数据输入输出 ⭐️
1.InputFormat数据输入
MapReduce通过InputFormat类来读取不同类型的数据。不同的InputFormat子类实现了不同的数据读取逻辑,以适应不同的数据类型和数据存储方式。
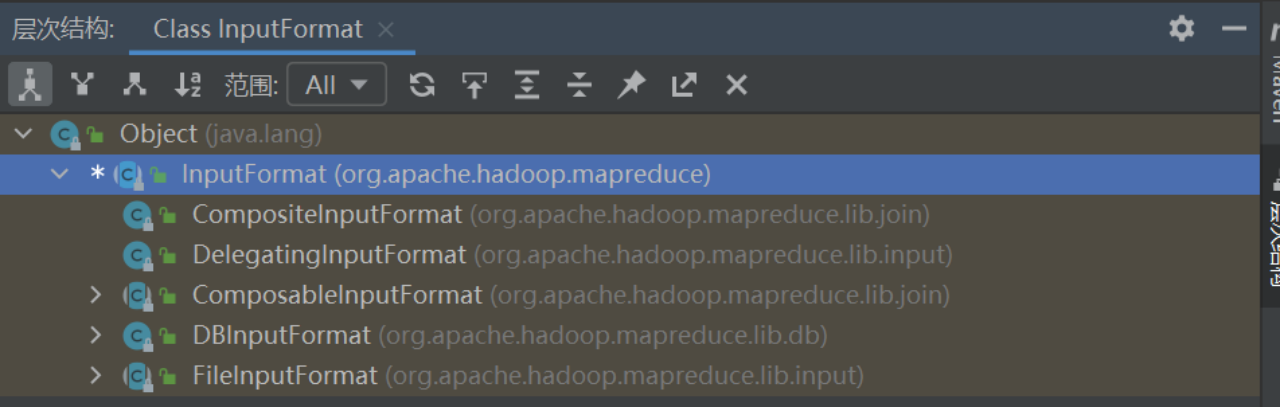
FilelnputFormat类
FileInputFormat是所有使用文件作为数据源的InputFormat实现的基类。
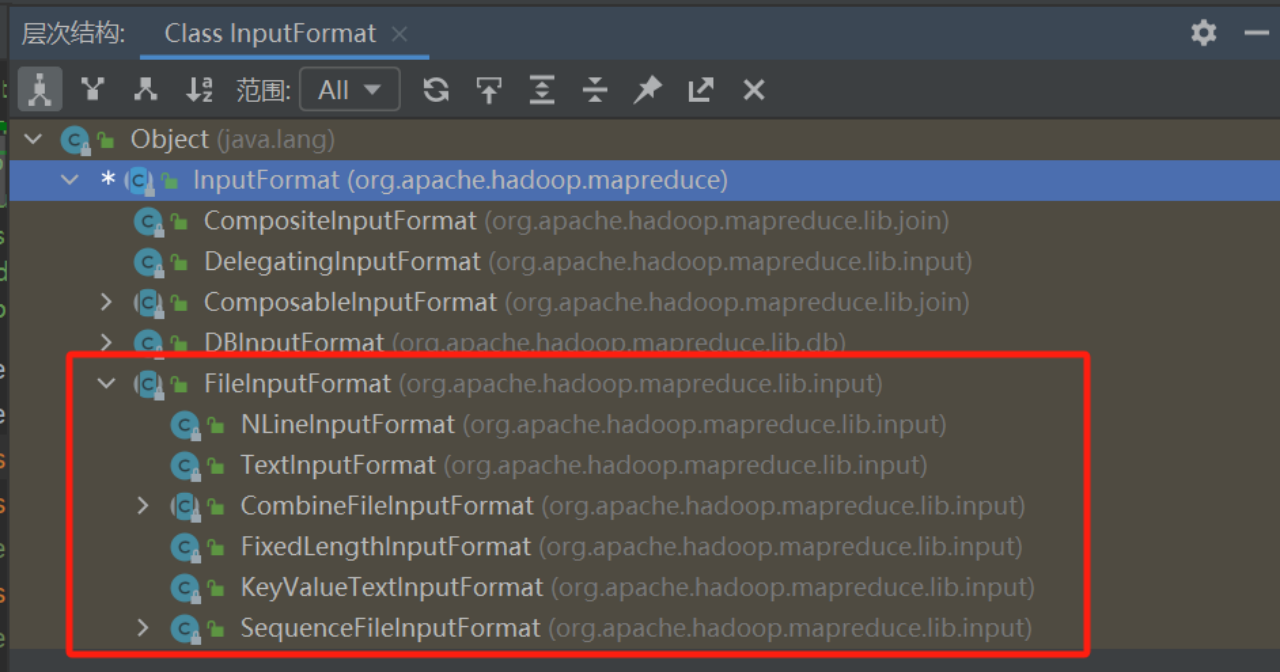
主要是下面两个功能:
- 指出作业的输入文件位置:FileInputFormat类允许指定要作为输入的文件或目录的位置,可以使用FileInputFormat.addInputPath()方法来添加输入文件或目录的路径。
- 生成输入文件分片:FileInputFormat类还负责将输入文件划分为逻辑上的输入分片。它提供了默认的划分逻辑,但也可以通过自定义InputFormat子类来实现特定的划分逻辑。
FilelnputFormat类分片原理
大多数情况下,FileInputFormat只分割大于HDFS文件块(blocksize)大小的文件,当然也可以通过下面的参数来控制。
input.fileinputformat.split.minsizeinput.fileinputformat.split.maxsizeblocksize
分片的大小由以下公式计算:
protected long computeSplitSize(long blockSize, long minSize,long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
默认的情况下:minSize < blockSize < maxSize
上面三个参数对分片的影响可以参考下表:
| minSize | maxSize | blockSize | 分片大小 | 解释说明 |
|---|---|---|---|---|
| 1(默认值) | Long.MAX_VALUE (默认值) | 128 MB(默认值) | 128 MB | 默认情况下,分片大小与blocksize大小相同。 |
| 1(默认值) | Long.MAX_VALUE (默认值) | 256 MB | 256 MB | 增加分片大小最自然的方法是增大blocksize的大小。 |
| 256 MB | Long.MAX_VALUE (默认值) | 128 MB(默认值) | 256 MB | 最小分片值大于blocksize。 |
| 1(默认值) | 64MB | 128 MB(默认值) | 64MB | 最大分片值小于blocksize。 |
分片示例:
假如在默认参数情况下,读取一个400MB的文件,文件整体的切分如下:
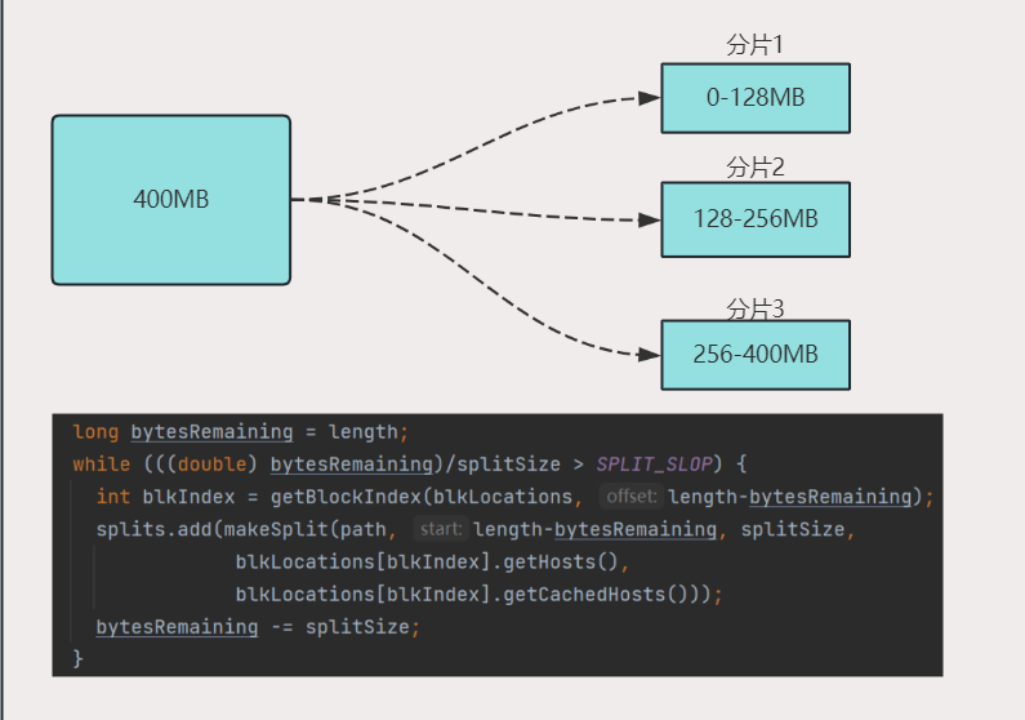
说明:从上述源码部分可知,当bytesRemaining/splitSize > 1.1不满足的话,那么最后所有剩余的会作为一个切片。从而不会形成例如129M文件规划成两个切片的局面。
TextlnputFormat
TextInputFormat是FileInputFormat的一个子类,用于读取普通文本文件。它将文本文件按行划分为输入记录,并将每行作为键值对的值传递给Map函数。
键是LongWritable类型,存储该行在整个文件中的字节偏移量。值是这行的内容,不包括任何行终止符(换行符和回车符),它被打包成一个Text对象。
下面是一个示例:
下面是被切分好的一个分片,其中包含4条数据。
Hive hadoop spark
Spark hive flink
Hive hive hello
Hadoop hive mapduce
每条记录包含为以下键值对:
(0,Hive hadoop spark)
(17,Spark hive flink)
(36,Hive hive hello)
(55,Hadoop hive mapreduce)
说明:这里的偏移量是以字节为单位的,而不是以行数为单位。因此,每行文本的偏移量取决于前面所有行文本的字符数。在上述示例中,第一行文本"Hive hadoop spark"有17个字符(包括空格),因此第二行文本的起始偏移量为17。
CombineTextInputFormat
FileInputFormat默认为每一个文件产生一个分片,一个分片需要分配一个 map 来操作处理。每次map操作都会造成额外的开销。在有大量小文件的场景下,处理数据的性能显然是很低的。
CombineFileInputFormat的设计就是应对这种场景的,可以用来将多个小文件从逻辑上划分到一个切片中,避免了多个map来处理。
这里我们以文本类型的数据处理为例,主要说明一下CombineTextInputFormat。
CombineTextInputFormat在代码中的具体配置使用;
// 因为MapReduce默认InputFormat
//需要手动设置输入格式为CombineTextInputFormat:
job.setInputFormatClass(CombineTextInputFormat.class);
//可以手动配置CombineTextInputFormat的参数:6291456(6MB)
CombineTextInputFormat.setMaxInputSplitSize(job, 6291456);
案例演示:
wordcount案例的基础上,演示使用CombineTextInputFormat前后的对比。
准备4个文件
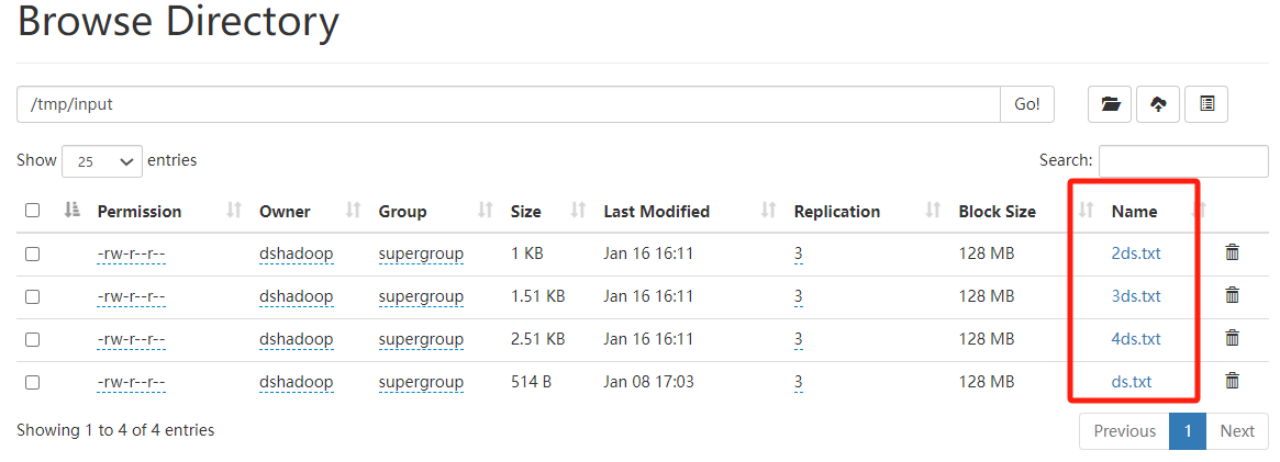
使用前:

对应的是4个map 任务
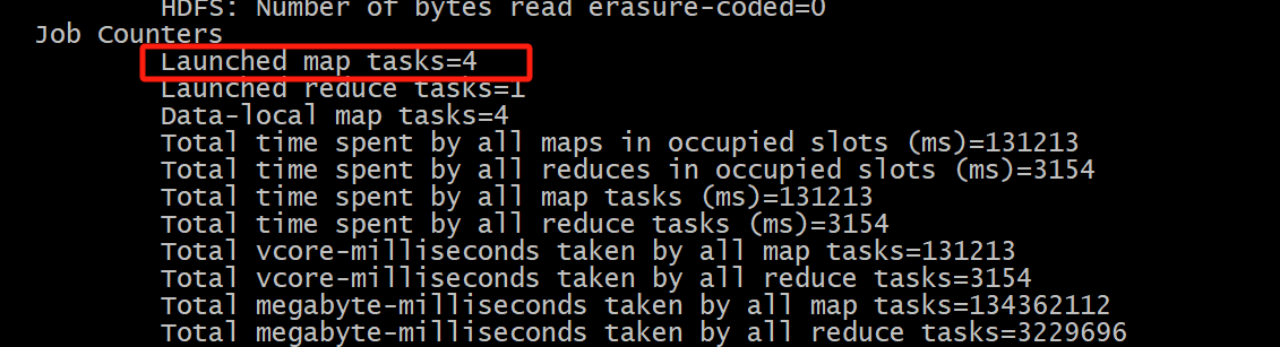
使用后:

2.OutputFormat数据输出
OutputFormat类是Hadoop MapReduce框架中用于定义输出数据的格式的抽象类。它定义了输出数据的写入方式和目标位置,并提供了一些默认的实现。
OutputFormat类的常见子类包括:
- TextOutputFormat:输出文本形式的数据,每条记录占据一行(MapReduce默认的输出格式)。
- SequenceFileOutputFormat:将数据以二进制序列文件的形式写入输出文件。SequenceFile是一种Hadoop专用的二进制文件格式,可用于高效地存储大量小型键值对数据。
- MultipleOutputs:允许将输出数据写入多个文件或目录,并根据需要为每个输出配置不同的OutputFormat。
- FileOutputFormat:FileOutputFormat是OutputFormat的基类,它定义了输出文件的路径和名称的生成方式。
案例演示:输出文件分割
基于上面的wordcount案例,使用MultipleOutputFormat将不同的单词统计的结果输出到以单词命名的不同文件中。
代码修改:
Reduce端的修改:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
// 声明MultipleOutputs对象
private MultipleOutputs<Text, IntWritable> mos;
@Override
protected void setup(Context context) {
// 初始化MultipleOutputs对象
mos = new MultipleOutputs<>(context);
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 定义变量来记录单词出现的总次数
int sum = 0;
// 遍历迭代器累加单词出现的总次数
for (IntWritable value : values) {
int count = value.get();
sum += count;
}
// 输出单词和对应的总次数到不同的文件中
mos.write("wordcount", key, new IntWritable(sum), key.toString());
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
// 关闭MultipleOutputs对象
mos.close();
}
}
核心代码解释
使用MultipleOutputs类来进行输出操作。在setup方法中,初始化了一个MultipleOutputs对象,该对象可以用于将数据输出到不同的文件中。
n在reduce方法中,遍历values迭代器,累加单词出现的总次数。
n使用MultipleOutputs的write方法将单词和对应的�总次数输出到不同的文件中。输出的文件名使用了单词本身,这样可以将每个单词的统计结果分别存储到以单词命名的文件中。
在cleanup方法中,关闭MultipleOutputs对象,释放资源
Driver端的修改:(WordCountDriver类的main方法中新增下面代码)
MultipleOutputs.addNamedOutput(job, "wordcount", TextOutputFormat.class, Text.class, IntWritable.class);
输出结果:

