数据分片(Split)⭐️⭐️
Hadoop的设计目标之一是实现高效的数据处理和负载平衡。为了达到这个目标,Hadoop将输入数据划分为等长的小数据块,称为输入分片或分片。每个分片都会被分配给一个map任务,并由该任务来处理该分片中的每条记录。
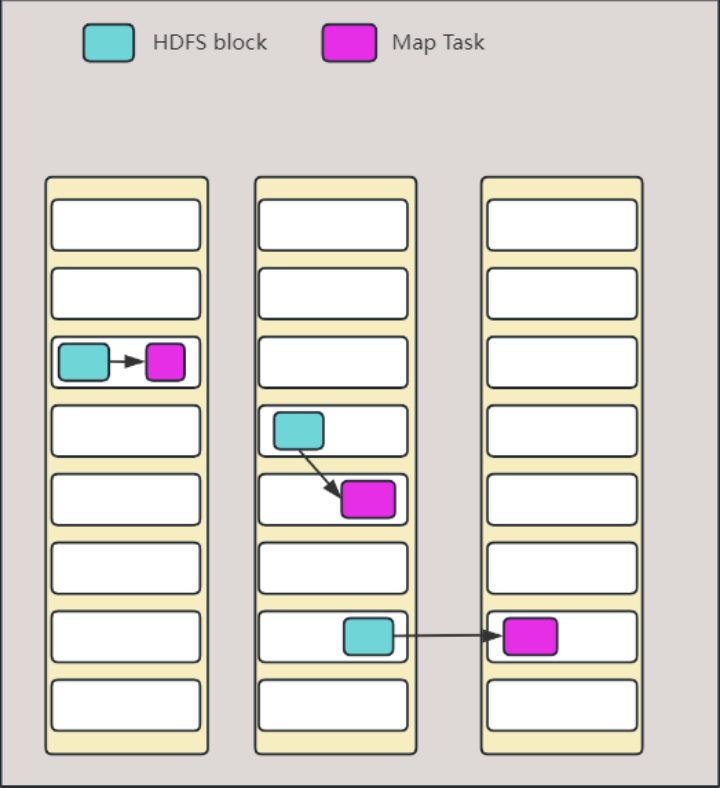
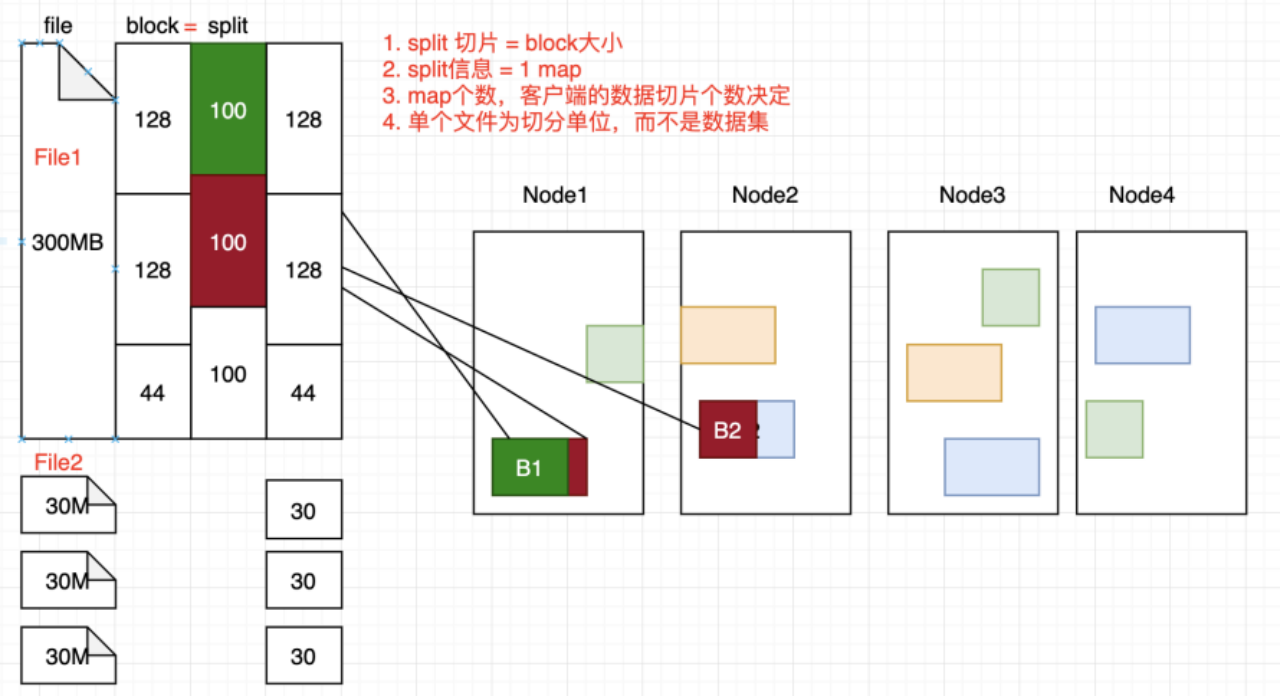
分片的作用:
- 并行处理:将输入数据划分为等长的小数据块(分片),可以实现并行处理。每个分片都会被分配给一个map任务,这些map任务可以同时运行在不同的计算节点上,以实现数据的并行处理。通过并行处理,可以提高作业的处理速度和整体性能。
- 负载平衡:拥有许多分片的好处是可以实现较好的负载平衡。较快的计算机可以处理更多的数据分片,而较慢的计算机则处理较少的数据分片,从而实现一定的负载均衡。即使在相同的机器上,失败的进程或其他并发运行的作业也可以实现满意的负载平衡。通过负载平衡,可以更充分地利用集群资源,提高作业的整体效率。
- 数据本地化优化:Hadoop会在存储有输入数据的节点上运行map任务,以实现数据本地化优化。这意味着尽可能地将map任务分配给存储有相应输入数据的节点,避免了跨网络传输数据的开销,提高了作业的执行性能。数据本地化优化可以最大程度地利用节点的计算能力,减少对集群带宽资源的需求。
分片的原理:
- 分片大小:分片的大小通常与HDFS的数据块大小相同,默认为128MB。这样做是为了最大程度地实现数据本地化优化,确保一个分片可以完全存储在一个数据块的复本中。如果一个分片跨越多个数据块,就需要进行跨网络传输数据,降低了执行效率。
- 分片划分:Hadoop会根据输入数据的大小和分片大小,将输入数据划分为多个等长的小数据块(分片)。划分的过程是逻辑上的,不涉及实际的数据移动,只是确定了每个分片的范围和位置。
- 分片调度:每个分片都会被分配给一个map任务进行处理。Hadoop的作业调度器会根据数据本地化优化原则,将map任务分配给存储有相应输入数据的节点。如果一个分片所在的节点正在运行其他map任务,调度器会尝试从存储该数据块的机架中的其他节点中找到一个空闲的map槽来运行该map任务分片。只有在非常罕见的情况下,才会使用其他机架中的节点运行该map任务,这将导致机架间的网络传输。
FileInputFormat切片机制☆
切片机制
- 简单按照文件的内容长度进行切片
- 切片大小,默认等于Block大小
切片时不考虑数据集整体,而是逐个针对每个文件进行单独的切片
TextInputFormate切片机制☆
MapReduce默认使用的切片机制。在切片时不考虑数据集整体,也就是不考虑输入路径下其他文件,而是逐个对每一个文件单独切片。
它在读取单个文件数据时是按行读取的,其用来存储读取的数据的数据结构固然是键值对,键存储的是该行在整个文件中的起始字节的偏移量,键的数据类型是LongWritable。而值是这行的内容,不包括任何的行终止符,即换行符和回车符,值的数据类型是Text。
切片过程
- 程序找到数据存储的目录
- 开始遍历��处理目录下的每个文件
- 遍历到第一个文件 f.txt
- 获取文件大小 fs.size(f.txt)
- 计算切片大小 computeSplitSize(Math.max(minSize, Math.min(maxSize,blocksize)))=blocksize=256M
- 默认切片大小=blocksize
- 开始切片, 0-256M, 256-512M (每次切片时,都要判断切完剩余部分是否大于block 的 1.1 倍, 不大于就划分为 1 块)
- 建切片信息记录到规划文件中(记录每个切片元数据:起止位置)
- 提交切片规划文件到 YARN 上, YARN 上的 MrAppMaster根据规划文件计算 mapTask 调度资源执行