这是一个常见的误解。执行计划展示的是逻辑计划或中间阶段的信息。TableScan算子在物理执行时会使用 ORC 对应的OrcInputFormat来读取数据。而计划中显示的SequenceFileInputFormat通常是 Hive 在 Map 和 Reduce 阶段之间进行数据交换时使用的序列化格式,它与底层表的存储格式是两个不同层面的概念。 -
问题2:预估的 n 行(输入/输出)是怎么来的? 解答:这些预估值来自于 Hive 的元数据统计信息。Hive 优化器(特别是 CBO)严重依赖这些统计信息来做出最优决策(如选择 Join 方式、预估数据量等)。因此,为了让优化器做出更准确的判断,定期对表和分区运行
ANALYZE TABLE ... COMPUTE STATISTICS是一个非常重要的好习惯。
案例2:带聚合的 GROUP BY 查询 (调优初体验)
我们来看一个带聚合的查询,并观察一个关键参数 hive.map.aggr 的影响。
1. 关闭 Map 端聚合
set hive.map.aggr=false;
EXPLAIN
SELECT t1.province_id, count(*) AS cnt
FROM ds_hive.ch12_order_detail_orc t1
GROUP BY t1.province_id;
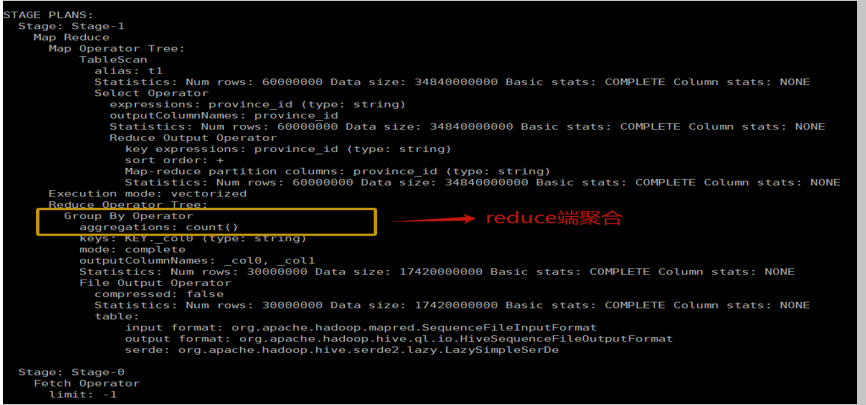
计划解读:
- Stage-1 (Map Phase):
TableScan->Select->ReduceSinkOperator。- Map 阶段只负责读取数据,并根据
province_id进行哈希分区,然后通过ReduceSink发送给 Reducer。没有进行任何聚合操作,所有原始数据都被发送到网络中,数据量巨大。
- Stage-2 (Reduce Phase):
GroupByOperator (mode: final)->Select->FileOutput。- Reduce 阶段接收来自所有 Mapper 的数据,然后执行最终的
GROUP BY聚合计算。
2. 开启 Map 端聚合(默认开启)
set hive.map.aggr=true;
EXPLAIN
SELECT t1.province_id, count(*) AS cnt
FROM ds_hive.ch12_order_detail_orc t1
GROUP BY t1.province_id;
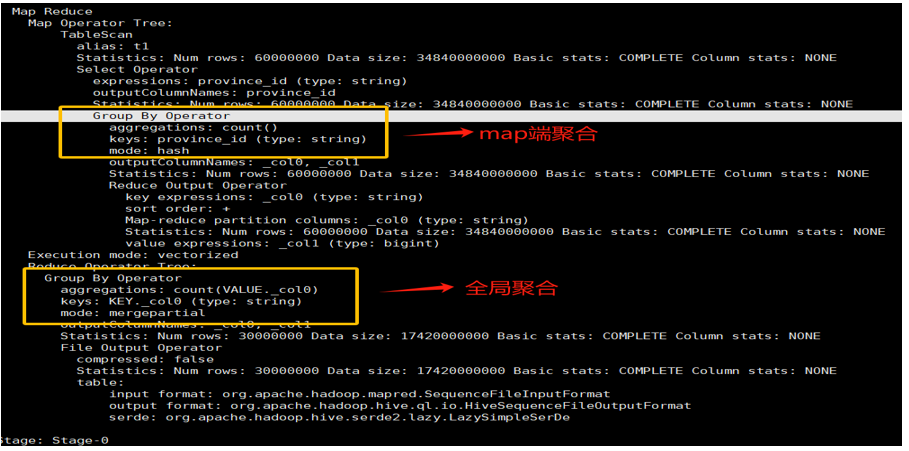
计划解读:
- Stage-1 (Map Phase):
TableScan->Select->GroupByOperator (mode: hash)->ReduceSinkOperator。- 关键变化出现了!在 Map 阶段增加了一个
GroupByOperator,它会先在每个 Mapper 内部进行一次局部聚合(也叫预聚合或combiner)。
- Stage-2 (Reduce Phase):
GroupByOperator (mode: final)->Select->FileOutput。- Reduce 阶段接收的是经过 Map 端局部聚合后��的中间结果,数据量已大大减少,然后再进行最终的合并聚合。
调优启示:
通过对比可以发现,开启 Map 端聚合 (hive.map.aggr=true) 能极大地减少 Map 到 Reduce 的网络 I/O 和数据传输量,是 GROUP BY 优化的一个关键手段。执行计划清晰地向我们展示了这一内部机制的差异。
思考:我们在查看执行计划时更应该关注哪些内容?
通过以上阐述,我们可以总结出,在分析执行计划时,应重点关注以下几点:
- Stage 的数量:Stage 越多,通常意味着 Shuffle 次数越多,查询越复杂,I/O 开销越大。
- 数据扫描方式:是否走了分区裁剪?是否进行了全表扫描?
TableScan算子会提供这些信息。 - Join 类型:是 Map Join 还是 Shuffle Join?这直接决定了 Join 操作的性能。
- 数据倾斜的风险:观察
GROUP BY或JOIN的 key,以及ReduceSink的分区方式,预判是否存在数据倾斜的可能。 - 不必要的算子:是否存在可以优化的冗余计算或低效操作。