Mapreduce的核心思想与数据流流程
概述
MapReduce的核心思想是化大为小,分而治之。
Mapreduce的主要组成:mapper和reducer
Mapper阶段:负责“分”,讲复杂的任务分解成若干个“简单的任务”来并行处理。Map阶段的任务没有依赖关系,所以可以并行的来处理。
Reducer阶段:负责map阶段的结果的全局汇总。
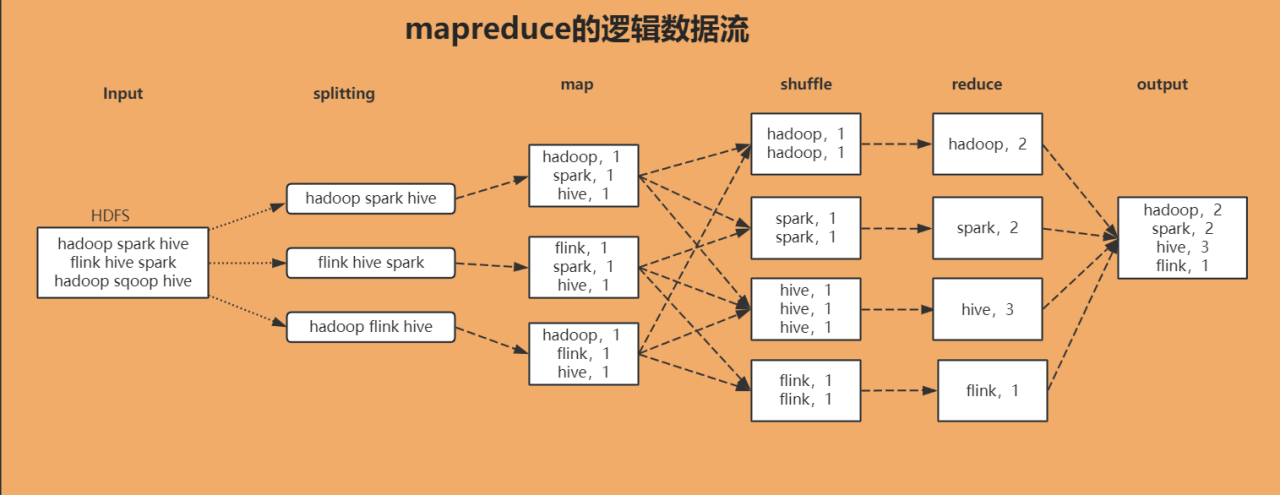
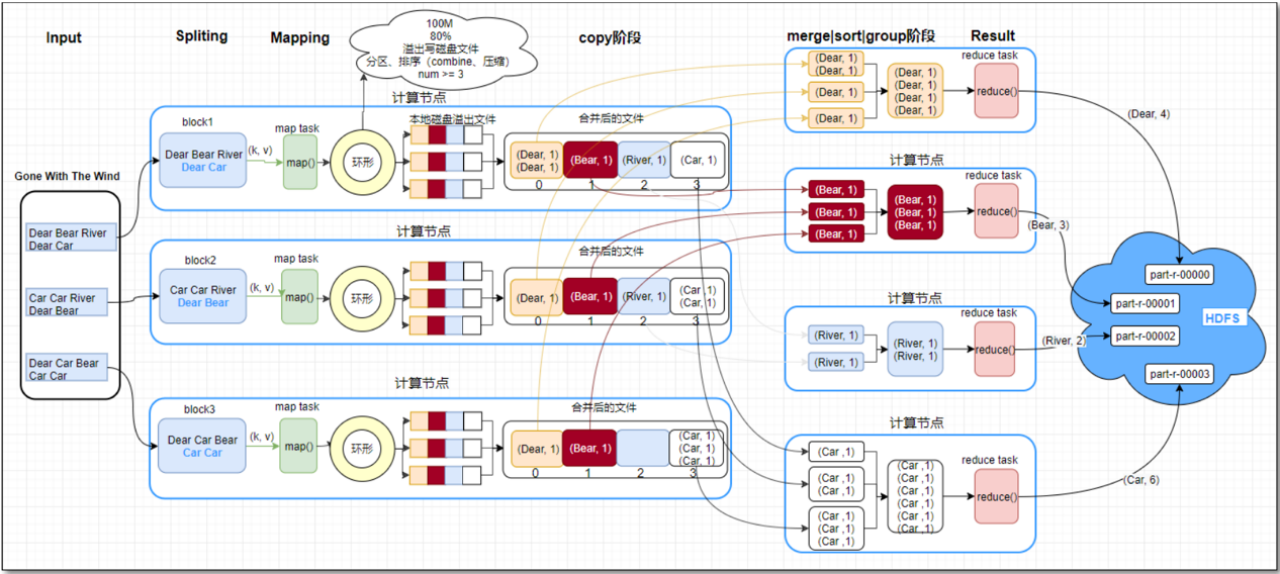
MapReduce过程
整个过程可以分为三个核心阶段:Map、Shuffle 和 Reduce。其中,Shuffle是 Maptask 到 reducetask 之间的数据交换过程,包含 Map 端的 shuffle 和 reduce 端的 shuffle。
第一阶段:Map阶段
- 首先,MapReduce框架会从HDFS读取输入文件,并将文件逻辑地切分成多个InputSplit。
- 然后,框架会为每个InputSplit分配一个Map任务。
- Map任务会读取数据,并调用我们自己编写的map函数。这个函数的核心作用是进行数据转换,处理成
<Key, Value>对。 - 这些中间结果并不会直接写入磁盘,而是先被收集到内存中的一个环形缓冲区里(一般为 100M)。
第二阶段:Shuffle阶段
Shuffle是连接Map和Reduce的桥梁,它横跨Map端和Reduce端。
-
在Map端,Shuffle的核心流程可以概括为“收集、排序溢写、最终合并”三个步骤:
-
收集(Collect):首先,
map函数的输出结果会被收集到内存中的一个环形缓冲区。在这个写入的过程中,框架会调用Partitioner为每条数据确定分区号,完成逻辑上的划分。 -
排序与溢写(Sort and Spill):当缓冲区达到阈值(例如80%)时,会启动一个后台线程进行溢写。这个线程会使用快速排序对缓冲区内的数据先按分区号升序排序,再按Key升序排序。
-
合并(Merge):由于一个Map任务可能会经历多次溢写,从而产生多个溢写文件。在Map任务最终结束前,系统会将所有这些临时的溢写文件通过归并排序(Merge Sort)的方式,合并成一个最终的、单一的、已分区且区内有序的大文件。这个文件等待着Reduce任务来拉取。
- (加分项)在这个阶段,还可以配置两个可选的优化项来提升性能。一个是Combiner,它相当于一个‘本地Reducer’,用于在Map端提前聚合数据。另一个是压缩,可以对Map的输出进行压缩。这两种方式都能有效减少Shuffle过程中磁盘和网络的I/O开销。
-
-
在Reduce端,Shuffle主要做两件事:
-
拉取(Copy):Reduce任务会主动从所有Map任务的节点上,拉取属于自己分区的那些数据文件。
-
合并 排序(Merge && Sort):它将从不同Map节点拉取来的数据,进行再次的归�并排序。这一步的目的是将来自不同Map任务、但Key相同的数据真正地聚合在一起,成为一个文件,作为 reduce 任务的输入
-
第三阶段:Reduce阶段
-
Reduce任务会接收Shuffle阶段准备好的数据。
-
然后调用我们编写的reduce函数,对同一个Key的所有Value进行聚合计算。
-
最后,将计算出的最终结果写入到HDFS中。