Combiner函数
在Hadoop中,为了减少map和reduce任务之间的数据传输,用户可以针对map任务的输出指定一个combiner函数(也称为局部聚合函数或合并函数)。combiner函数的作用是在map任务输出的局部数据中进行聚合和合并,以减少需要传输给reduce任务的数据量。
举例子说明:
假设我们有一个MapReduce任务,以上上面的单词统计案例为例:
首先,将文本划分为多个分片,每个分片由一个Mapper处理。其中map1的输出键值对可能如下:
- ("hadoop", 1)
- ("hive", 1)
- ("hive", 1)
- ("spark", 1)
- ("hadoop", 1)
- ("hive", 1)
这些键值对将被发送到Reducer1之前,可以先经过combiner函数的处理。
combiner函数接收到以下键值对:
- ("hadoop", [1,1])
- ("hive", [1,1,1])
- ("spark", [1])
combiner函数对每个key的值进行合并操作。在这个例子中,合并操作是将所有的value相加,得到每个单词出现的总次数。
经过combiner函数处理后,输出的结果变为:
- ("hadoop", 2)
- ("hive", 3)
- ("spark", 1)
最后,这些合并后的键值对将被发送到Reducer进行进一步的处理和汇总,最终得到每个单词出现的总次数。
代码演示:
具体来说,在MapReduce程序中,combiner函数是通过设置JobConf对象的setCombinerClass()方法来指定的。combiner函数的实现是在一个单独的Combiner类中完成的,这个类需要继承自Reducer类,并覆盖其reduce()方法。Combiner类和Reducer类的reduce()方法的实现可以是相同的,但是它们的作用和执行时机是不同的。
job.setCombinerClass(WordCountReduce.class);
使用上面的wordcount案例,不加combiner,观察日志输出如下:
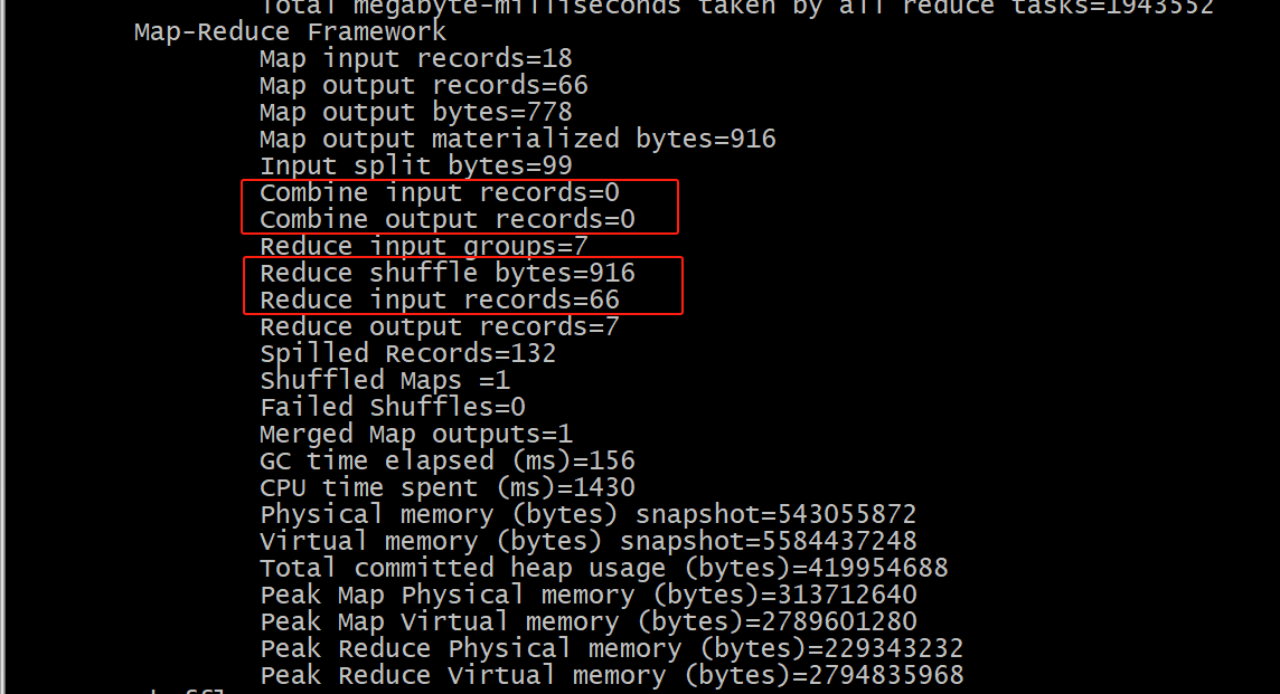
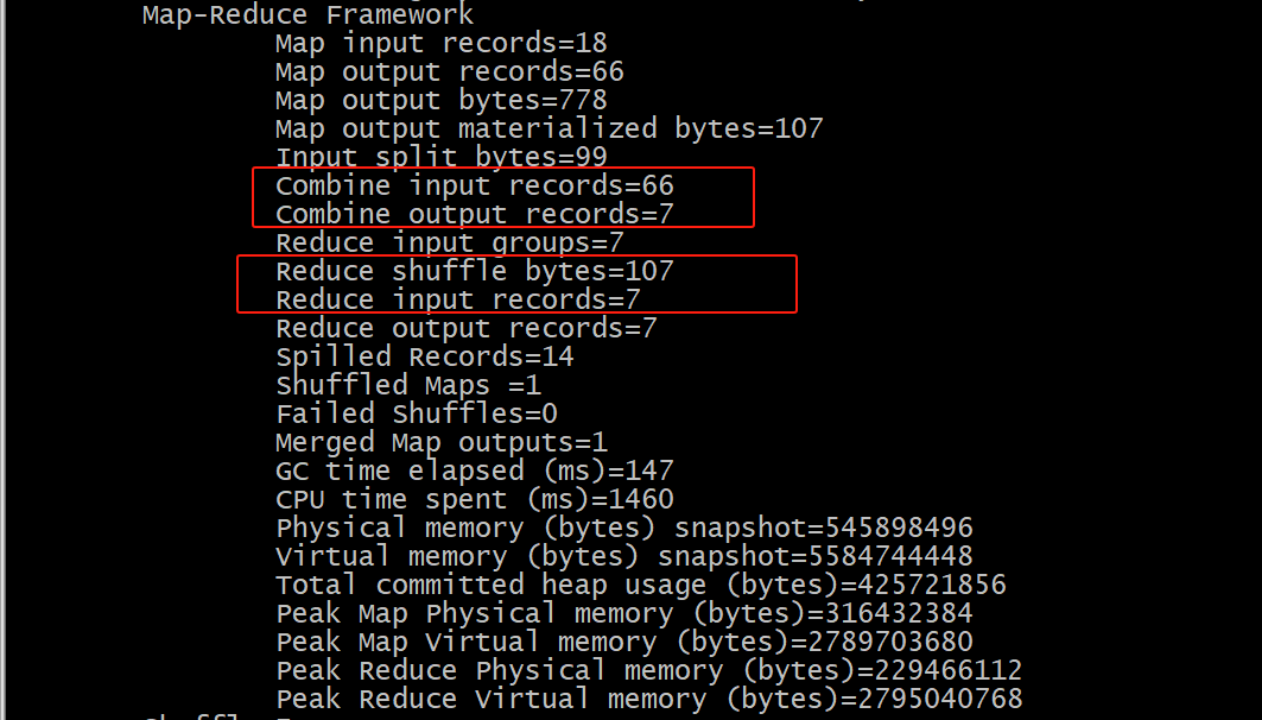
加上combiner之后,观察日志输出如下:
注意点:
有些情况下,局部合并操作可能会破坏结果的正确性。例如,在计算平均值或者中位数时,局部合并可能导致错误的结果。在这种情况下,不适合使用Combiner函数。
举个例子:
假设我们有一个MapReduce任务,统计某个省学生高考的平均成绩;
其中某两个mapper的输出可能如下:
Mapper1:
- (henan, [530, 470, 500])
Mapper2:
- (henan, [480, 590])
如果我们使用Combiner函数进行局部平均值计算,Combiner输出结果是:
- (henan, 500)
- (henan, 535)
然后在将结果交给reduce计算平均值,最终的输出结果是:
- (henan,517.5)
这个显然和真实结果((530+470+500+480+590)➗5=514)是有差距的。