六种类型的存储格式 ⭐️⭐️
理解 ⭐️⭐️
在大数据处理中,数据的存储方式直接决定了查询和分析的效率。Apache Hive 作为一个数据仓库工具,支持多种底层文件存储格式。选择合适的存储格式,可以在存储成本和查询性能之间找到最佳平衡点。本文将详细介绍 Hive 中常用的六种存储格式,并重点解析 TextFile、RCFile、ORC 和 Parquet 的内部原理、优缺点及适用场景。
六种类型的存储格式(⭐️了解)
Apache Hive支持Apache Hadoop中使用的几种熟悉的文�件格式,如TextFile,RCFile,SequenceFile,AVRO,ORC和Parquet格式。Cloudera Impala也支持这些文件格式。在建表时使用STORED AS (TextFile|RCFile|SequenceFile|AVRO|ORC|Parquet)来指定存储格式。
行式存储:
- TextFile: 每一行都是一条记录,每行都以换行符(\n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。可结合压缩算法使用,但需要注意,使用 Gzip 压缩后,文件将无法被切分,导致 Hive 只能用一个 Map Task 处理,无法实现并行计算。而 Bzip2 等其他压缩格式则支持切分。
- SequenceFile: 是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。支持三种压缩选择:NONE, RECORD, BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
- AVRO: 是一个为Hadoop提供数据序列化和数据交换服务的开源项目。Avro是一种用于支持数据密集型的二进制文件格式,文件格式更为紧凑,序列化和反序列化性能优秀。其核心优势在于强大的模式演进(Schema Evolution)能力,非常适合需要频繁变更数据结构的场景,例如在 Kafka 数据流或 RPC 框架中。在 Hive 中使用的不多
列式存储:
- RCFile: 是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
- ORC: 文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际上是为了克服其他Hive文件格式的限制而设计的。当Hive从大型表读取、写入和处理数据时,使用ORC文件可以��显著提高性能。
- Parquet: 是一个面向列的二进制文件格式,对于大型查询非常高效,尤其适合扫描表中特定列的查询场景。Parquet默认使用Snappy进行压缩,也支持Gzip等其他算法。
TextFile 存储格式详解
TEXTFILE 介绍
TEXTFILE 即正常的文本格式,是Hive默认的文件存储格式(取决于hive.default.fileformat配置),因为大多数情况下源数据文件都是以text文件格式保存,便于查看验数和防止乱码。此种格式的表文件在HDFS上是明文,可用hadoop fs -cat命令查看,从HDFS上get下来后也可以直接读取。
TEXTFILE 存储文件默认每一行就是一条记录,可以指定任意的分隔符进行字段间的分割。但这个格式无压缩,需要的存储空间很大。虽然可结合Gzip、Bzip2、Snappy等压缩使用,但如前所述,使用Gzip压缩后,Hive将无法对数据进行切分,从而无法并行操作,这会严重影响处理大规模数据时的性能。
一般只有与其他系统有数据交互的接口表采用TEXTFILE格式,其他事实表和维度表都不建议使用。该格式磁盘开销和数据解析开销都很大。其对应的Hive API为:org.apache.hadoop.mapred.TextInputFormat和org.apache.hive.ql.io.HiveIgnoreKeyTextOutputFormat。
文本文件是Hive默认使用的文件格式,文本文件中的一行内容,就对应Hive表中的一行记录。
可通过以下建表语句指定文件格式为文本文件:
create table textfile_table
(column_specs)
stored as textFile;
RC File 存储格式详解(⭐️了解)
RC File 介绍
RCFile(Record Columnar File)存储结构遵循的是“先水平划分,再垂直划分”的设计理念。RCFile结合了行存储和列��存储的优点:首先,RCFile保证同一行的数据位于同一节点,因此元组重构的开销很低;其次,像列存储一样,RCFile能够利用列维度的数据压缩,并且能跳过不必要的列读取。
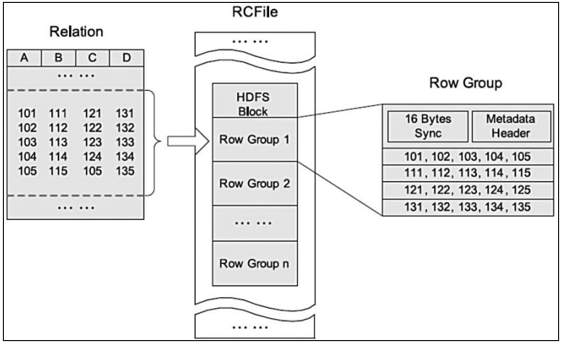
如上图是HDFS内RCFile的存储结构。每个HDFS块中,RCFile以行组为基本单位来组织记录。对于一张表,所有行组大小都相同。一个HDFS块会有一个或多个行组。一个行组包括三个部分。第一部分是行组头部的同步标识,主要用于分隔HDFS块中的两个连续行组;第二部分是行组的元数据头部,用于存储行组单元的信息,包括行组中的记录数、每个列的字节数、列中每个域的字节数;第三部分是表格数据段,即实际的列存储数据。
某些纯列式存储格式,同一列的数据可能存在于不同的block上,查询时重组列会浪费很多IO开销。而RCFile由于相同的列都组织在同一个HDFS块内,相对而言会节省资源。
RCFile采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。RCFile不支持任意方式的数据写操作,仅提供一种追加接口,这是因为底层的HDFS当前仅仅支持数据追加写文件尾部。
当处理一个行组时,RCFile无需将行组的全部内容读取到内存。相反,它仅仅读取元数据头部和查询所需的列。因此,它可以跳过不必要的列以获得列存储的I/O优势。例如,对于查询 select c from table where a>1,RCFile会先解压行组中 a 列的数据进行过滤,如果当前行组中存在满足 a>1 的行,它才会去解压 c 列的数据,否则整个行组的 c 列数据都可以被跳过。
ORC File 存储格式详解(⭐️⭐️重点理解)
ORC 定义
ORC File,全称是Optimized Row Columnar File,可以看作是 RCFile 的一个优化版本。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据,其设计目标是克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。和RCFile格式相比,ORC File格式有以下优点:
- 更高的压缩比:ORC拥有比其他格式更高的压缩比,减少了查询任务的输入数据量和所需的Task数量,从而提升查询速度和处理性能。
- 支持复杂数据类型:支持各种复杂数据类型,如
datetime,decimal, 以及struct,list,map,union。 - 内置轻量级索引:在文件中存储了轻量级的索引数据,如行组索引(row group index)、布隆过滤器索引(bloom filter index)等,可用于WHERE条件的谓词下推。
- 更优的编码方式:ORC 扩展了 RCFile 的压缩,除了游程编码(Run-length),还引入了字典编码和Bit编码。
ORC File 文件结构
ORC File包含一组组的行数据,称为stripes(条带),除此之外,ORC File的file footer(文件尾)还包含一些额外的辅助信息。在ORC File文件的最后,有一个被称为postscript的区,它主要是用来存储压缩参数及压缩页脚的大小。
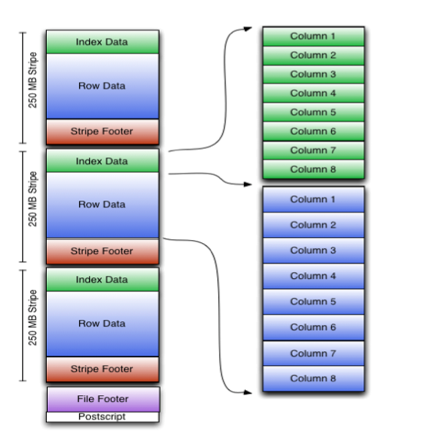
在默认情况下,一个stripe的大小为250MB。大尺寸的stripes使得从HDFS读数据更高效。
下图显示了 ORC File 的文件结构:
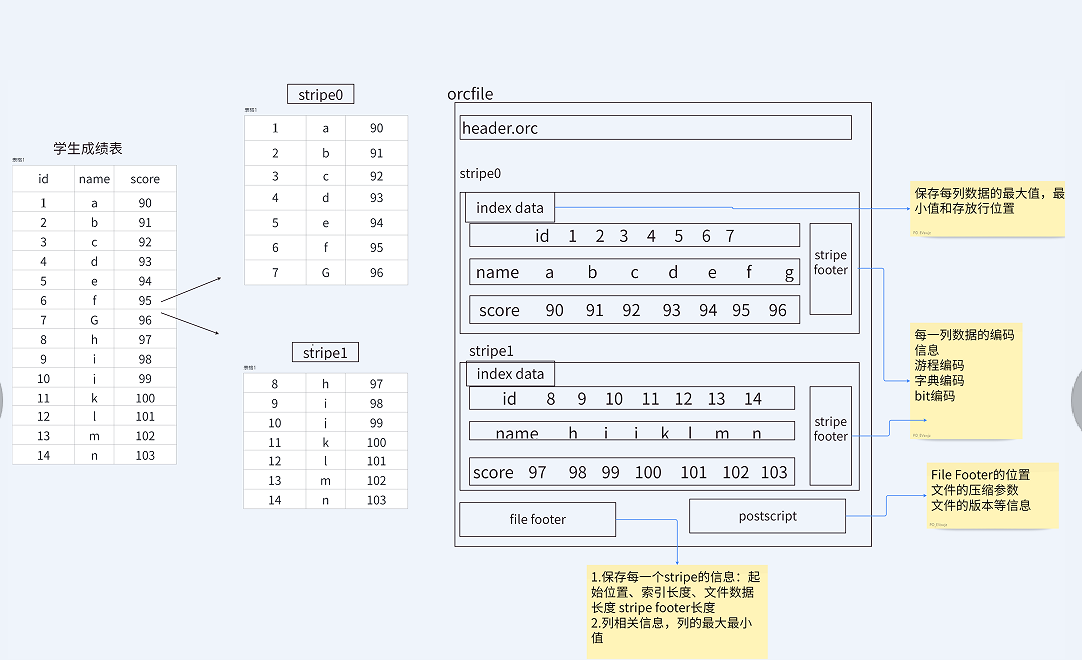
- Postscript: 存储该文件的元数据,如文件长度、压缩参数、压缩大小等信息。
- File Footer: 包含文件级别的统计信息(如各列的最大/最小值)、Stripe的位置信息、表结构信息等。
- Stripe Footer: 包含该Stripe的元数据信息,如列的编码方式和流的位置目录。
- Index Data: 轻量级索引,保存了该Stripe上每个列的统计信息(最大/最小值)和数据的位置信息,用于跳过不必要的数据块。
- Row Data: 存的是具体的数据,先按行组(默认10000行)切分,然后对这些行按列进行存储。每个列的数据经过编码后,形成多个Stream。
Hive读取数据时,会从文件尾部读取Postscript,解析出File Footer的长度,再读取File Footer,从中获取各个Stripe的信息,然后根据查询需要选择性地读取Stripe,即从后往前读。
Stripe 结构
从上图我们可以看出,每个Stripe都包含index data、row data以及stripe footer。Stripe footer包含流位置的目录;Row data在表扫描的时候会用到。
Index data包含每列的最大和最小值以及每列所在的行。行索引提供了偏移量,它可以帮助查询引擎跳到正确的压缩块位置。通过这种相对频繁的行索引(默认每10000行一个),即使stripe很大,也可以在读取过程中快速跳过大量不符合条件的行。拥有通过过滤谓词而跳过大量行的能力,你可以在表的 secondary keys 进行排序,从而可以大幅减少执行时间。比如你的表的主分区是交易日期,那么你可以对次分区(state、zip code以及last name)进行排序。
在 Hive 中使用 ORCFile
在创建Hive表时,可以指定文件的存储格式。以下是在HiveSQL语句中指定使用ORCFile的示例:
CREATE TABLE ...
STORED AS ORC
[TBLPROPERTIES (property_name=property_value, ...)]
所有关于ORCFile的参数都在HiveSQL语句的TBLPROPERTIES子句中设置,常用参数如下:
| Key | Default | Notes |
|---|---|---|
orc.compress | ZLIB | 高级别压缩算法 (可选 NONE, ZLIB, SNAPPY) |
orc.compress.size | 262,144 | 每个压缩块的大小(字节) |
orc.stripe.size | 67,108,864 | 每个Stripe的大小(字节) |
orc.row.index.stride | 10,000 | 索引步长,即多少行创建一个索引项 (必须 >= 1000) |
orc.create.index | true | 是否创建行级别索引 |
orc.bloom.filter.columns | "" | 需要创建布隆过滤器的列名列表,以逗号分隔 |
orc.bloom.filter.fpp | 0.05 | 布隆过滤器的假阳性率 (必须 > 0.0 且 < 1.0 ) |
下面的例子是建立一个没有启用压缩的ORCFile表:
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc
tblproperties ("orc.compress"="NONE");
Parquet 存储格式详解
Parquet 的简介
Parquet 是主流的列式存储格式,最早由 Twitter 和 Cloudera 合作开发,2015 年 5 月成为 Apache 顶级项目,支持大部分的计算框架。
Parquet 最初的设计动机是高效地存储嵌套式数据,比如Protocol Buffer、Thrift、JSON等,将这类数据存储成列式格式,以方便对其进行高效压缩和编码,并使用更少的IO操作取出需要的数据。对嵌套结构的优秀支持是Parquet的一个关键优势。
Parquet 是一种与语言、平台无关的存储格式,不与任何数据处理框架绑定。作为一种纯粹的文件格式,其本身不直接支持 UPDATE 操作或 ACID 事务。这些高级功能通常由更高层的数据湖管理框架(如 Apache Iceberg、Delta Lake)提供,而这些框架底层最常用的存储格式正是 Parquet。
Parquet文件是以二进制方式存储的,所以不可以直接读取。文件中包含了数据和元数据,因此Parquet格式文件是自解析的。
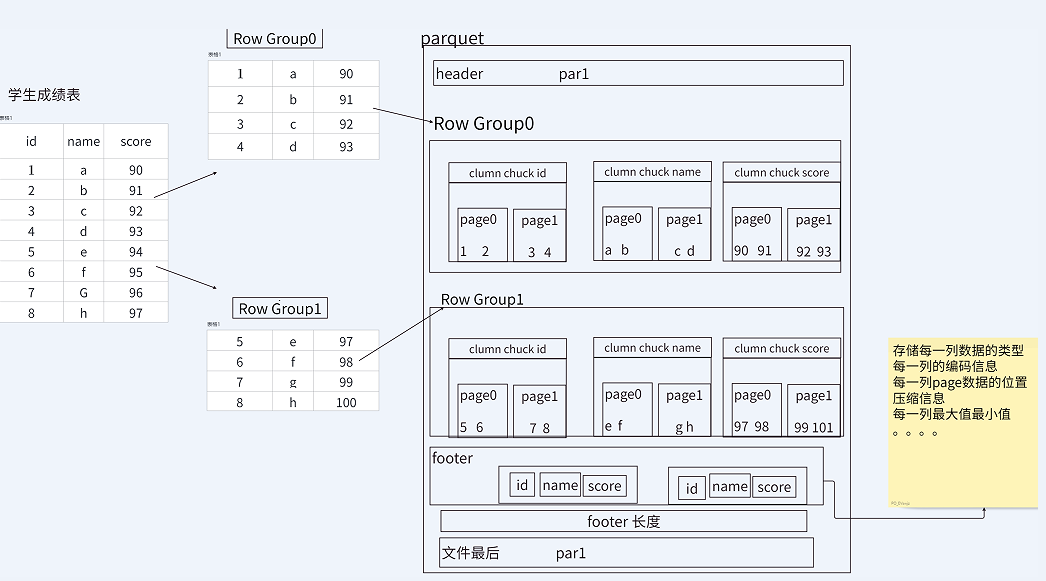
Parquet 文件结构
Parquet文件由一个文件头(Header,即Magic Code,用于校验文件类型)、一个或多个行组(Row Group)、以及一个文件尾(Footer)构成。行组内部由列块(Column Chunk)和页(Page)组成。
- 行组(Row Group): Parquet 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小��对齐。Parquet 保证一个行组会被一个 Mapper 处理。
- 列块(Column Chunk): 行组中每一列保存在一个列块中。一个列块中的数据类型相同,不同的列块可以使用不同的压缩算法。
- 页(Page): 列块内部由多个页组成。页是最小的编码和压缩单元,同一列块的不同页可以使用不同的编码方式。
建表语句
可通过以下建表语句指定文件格式为 Parquet 文件:
Create table parquet_table
(column_specs)
stored as parquet
tblproperties (property_name=property_value, ...);
支持的参数如下:
| 参数 | 默认值 | 说明 |
|---|---|---|
parquet.compression | UNCOMPRESSED | 压缩格式, 可选项: UNCOMPRESSED, SNAPPY, GZIP, LZO, BROTLI, LZ4 |
parquet.block.size | 134217728 | 行组大小(字节), 通常与 HDFS 块大小保持一致 |
parquet.page.size | 1048576 | 页大小(字节) |
Parquet vs ORC
ORC和Parquet都是高效的列式存储格式,它们在存储和处理大规模数据时具有相似的优势,但在实现细节和生态系统上存在一些差异。
Parquet 与 ORC 的不同点总结如下:
- 嵌套结构支持:Parquet 能够完美地支持嵌套式结构,其设计灵感来源于 Google Dremel。而 ORC 对嵌套结构的支持相对复杂,可能导致性能和空间上的损耗。
- 更新与 ACID 支持:ORC 格式原生支持 update 操作与 ACID(在Hive 3.0及以上版本中)。而 Parquet 本身不支持,需要借助上层的数据湖框架(如Iceberg, Delta Lake, Hudi)来实现。
- 压缩与查询性能:在压缩率和查询性能方面,两者总体上不相上下,性能差异通常取决于具体的数据集和查询负载。在某些场景下 ORC 的压缩率和查询速度可能略有优势。
- 生态系统兼容性:ORC 源于 Hive 生态,与 Hive 的集成最为紧密。Parquet 则凭借其出色的平台无关性,成为了 Spark、Presto、Impala 等众多计算引擎的事实标准,尤其在 Spark 生态中是默认推荐的格式。
总之,ORC和Parquet都是顶级的列式存储格式。选择哪种格式,更多地取决于技术栈的偏好和具体的应用场景。
总结与格式选择建议
为了方便快速回顾和比较,下表总结了三种核心存储格式(TextFile、ORC、Parquet)的关键特性。
| 特性 | TextFile | ORC | Parquet |
|---|---|---|---|
| 存储方式 | 行式存储 | 优化的列式存储 | 列式存储 |
| 压缩性能 | 差(本身无压缩) | 优秀(Zlib, Snappy) | 优秀(Snappy, Gzip) |
| 是否可分割 | 否(Gzip压缩后) | 是 | 是 |
| 查询性能 | 慢,需全表扫描 | 极高,支持谓词下推和索引 | 极高,支持谓词下推 |
| 模式演进 | 不支持 | 支持 | 支持 |
| 嵌套结构支持 | 弱 | 良好 | 优秀 |
| 生态系统 | 通用 | 主要在 Hive 生态 | 广泛(Spark, Presto等) |
选择建议:
- TextFile: 适用于小数据量、临时数据交换或作为数据接入的初始阶段,方便调试和查看。
- ORC: 如果技术栈以 Hive 为核心,并且需要 ACID 事务支持,ORC 是最佳选择。
- Parquet: 如果你的数据处理平台多样化,特别是以 Spark 为主,或者数据中包含复杂的嵌套结构,Parquet 是更通用和推荐的选择。