数据倾斜优化 ⭐️⭐️⭐️
必考 ⭐️⭐️⭐️
此知识点是面试必考,必须掌握。对于MapReduce计算框架,数据量大本身不是问题,但数据倾斜是导致性能瓶颈的关键。本文将深入探讨数据倾斜的成因、表现,并针对 GROUP BY、JOIN 和 COUNT DISTINCT 等常见场景,提供详细的优化方案与代码实践。
数据准备
订单表 (ch12_order_detail_orc)
建表与加载数据语句
-- 订单表:存储为ORC格式
CREATE TABLE IF NOT EXISTS ds_hive.ch12_order_detail_orc(
`id` STRING COMMENT '订单id',
`user_id` STRING COMMENT '用户id',
`product_id` STRING COMMENT '商品id',
`province_id` STRING COMMENT '省份id',
`create_time` STRING COMMENT '下单时间',
`product_num` INT COMMENT '商品件数',
`total_amount` DECIMAL(16,2) COMMENT '下单金额'
)
COMMENT '订单表'
STORED AS ORC;
-- 从文本文件加载数据到ORC表中
INSERT INTO TABLE ds_hive.ch12_order_detail_orc
SELECT
id,
user_id,
product_id,
province_id,
create_time,
product_num,
total_amount
FROM ds_hive.ch10_order_detail_txtfile;
省份信息表 (ch12_province_info_orc)
建表与加载数据语句
-- 1. 创建源数据文本表
CREATE TABLE ds_hive.ch10_province_info_textfile(
id STRING COMMENT '省份id',
province_name STRING COMMENT '省份名称'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
-- 2. 加载本地数据
LOAD DATA LOCAL INPATH "/home/hewwen8888/data/province_info.txt" OVERWRITE INTO TABLE ds_hive.ch10_province_info_textfile;
-- 3. 创建ORC格式的省份表
CREATE TABLE ds_hive.ch12_province_info_orc(
id STRING COMMENT '省份id',
province_name STRING COMMENT '省份名称'
)
STORED AS ORC
TBLPROPERTIES ('orc.compress'='NONE');
-- 4. 将文本数据导入ORC表
INSERT OVERWRITE TABLE ds_hive.ch12_province_info_orc
SELECT
id,
province_name
FROM ds_hive.ch10_province_info_textfile;
-- 5. 手动插入一条空值key,用于后续演示空值倾斜场景
INSERT INTO ds_hive.ch12_province_info_orc
SELECT
NULL AS id,
'测试数据' AS province_name;
构造用于测试倾斜的表
-- 构造一张倾斜的大表,将订单ID作为省份名称,模拟key分布极不均匀的情况
-- 这张表将用于后续演示大表JOIN大表的倾斜场景
CREATE TABLE ds_hive.ch12_province_info_orc_dabiao AS
SELECT
id,
province_name
FROM ds_hive.ch10_province_info_textfile
UNION ALL
SELECT
id,
product_id AS province_name
FROM ds_hive.ch10_order_detail_txtfile;
11.2.1 数据倾斜的原因
数据倾斜(Data Skew)指的是在分布式计算过程中,数据在不同节点或不同任务之间分布不均匀的现象。这种不均匀分布会使部分节点或任务的负载远高于其他节点或任务,从而成为整个作业的瓶颈,严重影响系统性能和效率。
数据产生倾斜的原理:
数据倾斜问题,通常是指参与计算的数据分布不均,即某个或某些 key 的数据量远超其他 key,导致在 Shuffle 阶段,大量相同的 key 被发送到同一个 Reduce 任务,�进而导致该 Reduce 所需的处理时间远超其他 Reduce,成为整个任务的“短板”。
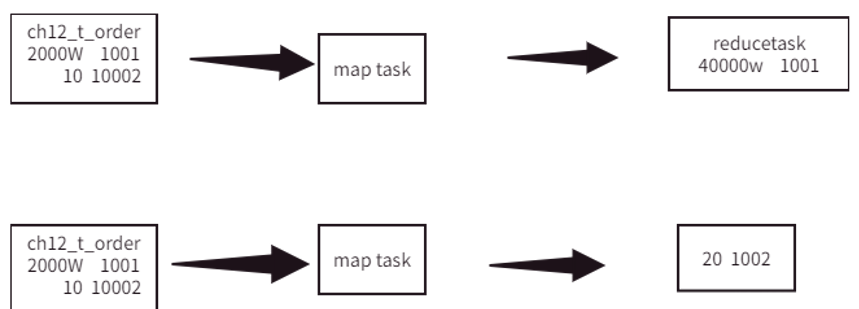
- 业务数据本身存在倾斜:例如,订单数据中,北京、上海等一线城市的订单量远超其他城市;或者存在大量
null或空字符串的 key。 - SQL 操作触发倾斜:某些SQL操作(如
JOIN,GROUP BY,COUNT(DISTINCT))在遇到特定数据分布时,天然容易触发数据倾斜。
| 关键词 | 情形 | 后果 |
|---|---|---|
| Join | 一张小表与一张大表关联,但小表中的某个 key 集中;或两张大表关联,关联键分布不均。 | 分发到某一个或几个 Reduce 上的数据远高于平均值。 |
| Group By | GROUP BY 的维度过小,导致某个分组下的数据量极大。 | 处理该分组的 Reduce 任务非常耗时。 |
| Count(distinct) | 对某个字段去重,但该字段的某些值出现次数极多。 | 所有数据必须汇集到一个 Reduce 任务中处理,造成单点瓶颈和数据膨胀。 |
11.2.2 数据倾斜的表现
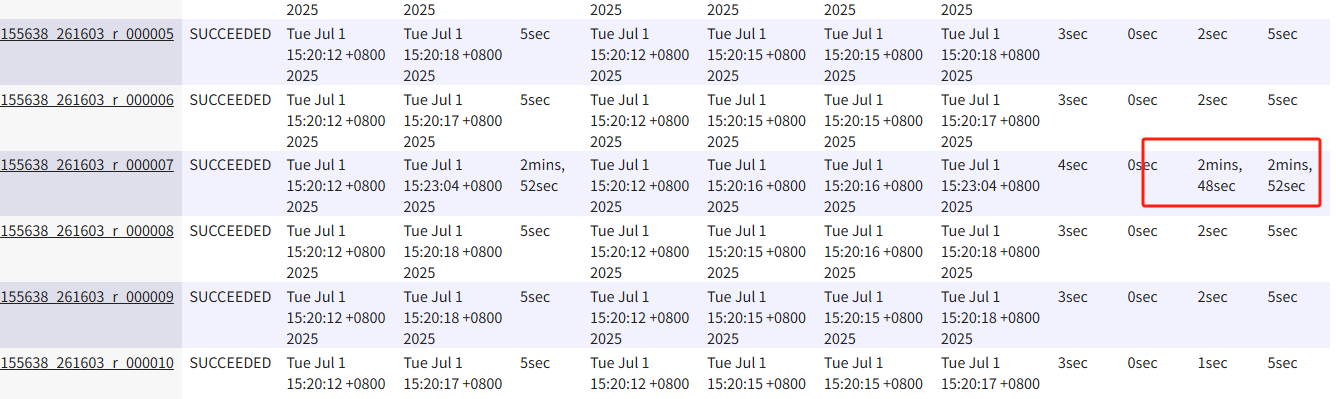
- 任务进度长时间卡顿:任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)Reduce 子任务未完成。
- 任务资源差异巨大:单一 Reduce 的处理记录数与平均记录数差异过大,通常可能达到3倍甚至更多。其运行时长也远大于平均时长。
- YARN 日志分析:从 YARN 的任务监控界面可以看到明显的“长尾”任务。
11.2.3 处理数据倾斜
Group By 产生倾斜的问题
1. 开启 Map 端聚合 (Combiner)
对于聚合类的操作,最直接的优化是开启 Map 端聚合。这会在 Map 阶段预先对数据进行一次聚合,从而减少 Shuffle 阶段需要传输和处理的数据量。
-- 开启Map端聚合,默认值为true。
-- 这能在Map阶段预先处理一部分聚合,极大减少Shuffle数据量。
SET hive.map.aggr=true;
EXPLAIN
SELECT
province_id,
COUNT(*) AS cnt
FROM ds_hive.ch12_order_detail_orc
GROUP BY province_id;
Map 端聚合能有效缓解数据倾斜问题,但并不是所有map端聚合都能完全屏蔽。Map 端聚合后发往 Reduce 的数据量依然可能很大,我们需要结合另外一个参数一起使用,开启负载均衡。
2. 开启负载均衡 (两阶段聚合)
当 GROUP BY 的 key 倾斜严重时,可以开启 Hive 的负载均衡配置。
-- 开启GROUP BY数据倾斜优化,默认值为false
SET hive.groupby.skewindata=true;
explain
select province_id,
count(*) as cnt
from ds_hive.ch12_order_detail_orc1 t1
group by province_id;
-----------------------------------------
set hive.groupby.skewindata=false;
explain
select province_id,
count(*) as cnt
from ds_hive.ch12_order_detail_orc1 t1
group by province_id;
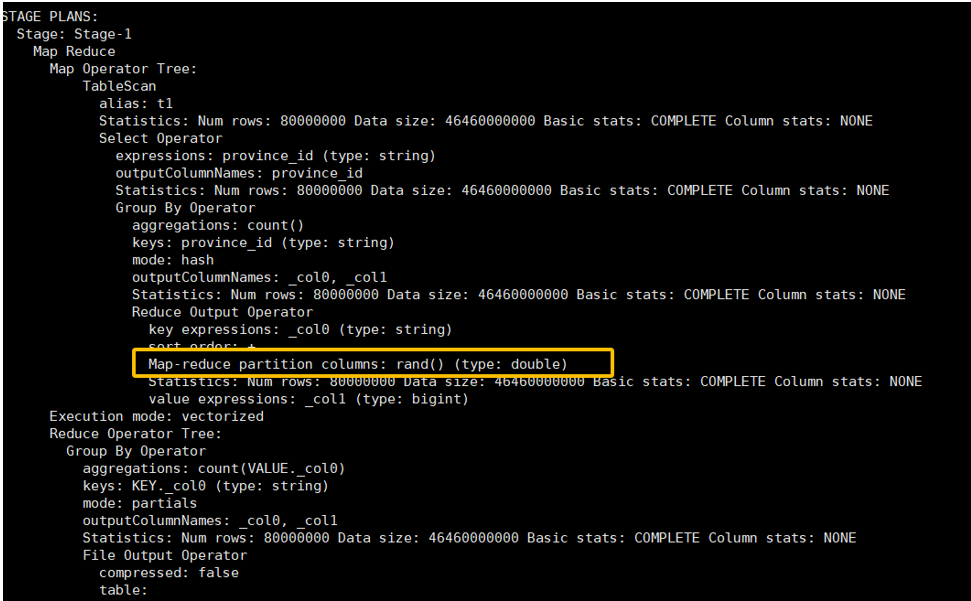
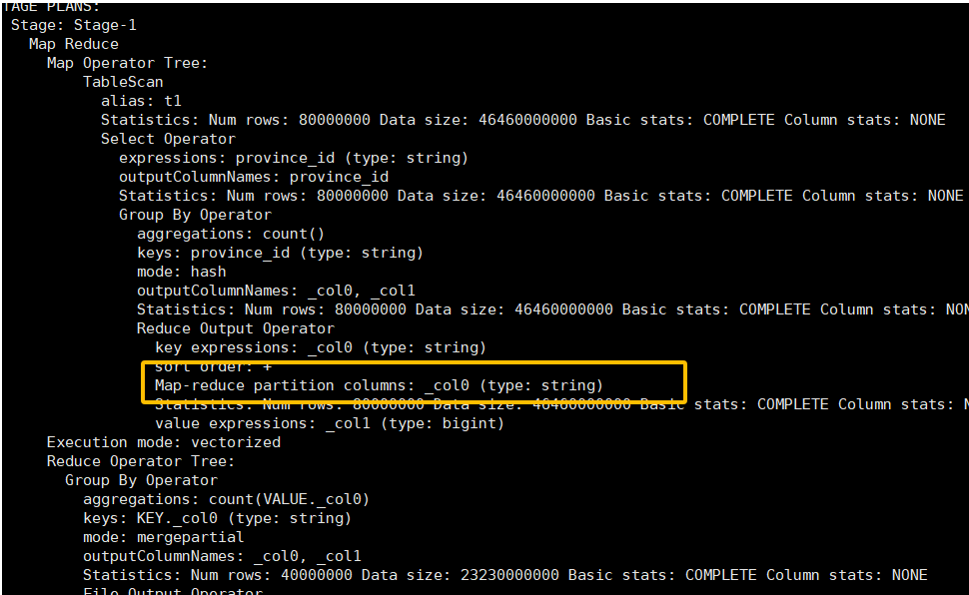
原理:此参数会把一个 MapReduce 作业拆分成两个。
- 第一个 MR Job:Map 的输出结果会随机分发到 Reduce 中(通过添加随机数后缀),每个 Reduce 只做部分聚合,实现负载均衡。这样,原来倾斜的 key 被打散到了多个 Reduce 任务中。
- 第二个 MR Job:在第一个 MR 的基础上,再按照原始的
GROUP BYkey 进行数据分发,完成最终的聚合操作。
这种方法的代价是需要启动两个 MR 任务,会增加整体的执行时间,但能有效解决严重倾斜问题,是一种用资源换时间的策略。
Join 导致的数据倾斜
未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由join导致的数据倾斜问题,有如下三种解决方案:
1. Map Join (适用于大表 JOIN 小表)
使用 Map Join 算法,JOIN 操作完全在 Map 端完成,没有 Shuffle 和 Reduce 阶段,自然不会产生 Reduce 端的数据倾斜。该方案适用于一个大表 JOIN 多个小表的场景。
-- 启动Map Join自动转换,默认值为true。
-- Hive会根据表的大小自动判断是否将Common Join转换为Map Join。
SET hive.auto.convert.join=true;
-- 若关闭自动转换,则会使用Common Join,可能出现倾斜
-- SET hive.auto.convert.join=false;
CREATE TABLE ds_hive.ch12_order_detail_qingxie_join1 AS
SELECT
t1.id,
t2.province_name
FROM ds_hive.ch12_order_detail_orc t1
LEFT JOIN ds_hive.ch12_province_info_orc t2
ON t1.province_id = t2.id;
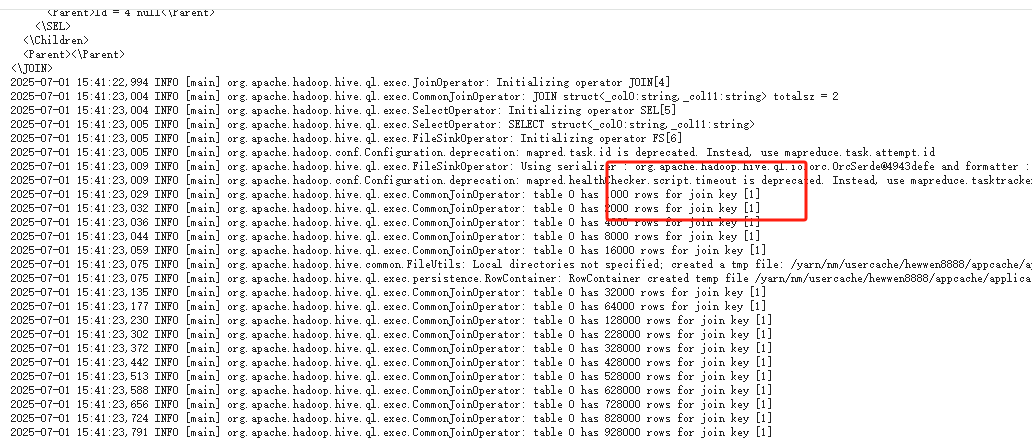
如何定位倾斜的 Key?
当任务发生倾斜时,可以通过 YARN UI 定位到运行缓慢的 Reduce Task。
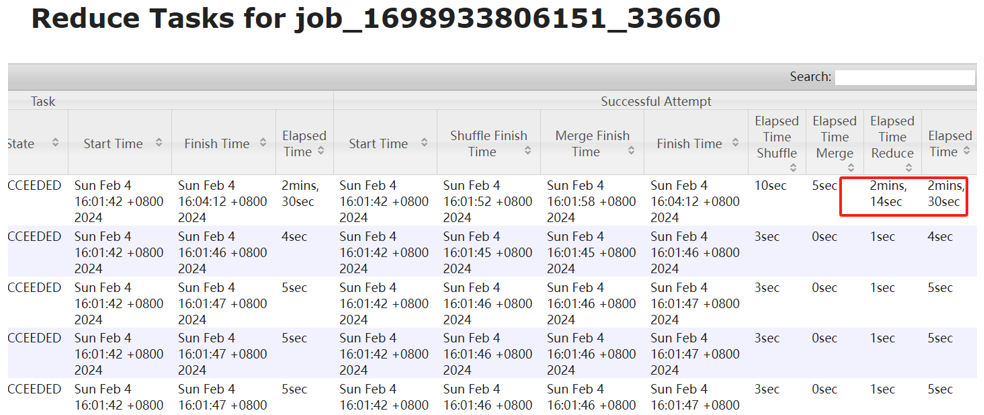
点击该 Task 的 Logs,找到诊断信息链接。
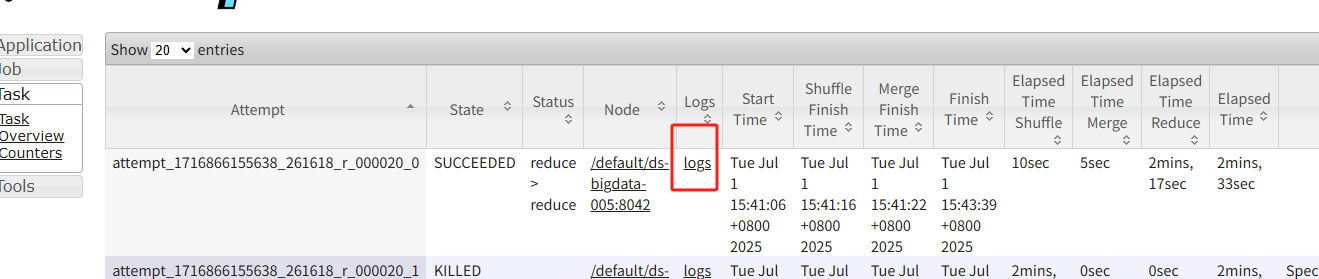
在诊断页面中,通常可以找到导致倾斜的具体 key 值。
2. Skew Join (适用于倾斜 key 明确的场景)
并不是所有的Join都能满足Map Join,这里我们又出现一种优化方案,那就是Skew。Skew Join 是一种更为智能的优化,它在运行时自动检测倾斜的 key。处理时,它会将倾斜的 key 和非倾斜的 key 分开处理:非倾斜部分走常规的 Reduce Join,而倾斜的 key 则单独用 Map Join 的方式处理。最后将两部分结果合并。
注意:此优化通常只对 INNER JOIN 有效,并且需要提前在表属性中声明倾斜的键和值,或通过参数进行设置。
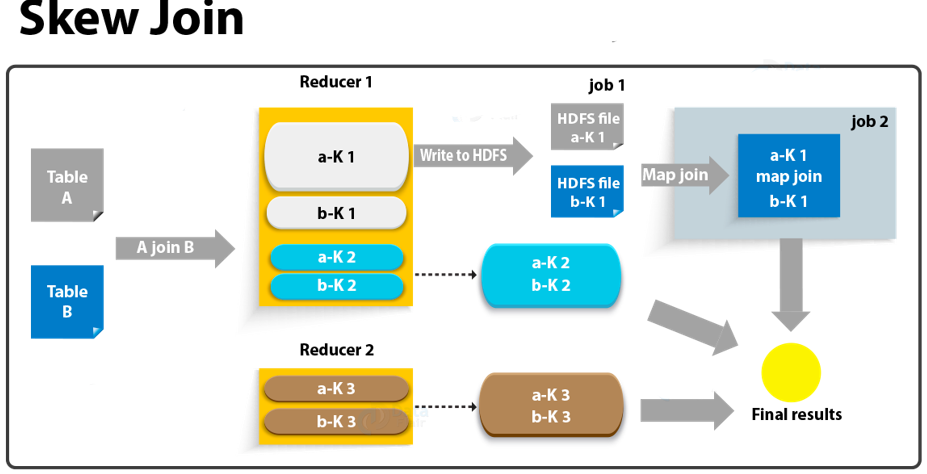
-- 这种方案对参与join的源表大小没有要求,但是对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)。
-- 启用Skew Join优化
SET hive.optimize.skewjoin=true;
-- 触发Skew Join的阈值,若某个key的行数超过该参数值,则触发
SET hive.skewjoin.key=100000;
-- 关闭Map Join自动转换,以测试Skew Join的效果
SET hive.auto.convert.join=false;
CREATE TABLE ds_hive.ch12_order_detail_qingxie_join2 AS
SELECT
t1.id,
t2.province_name
FROM ds_hive.ch12_order_detail_orc t1
JOIN ds_hive.ch12_province_info_orc_dabiao t2 -- 使用构造的倾斜大表
ON t1.province_id = t2.id;
3. 调整 SQL 语句 (适用于大表 JOIN 大表)
当两张表都很大,无法使用 Map Join,且 Skew Join 效果不佳时,可以通过手动改写 SQL 来解决倾斜。
场景一:空值 (NULL) 关联造成的倾斜
把空值的 key 变成带随机数的字符串,将倾斜数据打散到不同的 Reduce 上。由于这些随机 key 无法关联上,处理后不影响最终结果。
CREATE TABLE ds_hive.ch12_order_detail_qingxie_join3 AS
SELECT
t1.id,
t2.province_name
FROM ds_hive.ch12_order_detail_orc_null t1 -- 假设此表province_id有大量NULL
LEFT JOIN ds_hive.ch12_province_info_orc_dabiao t2
ON CASE WHEN t1.province_id IS NULL THEN CONCAT('ds_skew_', RAND()) ELSE t1.province_id END = t2.id;
场景二:热点值 (Hot Key) 造成的倾斜
将倾斜的 key 与非倾斜的 key 分开处理,最后用 UNION ALL 合并结果。
-- 方案:将倾斜的key(热点值)与非倾斜key分开处理,最后合并结果
-- 假设我们已经通过分析定位到倾斜的 key 是 '1'
CREATE TABLE ds_hive.ch12_order_detail_qingxie_join3 AS
-- 1. 先处理所有非倾斜的key,这部分数据均匀,可以正常JOIN
SELECT
t1.id,
t2.province_name
FROM ds_hive.ch12_order_detail_orc t1
LEFT JOIN ds_hive.ch12_province_info_orc_dabiao t2
ON t1.province_id = t2.id
WHERE t1.province_id <> '1'
UNION ALL
-- 2. 单独处理倾斜的key '1'
-- 对于这部分倾斜的JOIN,可以强制走MapJoin(如果右表过滤后很小),或继续使用随机数打散
SELECT
t1.id,
t2.province_name
FROM ds_hive.ch12_order_detail_orc t1
LEFT JOIN ds_hive.ch12_province_info_orc_dabiao t2
ON t1.province_id = t2.id
WHERE t1.province_id = '1';
场景三:动态发现倾斜 Key 并处理
如果倾斜的 key 不固定,可以动态找出倾斜 key 进行分别处理。
-- 注意:这种动态方案虽然灵活,但子查询可能导致性能问题,
-- 通常建议在ETL流程中提前计算好倾斜的key并将其作为变量传入。
CREATE TABLE ds_hive.ch12_order_detail_qingxie_join3 AS
-- 处理倾斜的大key (数据量 > 200万)
SELECT
t1.id,
t2.province_name
FROM ds_hive.ch12_order_detail_orc t1
LEFT JOIN ds_hive.ch12_province_info_orc t2
ON t1.province_id = t2.id
WHERE t1.province_id IN (
SELECT province_id FROM ds_hive.ch12_order_detail_orc GROUP BY province_id HAVING COUNT(*) > 2000000
)
UNION ALL
-- 处理非倾斜的小key (数据量 <= 200万)
SELECT
t1.id,
t2.province_name
FROM ds_hive.ch12_order_detail_orc t1
LEFT JOIN ds_hive.ch12_province_info_orc t2
ON t1.province_id = t2.id
WHERE t1.province_id IN (
SELECT province_id FROM ds_hive.ch12_order_detail_orc GROUP BY province_id HAVING COUNT(*) <= 2000000
);
Count Distinct 数据倾斜
COUNT(DISTINCT col) 操作天生容易导致数据倾斜。因为为了完成去重,所有相同的值必须被发送到同一�个 Reducer 进行处理。这会强制整个作业只使用一个 Reduce Task,成为性能瓶颈。
优化前 (单 Reducer,易倾斜)
SELECT COUNT(DISTINCT user_id) AS user_cnt
FROM ds_hive.ch12_order_detail_orc;
优化后 (两阶段聚合,并行处理)
通过 GROUP BY + COUNT 的两步法,将计算分散到多个 Reducer 并行处理。
- 第一步
GROUP BY可以利用多个 Reducer 并行对user_id进行去重。 - 第二步
COUNT(*)只是对去重后的结果进行计数,计算量极小。
SELECT COUNT(*)
FROM (
SELECT user_id
FROM ds_hive.ch12_order_detail_orc
GROUP BY user_id
) t1;
补充:窗口函数数据倾斜怎么处理?
窗口函数中的 PARTITION BY 子句与 GROUP BY 非常相似,如果分区键(PARTITION BY key)存在数据倾斜,同样会导致单个 Reducer 负载过重。
解决方案:采用“加盐”或“两阶段聚合”的思路。
-
第一阶段:加盐打散:在
PARTITION BY中增加一个随机数(盐),将原本集中在一个分区的数据打散到多个分区中,并行计算。-- 假设 a 是倾斜的分区键-- 通过拼接一个 0-9 的随机数,将一个大的分区打散成10个小分区SELECT*,ROW_NUMBER() OVER (PARTITION BY a, CAST(RAND() * 10 AS INT) ORDER BY b DESC) AS partial_rankFROM your_table; -
第二阶段:去盐还原:在第一阶段的基础上,再次使用窗口函数,这次只按原始的 key 分区,通过对第一阶段生成的局部排名进行排序,得到最终的正确排名。
WITH partial_ranked_data AS (SELECTa,b,-- 第一阶段:加盐打散,计算局部排名ROW_NUMBER() OVER (PARTITION BY a, CAST(RAND() * 10 AS INT) ORDER BY b DESC) AS partial_rankFROM your_table)-- 第二阶段:去盐还原,基于局部排名计算全局排名SELECTa,b,ROW_NUMBER() OVER (PARTITION BY a ORDER BY partial_rank ASC) AS final_rankFROM partial_ranked_data;
这种方法通过增加计算步骤,将倾斜分区的计算压力分散开,从而有效解决窗口函数中的数据倾斜问题。